







详情请点击下方:
2024年临床预测模型培训班6.29-30,无代码构建预测模型
列线图(Aligmment Diagram),又称诺莫图(Nomogram图),用来把多因素回归分析结果(logistic回归和cox回归)用图形方式表现出来,将多个预测指标进行整合,然后采用带有刻度的线段,按照一定的比例绘制在同一平面上,从而用以表达预测模型中各个变量之间的相互关系。
目前,比较传统绘制列线图的方法,还是使用R语言,但是对代码小白来说还是有点困难的,从数据拆分——建模——绘图,需要逐步修改代码参数,较为费心费力。
|
|
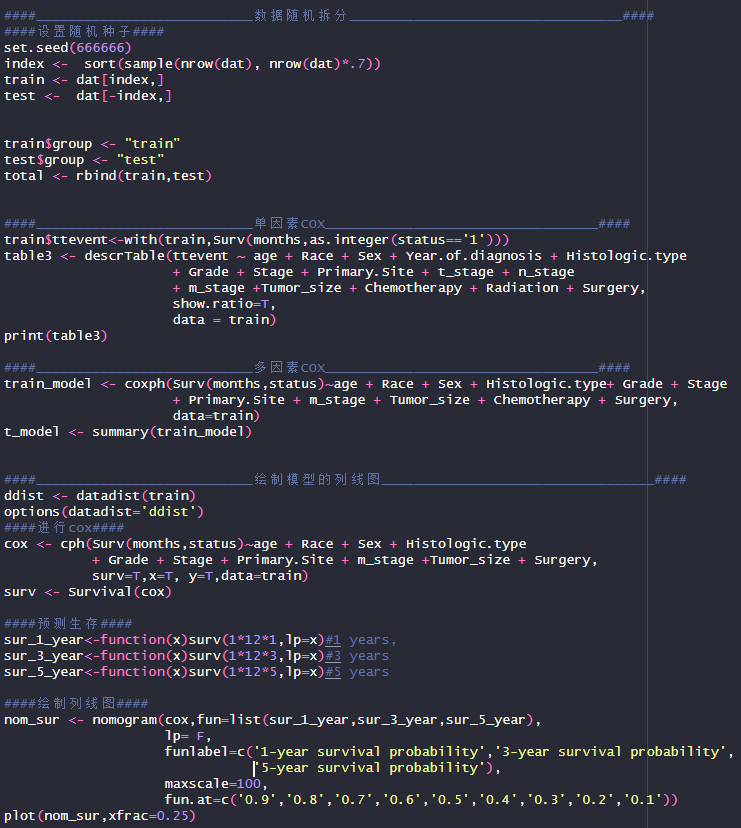
因此,这里为大家推荐一个统计分析小工具——风暴统计,可以超快速完成COX回归构建列线图的制作!还可以添加多个时间点的预测概率!
风暴统计是由浙江中医药大学的郑卫军教授基于R语言开发的,不仅结果准确性有保障,并且全部实现菜单化操作,统计小白也可以轻松上手,绘制精美的列线图!
下面我们就结合一份实操数据来为大家详细介绍一下具体的操作步骤吧!
百度、必应Bing搜索“风暴统计”
本平台上线的所有工具都是免费的

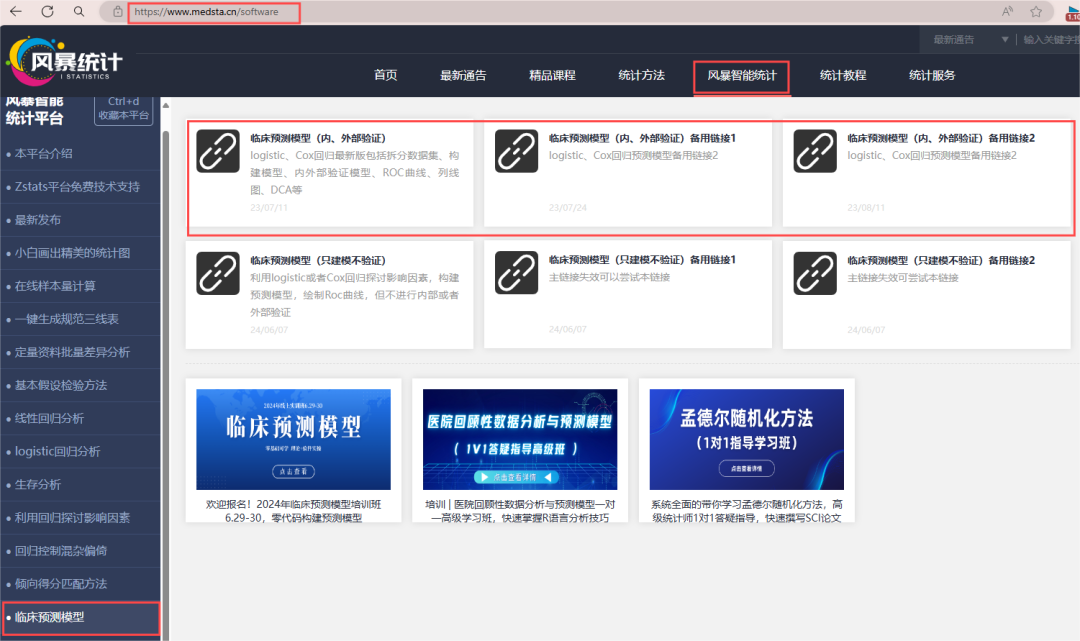
1、进入风暴统计平台
首先,浏览器搜索风暴统计,依次点击"风暴智能统计"——"临床预测模型"!平台有"内、外部验证"版及“只建模不验证”版。
通常构建预测模型都需要对模型进行验证,内部验证是必须的,条件允许情况下,进行外部验证也是很好的,因此,构建预测模型研究中,推荐大家使用"内、外部验证"版。
"只建模不验证"版更多用在影响因素研究中,可以绘制ROC曲线进行探索分析,或者计算约登指数。
进入分析界面后,根据提示,完成数据的导入与整理。这里我们不再赘述数据的导入与整理过程,详细教程大家可以点击下方链接:
2、数据集拆分
预测模型都需要内部验证,内部验证的方法有随机拆分、交叉验证、Boostrap等。但风暴统计平台目前仅能做随机拆分法内部验证。
随机拆分法内部验证,顾名思义就是将原始数据集按照7:3(常见)或者6:4等比例进行拆分,一部分用于建模,另外一部分用于验证模型。
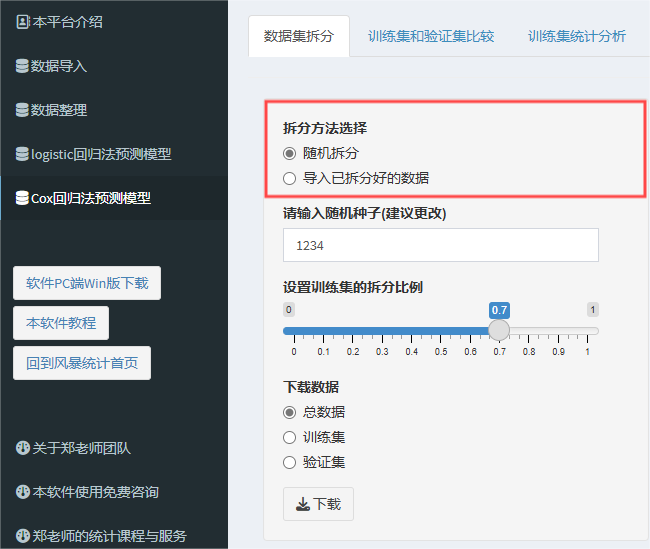
风暴统计支持两种拆分方式:随机拆分法、导入已拆分好的数据。
-
如果选择“随机拆分”,需要设置随机种子和拆分比例。随机种子对于数字位数没有要求,作用是可以保证拆分数据的分析结果可以复现,平台默认是1234,拆分比例更好理解,只需要拖动滑条,蓝色部分就是训练集的数据占总数据的比例。
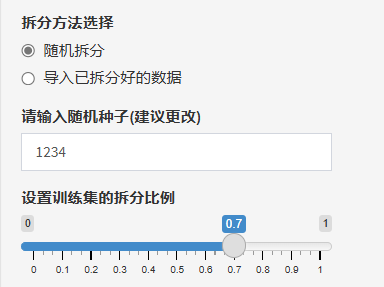
-
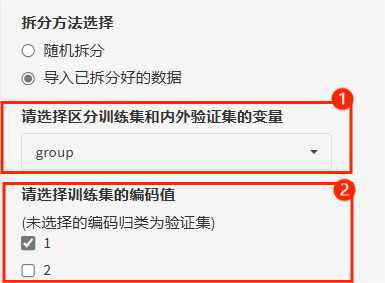
如果选择“导入已拆分好的数据”,需要设置事先在导入的数据集中增加一列用于区分训练集和验证集的变量,比如新增列叫"group",通过编码赋值1代表训练集,2代表验证集。那么第一步:选入区分训练集与验证集的变量,第二步:勾选代表训练集的编码值!
注:“导入已拆分好的数据”不仅可以做内部验证,更重要还可以用来做外部验证哦!同样需要一列变量来区分训练集和外部验证集!
这里,我们额外介绍一下随机种子,随机种子的目的是为了保证分析结果可复现,因为数据的拆分具有随机性,在R语言分析中,如果不设置随机种子,那么每次拆分产生的训练集与验证集就不一样,分析结果也会不一样。
平台设有默认随机种子1234,如果不修改,每次分析结果是一样的。此外,对随机种子没有特别要求,任意几位数字都可以。
3、构建预测模型
完成数据记得拆分后,我们就可以开始构建预测模型啦!请注意,预测模型的构建仅在训练集开展哦!
预测模型的本质,简单来说,也就是多因素回归模型!多因素回归听上去是不是平易近人许多?风暴统计可以超快速完成这一步!
首先,选择模型变量——生存结局变量、生存时间变量、自变量。结局变量必须是以0和1赋值的二分类变量哦!生存时间变量也就是我们的随访时间,应该是定量连续数据,自变量就可以放入我们数据中所有可能的预测因子!
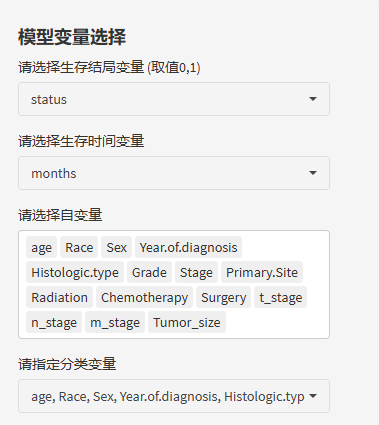
然后,平台超快速就给出了批量单因素分析的结果!
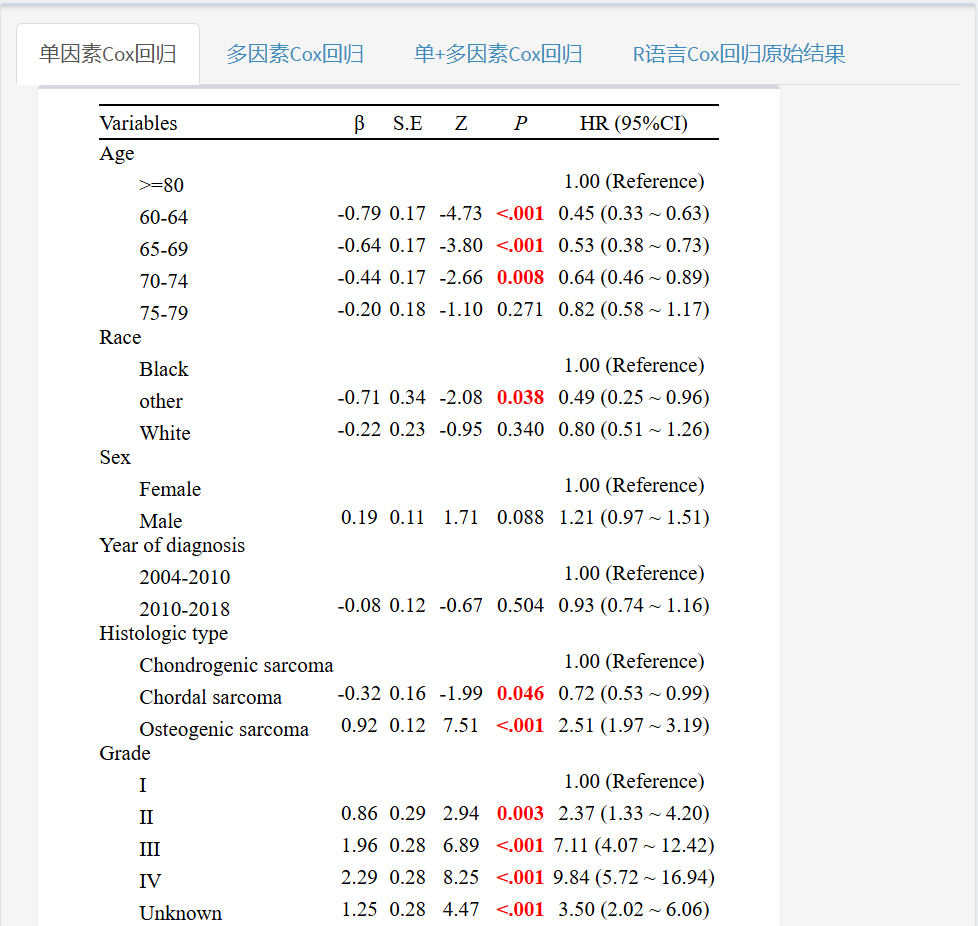
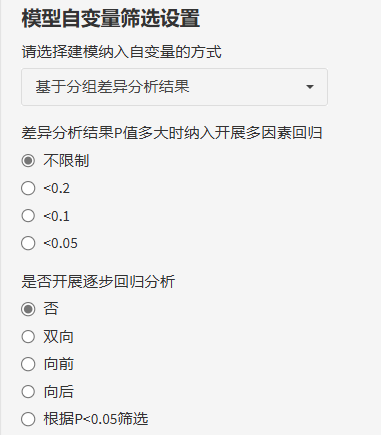
接着,定义模型自变量筛选的方式,满足筛选条件的自变量会进入多因素回归模型!
注:多因素模型中的所有变量就是我们最终预测模型中全部的预测因子了,并不只是多因素中有意义的变量哦!如果希望预测模型中的变量P值均小于0.05,可以选择逐步回归分析中"根据P<0.05筛选"的选项!
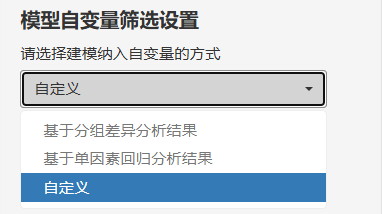
自变量筛选方式也有3种:
-
基于分组差异性结果:
-
基于单因素回归结果
-
自定义
前两个比较相似,区别就在是根据差异性P值还是单因素P值进行筛选!
如果选择了"基于分组差异性"或"基于单因素回归",只需要完成2步设置。
第一步,P阈值的选择,如果自变量个数过少,可以适当放宽标准,0.1、0.2也都是可以的。当选择不限制时,单因素的全部自变量都将纳入多因素回归分析。
第二步,是否开展逐步回归,选择“否”,就是我们常见的先单后多分析,另外逐步回归方法,平台也提供了多种选择:双向逐步回归,向前逐步回归,向后逐步回归以及考虑到有时P值大于0.05的变量在逐步回归时也会留在模型中,新增了根据P<0.05的原则开展逐步回归!大家可以根据研究需要自行选择。
 |
|

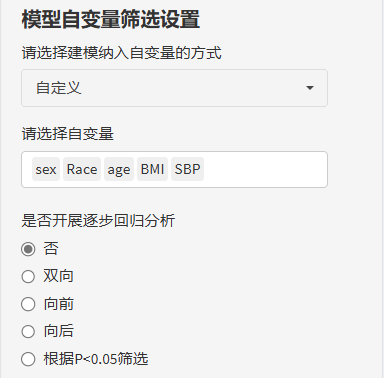
如果选择了自定义筛选自变量,比如实际研究中,预测因子的筛选也需要结合专业知识以及相关文献进行判断,纯数据驱动也不太好。假如变量A在临床中是十分重要的变量,但是可能受限于样本或其他原因,单因素与差异性均没有统计学意义,这时候,我们可以自定义挑选预测因子,选择我们预期的预测因子,自行选择是否需要逐步回归!也是一条途径!
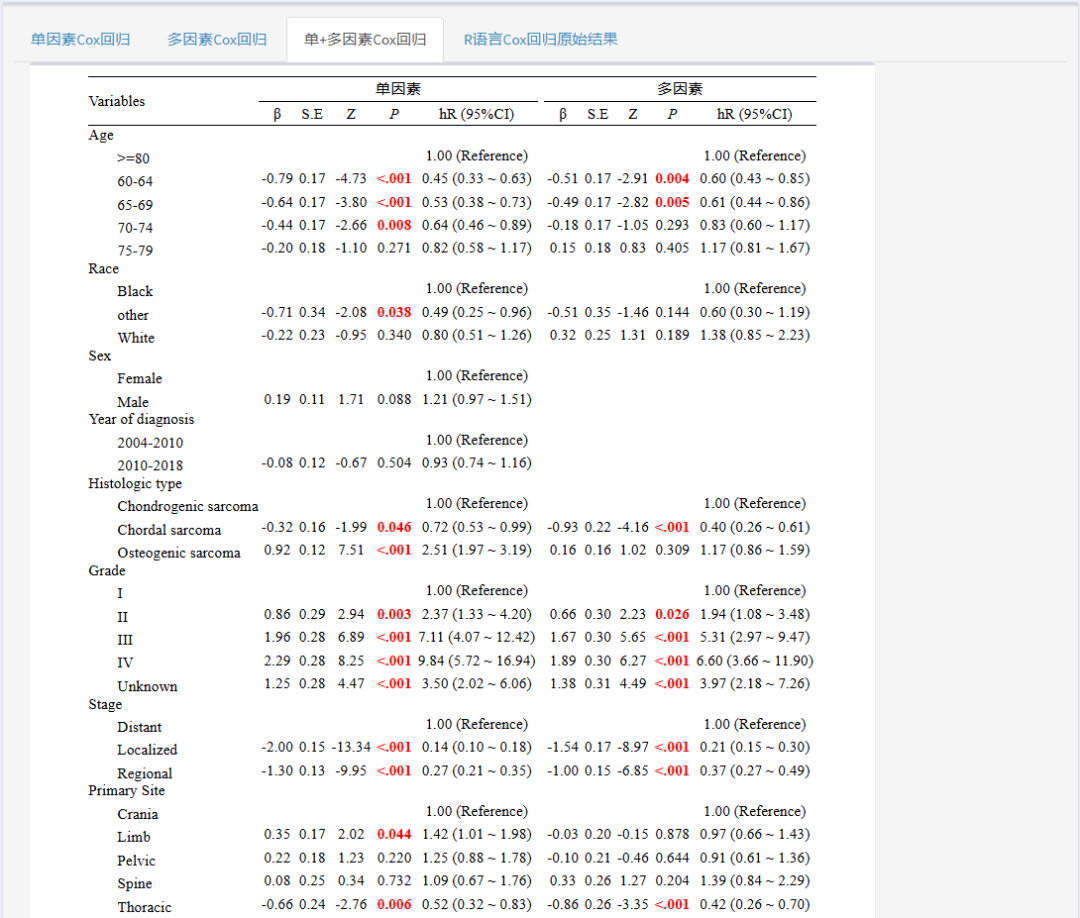
选择完毕后,我们就得到了多因素回归的结果,现在多因素模型也就是我们最终的预测模型,列线图中会包含多因素回归中的全部变量(无论多因素回归中是否有意义)!
进入“模型呈现、评价与验证“部分,就会出现我们最终的列线图啦!受浏览器展示的影响,在线展示版可能略显拥挤,后面针对这样的情况会再教大家具体处理方法。
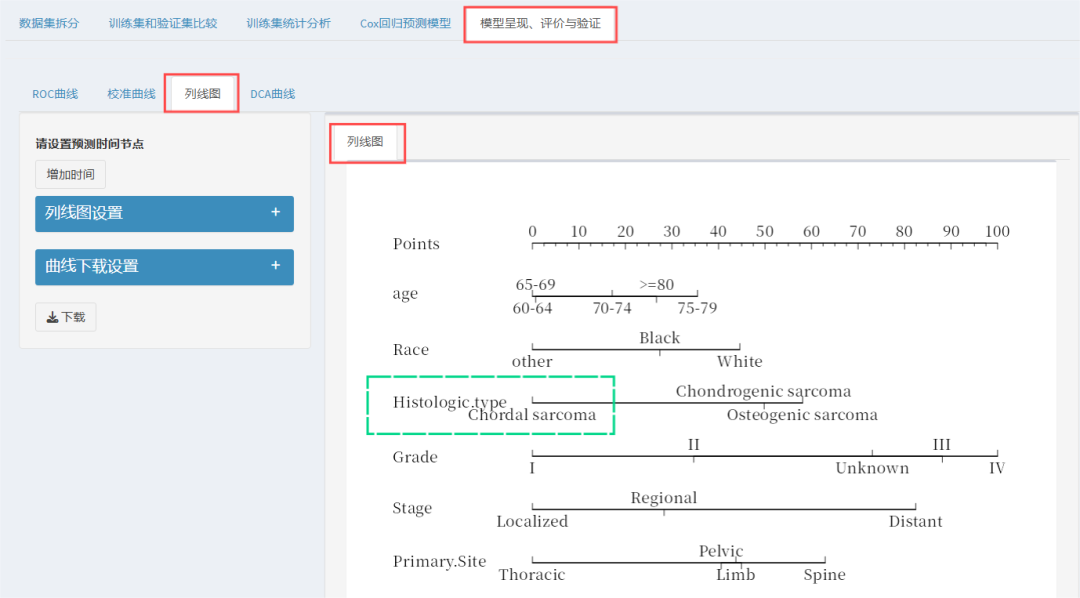
还可以增加特定时间点的预测概率,最多可以增加3个时间节点!这里的时间必须包含在有效随访时间内(时间点选取不合理,平台分析不出结果的哦),此外,标题只能是英文格式!
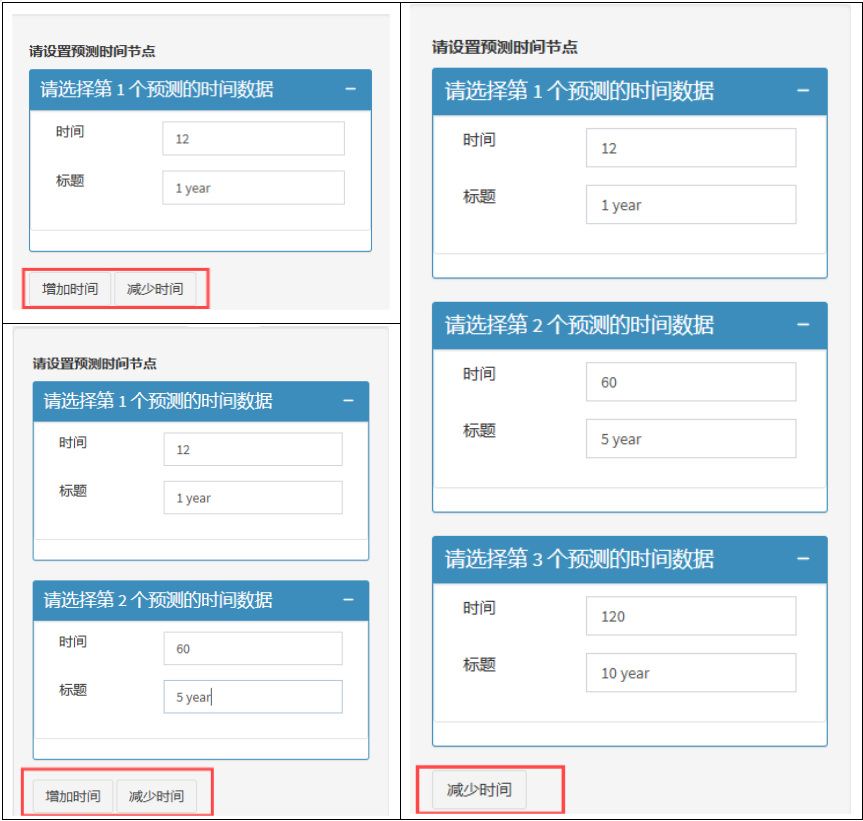

最重要的是,平台将R语言众多的细节参数设置全部转为了菜单式操作,像是刻度、变量值、变量、图全部支持自定义!

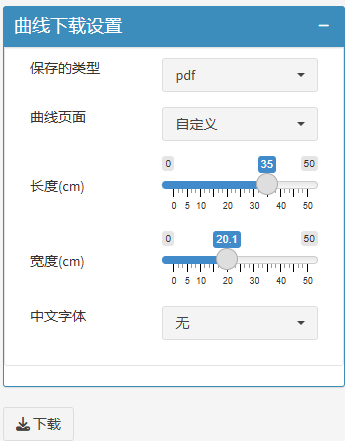
4、下载结果
最后在曲线下载设置中,选择图片保存类型,曲线页面(A4或自定义)。
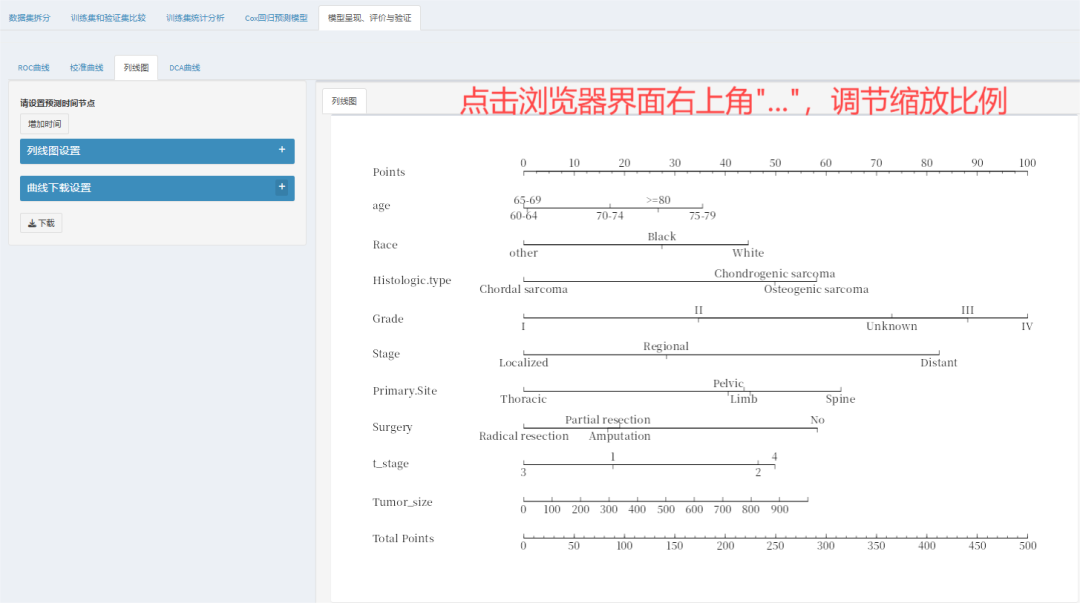
最后,当预测因子比较多,或者浏览器界面放大比例的情况,可能图片会出现文字线条拥挤的情况,请不要着急!这里教你万能解决办法!
①界面展示调节:在浏览器界面调节缩放比例,可以使风暴统计界面的图片展示比较舒展适宜
②双管齐下:“列线图设置”中调整“行间距”+"曲线下载设置"中调整页面大小!
调整完成后,我们下载的图片就十分美观啦!如果需要编辑文字为中文,或修改变量标签,建议下载pdf,二次编辑后再另存为图片就好!
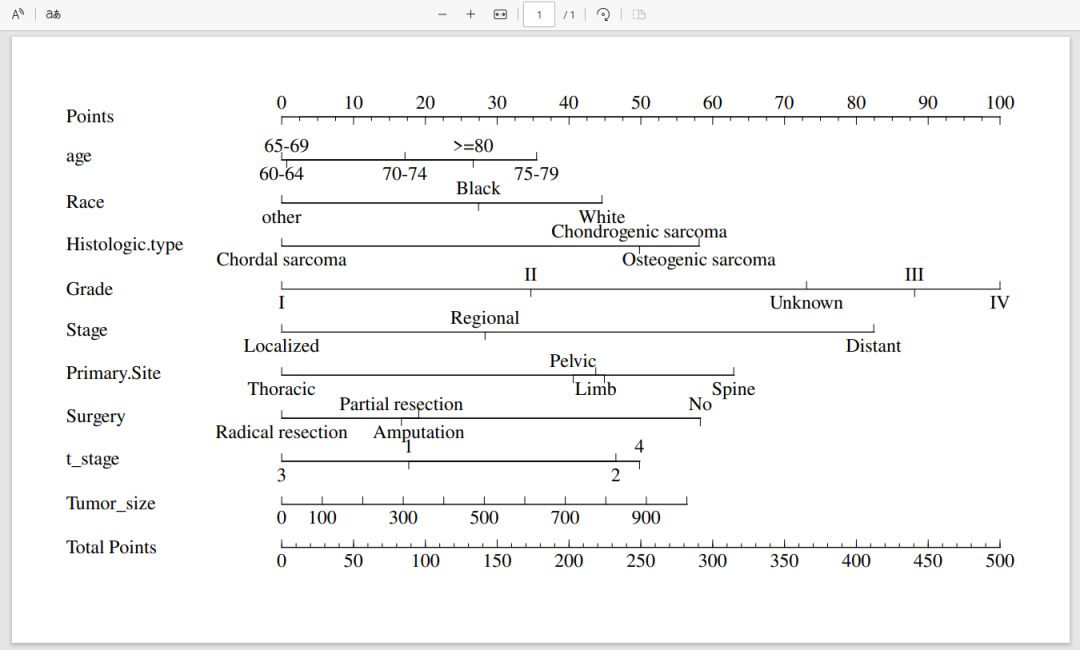
以上就是风暴统计平台绘制COX回归列线图的全部操作流程啦!如果您在使用过程中出现报错,可以参考下方推文,排查一下问题所在哦!















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









