







ovs中,如果一个port下有多个接口,则称为bond,用来提供冗余和提高性能。
bond配置
在ovsdb定义中可查看bond相关的配置

image.png
bond_mode支持三种:
active-backup: 主备模式,只有active slave工作,其他slave作为backup,active slave down后,backup slave变成active继续工作。
balance-slb: 基于源mac和出方向vlan做hash,计算出端口。
balance-tcp: 只在lacp协议下生效,可以基于l2,l3和l4做hash,比如目的mac,ip地址和tcp端口号。如果lacp协商失败,并且other-config:lacp-fallback-ab为true,则会切换到active-backup模式。
实验
实验拓扑如下
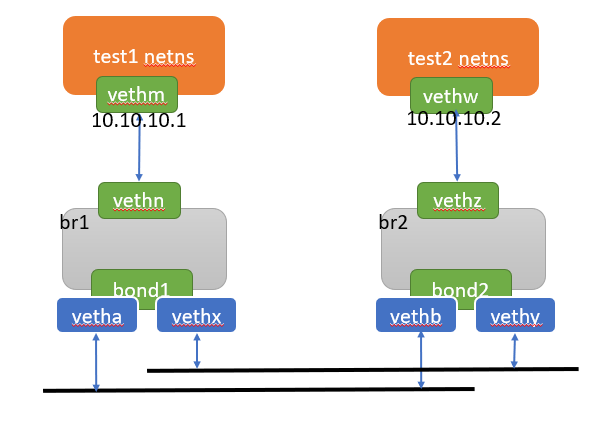
image.png
执行如下命令,创建出上面的拓扑
#创建两对veth口
ip link add vetha type veth peer name vethb
ip link add vethx type veth peer name vethy
ip link set dev vetha up
ip link set dev vethb up
ip link set dev vethx up
ip link set dev vethy up
#创建两个bridge
ovs-vsctl add-br br1
ovs-vsctl add-br br2
#在两个bridge上,分别创建bond口,其slave口为两对veth口的一端
ovs-vsctl add-bond br1 bond1 vetha vethx
ovs-vsctl add-bond br2 bond2 vethb vethy
#删除bond口。添加bond时,可用add-bond命令,但是删除bond口,没有del-bond命令可用,可使用 del-port 删除bond口
ovs-vsctl del-port bond1
#再创建两对veth口
ip link add vethm type veth peer name vethn
ip link add vethw type veth peer name vethz
ip link set dev vethm up
ip link set dev vethn up
ip link set dev vethw up
ip link set dev vethz up
#两对veth口的一端加入两个bridge
ovs-vsctl add-port br1 vethn
ovs-vsctl add-port br2 vethz
#创建两个netns
ip netns add test1
ip netns add test2
#将两对veth口的另一端加入netns
ip link set dev vethm netns test1
ip link set dev vethw netns test2
#在netns中,将veth口up起来,并配置同网段的ip
ip netns exec test1 ip link set dev vethm up
ip netns exec test1 ip addr add dev vethm 10.10.10.1/24
ip netns exec test2 ip link set dev vethw up
ip netns exec test2 ip addr add dev vethw 10.10.10.2/24
在test1 netns ping test2 netns,能ping通,说明配置是没问题的
root@master:~# ip netns exec test1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
49: vethm@if48: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 72:af:9d:1b:40:bb brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.1/24 scope global vethm
valid_lft forever preferred_lft forever
inet6 fe80::70af:9dff:fe1b:40bb/64 scope link
valid_lft forever preferred_lft forever
root@master:~# ip netns exec test1 ping 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.113 ms
^C
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.113/0.113/0.113/0.000 ms
看一下当前ovs的配置,在配置层可看到非bond口只有一个interface,bond口有多个interface,但是openflow层和datapath层都只显示interface,不会显示port。
#在配置层可看到非bond口只有一个interface,bond口有多个interface
root@master:~# ovs-vsctl show
163a03bf-8b1b-4043-8d37-8b2287bf94fe
Bridge "br1"
Port "bond1"
Interface vetha
Interface vethx
Port "br1"
Interface "br1"
type: internal
Port vethn
Interface vethn
Bridge "br2"
Port "bond2"
Interface vethb
Interface vethy
Port vethz
Interface vethz
Port "br2"
Interface "br2"
type: internal
#openflow层只显示interface,不会显示port。
root@master:~# ovs-ofctl show br1
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000baae9ee6ba4b
n_tables:254, n_buffers:0
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(vetha): addr:da:62:a2:ec:13:ad
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
2(vethx): addr:8a:56:d7:03:9e:8a
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
3(vethn): addr:3e:09:a2:3a:69:40
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
LOCAL(br1): addr:ba:ae:9e:e6:ba:4b
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
#datapath层也只显示interface,不会显示port。
root@master:~# ovs-appctl dpctl/show
system@ovs-system:
lookups: hit:92 missed:142 lost:0
flows: 0
masks: hit:324 total:0 hit/pkt:1.38
port 0: ovs-system (internal)
port 1: br1 (internal)
port 2: br2 (internal)
port 3: vetha
port 4: vethx
port 5: vethb
port 6: vethy
port 7: vethn
port 8: vethz
看一下bond口配置,bond_mode默认为 active-backup
root@master:~# ovs-appctl bond/show
---- bond2 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: 9a:8d:2d:62:ab:24(vethy)
slave vethb: enabled
may_enable: true
slave vethy: enabled
active slave
may_enable: true
---- bond1 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: 8a:56:d7:03:9e:8a(vethx)
slave vetha: enabled
may_enable: true
slave vethx: enabled
active slave
may_enable: true
从上面bond/show结果可知,对于bond1来说,active slave是vethx,现在尝试将vethx down掉,验证active slave会变成vetha,并且仍然可以ping通。
root@master:~# ip link set dev vethx down
root@master:~# ovs-appctl bond/show
---- bond2 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: 0a:44:22:44:75:1d(vethb)
slave vethb: enabled
active slave
may_enable: true
slave vethy: disabled
may_enable: false
---- bond1 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: da:62:a2:ec:13:ad(vetha)
slave vetha: enabled
active slave
may_enable: true
slave vethx: disabled
may_enable: false
root@master:~# ip netns exec test1 ping 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.838 ms
^C
--- 10.10.10.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.838/0.838/0.838/0.000 ms
将bond1上的两个slave口down掉,ping就会不通
root@master:~# ip link set dev vetha down
root@master:~# ip link set dev vethx down
root@master:~# ip netns exec test1 ping 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
^C
--- 10.10.10.2 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2037ms
root@master:~# ovs-appctl bond/show
---- bond2 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: 00:00:00:00:00:00(none)
slave vethb: disabled
may_enable: false
slave vethy: disabled
may_enable: false
---- bond1 ----
bond_mode: active-backup
bond may use recirculation: no, Recirc-ID : -1
bond-hash-basis: 0
updelay: 0 ms
downdelay: 0 ms
lacp_status: off
lacp_fallback_ab: false
active slave mac: 00:00:00:00:00:00(none)
slave vetha: disabled
may_enable: false
slave vethx: disabled
may_enable: false
代码分析
在代码结构中,大概分为如下三个层面:配置层,openflow层和转换层。
配置层 openflow层 xlate转换层
bridge -> ofproto -> xbridge
port -> ofproto_dpif->bundles: ofbundle -> xbundle
iface -> ofproto->ports: ofport -> xport
a. 通过ovs-vsctl配置的网桥,端口和接口等信息都认为是在配置层,可以使用ovs-vsctl show查看所有的配置。
b. 在bridge_reconfigure函数中,会将配置层信息传递到openflow层,每个iface分配openflow端口号,可以使用ovs-ofctl show br1查看。
c. 在type_run函数中,将openflow层信息转换到xlate层。
需要注意的是,在openflow层和datapath层只能看到iface,看不到port信息。所以对于bond口,在添加流表信息时,只能指定出端口为slave口。
在port_configure函数中,解析bond相关配置,保存到临时变量ofproto_bundle_settings 中,调用bundle_set转到openflow层。
static void
port_configure(struct port *port)
{
const struct ovsrec_port *cfg = port->cfg;
struct bond_settings bond_settings;
struct lacp_settings lacp_settings;
struct ofproto_bundle_settings s;
struct iface *iface;
/* Get name. */
s.name = port->name;
/* Get slaves. */
s.n_slaves = 0;
//对于普通端口来说,只有一个iface,所以n_slaves为1
//对于bond口来说,可能有多个iface,n_slaves为大于等于1的值
s.slaves = xmalloc(ovs_list_size(&port->ifaces) * sizeof *s.slaves);
LIST_FOR_EACH (iface, port_elem, &port->ifaces) {
s.slaves[s.n_slaves++] = iface->ofp_port;
}
...
/* Get LACP settings. */
s.lacp = port_configure_lacp(port, &lacp_settings);
if (s.lacp) {
size_t i = 0;
s.lacp_slaves = xmalloc(s.n_slaves * sizeof *s.lacp_slaves);
LIST_FOR_EACH (iface, port_elem, &port->ifaces) {
iface_configure_lacp(iface, &s.lacp_slaves[i++]);
}
} else {
s.lacp_slaves = NULL;
}
/* Get bond settings. */
if (s.n_slaves > 1) {
s.bond = &bond_settings;
port_configure_bond(port, &bond_settings);
} else {
s.bond = NULL;
LIST_FOR_EACH (iface, port_elem, &port->ifaces) {
netdev_set_miimon_interval(iface->netdev, 0);
}
}
/* Protected port mode */
s.protected = cfg->protected;
/* Register. */
ofproto_bundle_register(port->bridge->ofproto, port, &s);
/* Clean up. */
free(s.cvlans);
free(s.slaves);
free(s.trunks);
free(s.lacp_slaves);
}
bundle_set用来将ofproto_bundle_settings 中配置信息转到obundle结构中。
static int
bundle_set(struct ofproto *ofproto_, void *aux,
const struct ofproto_bundle_settings *s)
struct ofproto_dpif *ofproto = ofproto_dpif_cast(ofproto_);
bool need_flush = false;
struct ofport_dpif *port;
struct ofbundle *bundle;
bundle = bundle_lookup(ofproto, aux);
if (!bundle) {
bundle = xmalloc(sizeof *bundle);
bundle->ofproto = ofproto;
hmap_insert(&ofproto->bundles, &bundle->hmap_node,
hash_pointer(aux, 0));
bundle->aux = aux;
bundle->name = NULL;
ovs_list_init(&bundle->ports);
bundle->vlan_mode = PORT_VLAN_TRUNK;
bundle->qinq_ethtype = ETH_TYPE_VLAN_8021AD;
bundle->vlan = -1;
bundle->trunks = NULL;
bundle->cvlans = NULL;
bundle->use_priority_tags = s->use_priority_tags;
bundle->lacp = NULL;
bundle->bond = NULL;
bundle->floodable = true;
bundle->protected = false;
mbridge_register_bundle(ofproto->mbridge, bundle);
}
if (!bundle->name || strcmp(s->name, bundle->name)) {
free(bundle->name);
bundle->name = xstrdup(s->name);
}
/* LACP. */
if (s->lacp) {
ofproto->lacp_enabled = true;
if (!bundle->lacp) {
ofproto->backer->need_revalidate = REV_RECONFIGURE;
bundle->lacp = lacp_create();
}
lacp_configure(bundle->lacp, s->lacp);
} else {
lacp_unref(bundle->lacp);
bundle->lacp = NULL;
}
/* LACP. */
if (s->lacp) {
ofproto->lacp_enabled = true;
if (!bundle->lacp) {
ofproto->backer->need_revalidate = REV_RECONFIGURE;
bundle->lacp = lacp_create();
}
lacp_configure(bundle->lacp, s->lacp);
} else {
lacp_unref(bundle->lacp);
bundle->lacp = NULL;
}
/* Update set of ports. */
ok = true;
//对于普通端口来说,只有一个iface,所以n_slaves为1
//对于bond口来说,可能有多个iface,n_slaves为大于等于1的值
for (i = 0; i < s->n_slaves; i++) {
bundle_add_port(bundle, s->slaves[i], s->lacp ? &s->lacp_slaves[i] : NULL)
struct ofport_dpif *port;
//根据 ofp_port 到 ofproto->ports 查找
port = ofp_port_to_ofport(bundle->ofproto, ofp_port);
port->bundle = bundle;
ovs_list_push_back(&bundle->ports, &port->bundle_node);
if (lacp) {
bundle->ofproto->backer->need_revalidate = REV_RECONFIGURE;
lacp_slave_register(bundle->lacp, port, lacp);
struct slave *slave;
slave = slave_lookup(lacp, slave_);
if (!slave) {
slave = xzalloc(sizeof *slave);
slave->lacp = lacp;
slave->aux = slave_;
hmap_insert(&lacp->slaves, &slave->node, hash_pointer(slave_, 0));
slave_set_defaulted(slave);
if (!lacp->key_slave) {
lacp->key_slave = slave;
}
}
}
}
if (!ok || ovs_list_size(&bundle->ports) != s->n_slaves) {
struct ofport_dpif *next_port;
LIST_FOR_EACH_SAFE (port, next_port, bundle_node, &bundle->ports) {
for (i = 0; i < s->n_slaves; i++) {
if (s->slaves[i] == port->up.ofp_port) {
goto found;
}
}
bundle_del_port(port);
found: ;
}
}
ovs_assert(ovs_list_size(&bundle->ports) <= s->n_slaves);
if (ovs_list_is_empty(&bundle->ports)) {
bundle_destroy(bundle);
return EINVAL;
}
/* Bonding. */
if (!ovs_list_is_short(&bundle->ports)) {
bundle->ofproto->has_bonded_bundles = true;
if (bundle->bond) {
if (bond_reconfigure(bundle->bond, s->bond)) {
ofproto->backer->need_revalidate = REV_RECONFIGURE;
}
} else {
bundle->bond = bond_create(s->bond, ofproto);
ofproto->backer->need_revalidate = REV_RECONFIGURE;
}
LIST_FOR_EACH (port, bundle_node, &bundle->ports) {
bond_slave_register(bundle->bond, port,
port->up.ofp_port, port->up.netdev);
}
} else {
bond_unref(bundle->bond);
bundle->bond = NULL;
}
/* Set proteced port mode */
if (s->protected != bundle->protected) {
bundle->protected = s->protected;
need_flush = true;
}
/* If we changed something that would affect MAC learning, un-learn
* everything on this port and force flow revalidation. */
if (need_flush) {
bundle_flush_macs(bundle, false);
mcast_snooping_flush_bundle(ofproto->ms, bundle);
}
type_run用来将obundle转换到xbundle结构中
static int
type_run(const char *type)
if (backer->need_revalidate) {
HMAP_FOR_EACH (ofproto, all_ofproto_dpifs_node, &all_ofproto_dpifs) {
struct ofport_dpif *ofport;
struct ofbundle *bundle;
if (ofproto->backer != backer) {
continue;
}
...
HMAP_FOR_EACH (bundle, hmap_node, &ofproto->bundles) {
xlate_bundle_set(ofproto, bundle, bundle->name,
bundle->vlan_mode, bundle->qinq_ethtype,
bundle->vlan, bundle->trunks, bundle->cvlans,
bundle->use_priority_tags,
bundle->bond, bundle->lacp,
bundle->floodable, bundle->protected);
struct xbundle *xbundle;
//new_xcfg 全局变量
xbundle = xbundle_lookup(new_xcfg, ofbundle);
if (!xbundle) {
xbundle = xzalloc(sizeof *xbundle);
xbundle->ofbundle = ofbundle;
xbundle->xbridge = xbridge_lookup(new_xcfg, ofproto);
xlate_xbundle_init(new_xcfg, xbundle);
}
free(xbundle->name);
xbundle->name = xstrdup(name);
xlate_xbundle_set(xbundle, vlan_mode, qinq_ethtype, vlan, trunks, cvlans,
use_priority_tags, bond, lacp, floodable, protected);
xbundle->vlan_mode = vlan_mode;
xbundle->qinq_ethtype = qinq_ethtype;
xbundle->vlan = vlan;
xbundle->trunks = trunks;
xbundle->cvlans = cvlans;
xbundle->use_priority_tags = use_priority_tags;
xbundle->floodable = floodable;
xbundle->protected = protected;
if (xbundle->bond != bond) {
bond_unref(xbundle->bond);
xbundle->bond = bond_ref(bond);
}
if (xbundle->lacp != lacp) {
lacp_unref(xbundle->lacp);
xbundle->lacp = lacp_ref(lacp);
}
}
...
}
}
bond口出方向报文处理
如果出端口为bond的slave口,应该怎么选择slave口呢?
分为两种情况,如果流表直接指定了出端口为slave口,则报文只会从此slave口发出,另一种情况是流表没有指定slave口,而是通过normal动作进行转发,这个情况bond转发才会生效。
static void
output_normal(struct xlate_ctx *ctx, const struct xbundle *out_xbundle, const struct xvlan *xvlan)
struct ofport_dpif *ofport;
struct xport *xport;
if (ovs_list_is_empty(&out_xbundle->xports)) {
/* Partially configured bundle with no slaves. Drop the packet. */
return;
} else if (!out_xbundle->bond) {
xport = CONTAINER_OF(ovs_list_front(&out_xbundle->xports), struct xport,
bundle_node);
} else {
//出端口为 bond 口的处理
struct xlate_cfg *xcfg = ovsrcu_get(struct xlate_cfg *, &xcfgp);
struct flow_wildcards *wc = ctx->wc;
struct ofport_dpif *ofport;
//选择slave口
ofport = bond_choose_output_slave(out_xbundle->bond, &ctx->xin->flow, wc, vid);
xport = xport_lookup(xcfg, ofport);
if (!xport) {
/* No slaves enabled, so drop packet. */
return;
}
}
compose_output_action(ctx, xport->ofp_port, use_recirc ? &xr : NULL);
bond口入方向报文处理
在active-backup模式下,如果inactive slave收到组播/广播报文,并且走的是normal流表,就会被drop,代码流程如下。
do_xlate_actions->xlate_output_action->xlate_normal->is_admissible->bond_check_admissibility
enum bond_verdict
bond_check_admissibility(struct bond *bond, const void *slave_,
const struct eth_addr eth_dst)
{
...
/* Drop all multicast packets on inactive slaves. */
if (eth_addr_is_multicast(eth_dst)) {
if (bond->active_slave != slave) {
goto out;
}
}
...
}
验证方法如下:
现在bond口上vetha和vethb是active的,可以在br1上添加下面两条openflow流表后,在test1 netns中ping test2 netns,这样arp广播报文就会从inactive slave端口vethx发出,br2的inactive slave端口vethx收到报文后,走slow path流程,根据上面代码,报文就会被drop。
ovs-ofctl add-flow br1 in_port=2,actions:output=3
ovs-ofctl add-flow br1 in_port=3,actions:output=2
root@master:~# ovs-ofctl show br1
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000baae9ee6ba4b
n_tables:254, n_buffers:0
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(vetha): addr:da:62:a2:ec:13:ad
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
2(vethx): addr:8a:56:d7:03:9e:8a
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
3(vethn): addr:3e:09:a2:3a:69:40
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
LOCAL(br1): addr:ba:ae:9e:e6:ba:4b
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
OFPT_GET_CONFIG_REPLY (xid=0x4): frags=normal miss_send_len=0
root@master:~# ovs-appctl dpctl/dump-flows
recirc_id(0),in_port(7),eth_type(0x0806), packets:1418, bytes:59556, used:0.152s, actions:4
recirc_id(0),in_port(6),eth(














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









