







数据清理的方法:
针对空缺值:保持空缺或者用最有可能的值补充 ( 平均值,回归预测的值等等 )
针对噪声数据:
1 分箱:用箱中数据的平均值代替箱中的每一个数据。分箱也是一种数据平滑技术和数据离散化技术
2 聚类:通过聚类来检测孤立点 (outlier)
3 计算机和人工检查结合:
4 回归:
针对不一致数据:修改
数据集成:
1 实体:即识别真实世界中的实体的问题,比如 customer_id 和另一张表中的 cust_number 实际上是同一实体。可通过查看元数据来查清。
2 冗余:通过对两个属性进行相关分析来检测,度量属性 A 在多大程度上能够蕴含属性 B 。若 rA , B 为 0 ,说明属性 A 与属性 B 相关性为 0 。
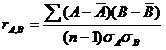
数据变换:
平滑 (smoothing) :可使用的技术包括分箱,聚类和回归
聚集 (aggregation) :
数据概化 (generalization) :用高层次概念替换低层次概念,如用 city 替换 street
规范化 (normalization) :将数据按比例缩放,使之落入一个特定区间,如 [-1,1].
最小最大规范化 (Min-max normalization) :
z-score 规范化 (z-score normalization) :

属性构造 (attribute construction) :
数据归约 data reduction
1 数据立方体聚集:汇总数据
2 维归约:删掉不相关,弱相关,或者冗余的维度
3 数据归约:小波变换,主成分分析
4 数值归约:
4.1 有参方法:使用一个模型来评估数据,只存放参数。
模型可以是:回归分析,对数线性模型
4.2 无参方法:直方图,聚类,选择 ( 选择有代表性的数据,类似统计的抽样调查 )
5 离散化和概念分层:将连续属性值进行离散化。
5.1 分箱
5.2 直方图
5.3 聚类
5.4 基于熵的离散化
5.5 自然划分分段: 3-4-5 规则















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









