







 本文深入探讨了时间序列分析,包括加法和乘法模型的介绍,时间序列的模式分解,以及如何处理平稳性和非平稳序列。文章强调了平稳序列在预测中的重要性,并提供了检验时间序列平稳性的方法,如ADF和KPSS测试。此外,还讨论了去趋势和季节性调整,以及处理缺失值和白噪声的策略。
本文深入探讨了时间序列分析,包括加法和乘法模型的介绍,时间序列的模式分解,以及如何处理平稳性和非平稳序列。文章强调了平稳序列在预测中的重要性,并提供了检验时间序列平稳性的方法,如ADF和KPSS测试。此外,还讨论了去趋势和季节性调整,以及处理缺失值和白噪声的策略。
1. 时间序列模型(加法模型和乘法模型)
基于原始的时间序列的趋势项和季节项,时间序列模型可以被分为加法模型和乘法模型.
- 乘法型:时间序列值 = 趋势项 * 季节项 * 误差项。
- 加法型:时间序列值 = 趋势项 + 季节项 + 误差项。
2. 时间序列的模式分解
对时间序列的分解,可以从趋势项、季节项、 误差项的乘法和加法的角度进行。
****代码方面,我们使用statsmodels包的seasonal_decompose函数。
# 导入包
from statsmodels.tsa.seasonal import seasonal_decompose
from dateutil.parser import parse
# 导入数据
df = pd.read_csv("../datasets/a10.csv", parse_dates=['date'], index_col=['date'])
# 乘法模型
result_mul = seasonal_decompose(df['value'], model="multilicative", extrapolate_trend='freq')
result_add = seasonal_decompose(df['value'], model="additive", extrapolate_trend='freq')
# 画图
fig, ax = plt.subplots(ncols=2, nrows=4, figsize=(12, 5), sharex=True)
def plot_decompose(result, ax, index, title, fontdict=font):
ax[0, index].set_title(title, fontdict=fontdict)
result.observed.plot(ax=ax[0, index])
ax[0, index].set_ylabel("Observed")
result.trend.plot(ax=ax[1, index])
ax[1, index].set_ylabel("Trend")
result.seasonal.plot(ax=ax[2, index])
ax[2, index].set_ylabel("Seasonal")
result.resid.plot(ax=ax[3, index])
ax[3, index].set_ylabel("Resid")
plot_decompose(result=result_add, ax=ax, index=0, title="Additive Decompose", fontdict=font)
plot_decompose(result=result_mul, ax=ax, index=1, title="Multiplicative Decompose", fontdict=font)
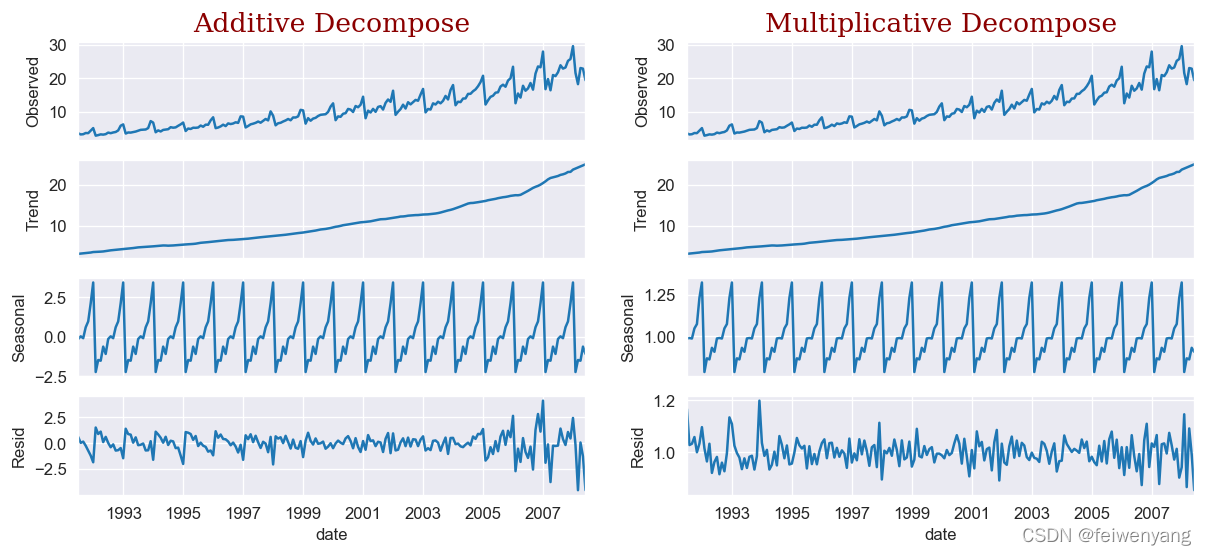
- 在上面的代码中,设置
extrapolate_trend='freq'是为了填充 季节项、误差项中开头的缺失值。 - 在上图中,可以发现加法模型里面的误差项还有一部分时间序列的模式没有被提取完。但是乘法模型的误差项(或者叫残差项)基本上看不出来任何信息了,说明乘法模型对这个数据来说,有更强提取数据信息的能力。
- 乘法模型的季节项、趋势项、误差项数据都保存在
result_mul里面。我们将这几个数据提取出来。
df_reconstructed = pd.concat([result_mul.seasonal, result_mul.trend, result_mul.resid, result_mul.observed], axis=1)
df_reconstructed.columns = ['Seasonal', 'Trend', 'Resid', 'Actual_value']
df_reconstructed.head()
Seasonal Trend Resid Actual_value
date
1991-07-01 0.987845 3.060085 1.166629 3.526591
1991-08-01 0.990481 3.124765 1.027745 3.180891
1991-09-01 0.987476 3.189445 1.032615 3.252221
1991-10-01 1.048329 3.254125 1.058513 3.611003
1991-11-01 1.074527 3.318805 0.999923 3.56586
可以检查一下上面的数据;基本上可以确定df_reconstructed['Seasonal'] * df_reconstructed['Trend'] * df_reconstructed['Resid'] = df_reconstructed['Actual_value'],
或者我们用均方误差算一下:
value = np.sqrt(np.sum((df_reconstructed['Seasonal'] * df_reconstructed['Trend'] * df_reconstructed['Resid'] -
df_reconstructed['Actual_value']) ** 2))
value
1.6395253991751996e-14
3.平稳序列和非平稳时间序列
- 平稳性是时间序列的一个属性,一个平稳的时间序列指的是这个时间序列和时间无关,也就是说这个时间序列不是时间的一个函数。
- 也就是说一个时间序列是平稳的,就是这个时间序列的几个统计量:均值、方差、自相关系数都是一个常数,和时间无关。
9. 如何让一个时间序列平稳
- 对一个时间序列做一次或者多次差分。
- 季节性延迟(或者叫多阶差分)。
- 取时间序列的第N个根。
- 上面三种方法混合使用。
最方便最常用的平稳一个时间序列,就是多次使用一阶差分,直到时间序列平稳。
10.在做预测之前为什么需要对非平稳时间序列做平稳(重点)
- 预测一个平稳的时间序列相对容易,且结果更加可靠。
- 一个更加重要的原因是:自回归预测模型本质上是一个线性回归模型,它利用时间序列的滞后项做为预测变量。
我们都知道,在线性回归里面,如果预测变量的X都是互不相关的,那么线性回归预测的效果最好。因此对序列进行平稳化就解决了变量之间的相关性问题,
从而消除来时间序列的自相关,使得预测模型中的预测变量几乎相互独立。
现在已经知道的时间序列的平稳性的重要性,如何判断一个时间序列是否平稳呢?
11. 检验时间序列是否平稳
检验时间序列是否为平稳性时间序列可以有这几种方法:
- 查看时间序列的时序图;
- 将时间序列分为2个或者多个连续片段,然后计算对应的统计量(比如均值、方差、自相关系数等),如果片段的统计量都是明显不相等的话,说明肯定不是平稳性。
- 不管怎么样,需要使用一个量化的指标去衡量一个时间序列是否平稳,可以使用单位根检验方法来对时间序列做平稳性检验,检验时间序列是否平稳并且具有单位根。
还有很多单位根检验方法的增强版本:
- Augmented Dickey Fuller test(ADH Test)
- Kwiatkowski-Phillips-Schmidt-Shin – KPSS test (trend stationary)
- Philips Perron test (PP Test)
最广泛使用的方法是ADF test;原假设是时间序列有单位根并且是非平稳的。如果ADF test的P-value小于显著水平(0.05),就可以拒绝原假设。
KPSS test和ADH test恰恰相反,是为了证明时间序列有一个确定的趋势。
################################平稳性的检测##################################
from statsmodels.tsa.stattools import adfuller, kpss
df = pd.read_csv("a10.csv", parse_dates=['date'])
# ADF test
result = adfuller(df.value.values, autolag='AIC')
print('*' * 50)
print(f"ADF Statistic: {
result[0]}; p-value: {
result[1]}")
for key, value in result[4].items():
print('Crital Values:')
print(f"{
key}, {
value} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









