







https://www.kernel.org/doc/Documentation/networking/scaling.txt
主要参考上面链接的kernel文档和kernel源码,分析下面几种技术如何提高多核系统的性能
RSS(receive side scaling):网卡多队列
RPS(receive packet Steering):RSS的软件实现
RFS(receive flwo Steering): 基于flow的RPS
Accelerated RFS: RFS的硬件实现
XPS(transmit packet Steering):应用在发送方向
RSS
现在网卡都有多队列功能,在MSIX中断模式下,每个队列都可以使用单独的中断。在多核系统下,将每个队列绑定到单独的core上,即让单独的core处理队列的中断,可通过下面的命令实现绑定,意思为让core 1处理中断27,值得注意的是,cpu列表最好和网卡在同一个numa上。
echo 0x1 > /proc/irq/27/smp_affinity
在单队列模式下,网卡收到的包都会让queue 0处理,那多队列模式下,数据包如何分发呢?
网卡内部有Redirection table(表大小不同网卡有不同的实现),表中每项包含一个队列id,当网卡收到包后,会先解析报文出五元组等信息,然后根据这些信息(可以设置基于ip,tcp,udp等)计算出hash值(hash算法是固定的,但是使用的key可以在初始化时指定),然后根据hash低7位取模table size,得到表的一项,取出此项包含的队列id,此id即是数据包发往的队列。
参考82599的datasheet,看看它是如何实现RSS的,如下图
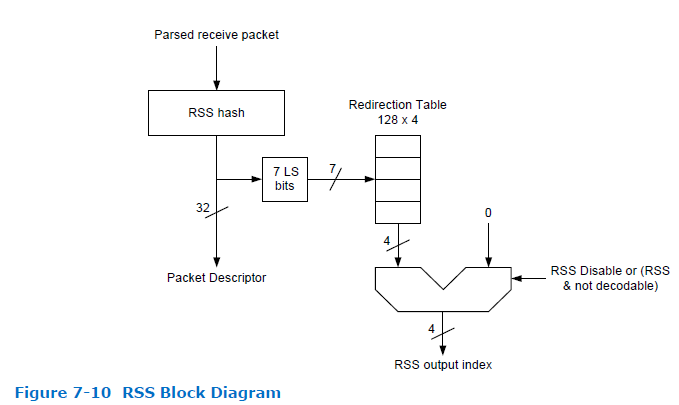
image.png
a. Parsed receive packet 解析数据包,获取五元组等信息
b. RSS hash 根据五元组的某些信息计算hash值
c. Packet Descriptor 将hash值保存到接收描述符中,最终会保存到skb->hash中,后续可以直接使用hash值,比如RPS查找cpu时使用这个hash值
d.7 LS bits 使用hash值低7位索引redirection table的一项,每项包含四位(所以最多支持16个队列)
e. RSS output index table的指定项就是接收队列。
那redirection table中每一项中的队列id是如何设置的呢?
在驱动初始化时,根据使能的队列个数,依次填充到每一项,达到队列最大值后,从0开始循环填充。比如使能了4个队列,则table的0-127项依次为:0,1,2,3,0,1,2,3...
看下ixgbe中使用到的和redirection table相关的寄存器,使用32个IXGBE_RETA寄存器,每个寄存器的0:3,11:8,19:16和27:24分别表示一个table的entry,而且是4位,所以使能RSS时最多支持16个队列。
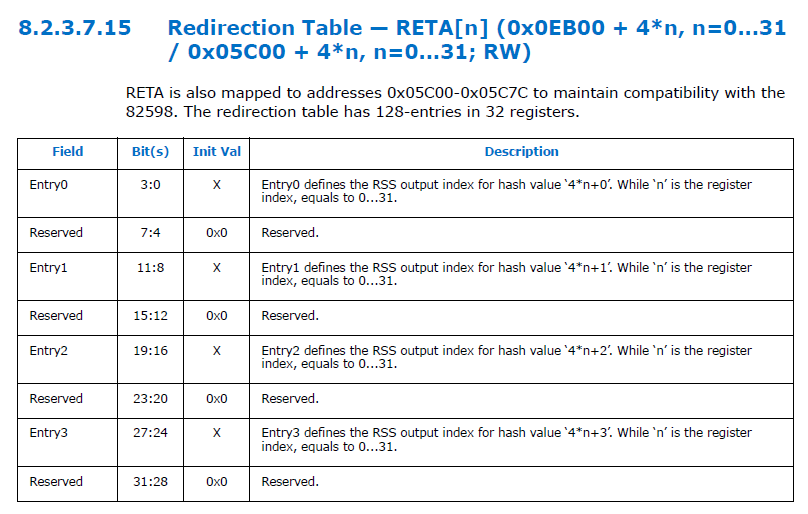
image.png
看一下ixgbe kernel driver是如何给redirection table赋值的,如下代码片段
static void ixgbe_setup_mrqc(struct ixgbe_adapter *adapter)
//rss_i是使能的队列个数
u16 rss_i = adapter->ring_feature[RING_F_RSS].indices;
/* Fill out redirection table */
for (i = 0, j = 0; i < 128; i++, j++) {
//j表示队列id,达到最大值rss_i后,从0开始
if (j == rss_i)
j = 0;
/* reta = 4-byte sliding window of
* 0x00..(indices-1)(indices-1)00..etc. */
//循环给reta赋值
reta = (reta << 8) | (j * 0x11);
//每四次写一次寄存器
if ((i & 3) == 3)
IXGBE_WRITE_REG(hw, IXGBE_RETA(i >> 2), reta);
}
RPS
在单队列网卡,多核系统上,或者多队列网卡,但是核数比队列多的情况下,可以使用RPS功能,将数据包分发到多个核上,使多核在软中断中处理数据包。这相当于是RSS的软件实现。
使能RPS也很简单,如下,将cpu列表写入队列对应的rps_cpus即可。
echo f > /sys/class/net/<dev>/queues/rx-<n>/rps_cpus
代码分析
和RPS相关的数据结构
//设备接收队列,和RPS相关成员是rps_map
/* This structure contains an instance of an RX queue. */
struct netdev_rx_queue {
#ifdef CONFIG_RPS
struct rps_map __rcu *rps_map;
struct rps_dev_flow_table __rcu *rps_flow_table;
#endif
struct kobject kobj;
struct net_device *dev;
} ____cacheline_aligned_in_smp;
//存放配置RPS的值,假如/sys/class/net/(dev)/queues/rx-(n)/rps_cpus=f,则
//len=4, cpus指向额外分配的内存数组,每个元素保存一个cpu值
struct rps_map {
unsigned int len;
struct rcu_head rcu;
u16 cpus[0];
};
设置 /sys/class/net/<dev>/queues/rx-<n>/rps_cpus 时
store_rps_map
for_each_cpu_and(cpu, mask, cpu_online_mask)
map->cpus[i++] = cpu;
if (i)
map->len = i;
//将map赋值到queue->rps_map中,在get_rps_cpu中会使用到
rcu_assign_pointer(queue->rps_map, map);
if (map)
//使能RPS
static_key_slow_inc(&rps_needed);
在netif_rx_internal(传统中断模式)或者netif_receive_skb_internal(NAPI模式下),如果使能了RPS(内核选项配置了CONFIG_RPS并且rps_needed为true),则调用get_rps_cpu选择合适的cpu,将skb放入此cpu的backlog队列中。
get_rps_cpu函数中也涉及到了RFS的流程,这里先忽略RFS流程,只关注RPS相关的。
因为RPS设置的是某个队列对应的cpu列表,所以需要先获取队列id,再获取此队列对应的cpu列表
/*
* get_rps_cpu is called from netif_receive_skb and returns the target
* CPU from the RPS map of the receiving queue for a given skb.
* rcu_read_lock must be held on entry.
*/
static int get_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow **rflowp)
{
struct netdev_rx_queue *rxqueue;
struct rps_map *map;
struct rps_dev_flow_table *flow_table;
struct rps_sock_flow_table *sock_flow_table;
int cpu = -1;
u16 tcpu;
u32 hash;
//skb->queue_mapping+1 记录了skb从哪个队列接收上来
if (skb_rx_queue_recorded(skb)) {
//获取接收skb队列index
u16 index = skb_get_rx_queue(skb);
if (unlikely(index >= dev->real_num_rx_queues)) {
WARN_ONCE(dev->real_num_rx_queues > 1,
"%s received packet on queue %u, but number "
"of RX queues is %u\n",
dev->name, index, dev->real_num_rx_queues);
goto done;
}
//根据index,获取rxqueue
rxqueue = dev->_rx + index;
} else
//这里应该是queue 0吧
rxqueue = dev->_rx;
map = rcu_dereference(rxqueue->rps_map);
if (map) {
//如果rps_map只配置了一个CPU,并且没有配置rps_flow_table,
//并且rps_sock_flow_entries 配置的这个cpu在线,则直接使用这个cpu。
//如果这个cpu不在线,则返回-1.
if (map->len == 1 &&
!rcu_access_pointer(rxqueue->rps_flow_table)) {
tcpu = map->cpus[0];
if (cpu_online(tcpu))
cpu = tcpu;
goto done;
}
//没有配置 rps_map,也没有配置 rps_flow_table
} else if (!rcu_access_pointer(rxqueue->rps_flow_table)) {
goto done;
}
skb_reset_network_header(skb);
//根据skb获取hash值。如果在RSS模式下,可以直接使用网
//卡计算的hash值,否则需要根据数据包信息计算一个
hash = skb_get_hash(skb);
if (!hash)
goto done;
//flow_table 和 sock_flow_table 是RPF的流程,暂时忽略
flow_table = rcu_dereference(rxqueue->rps_flow_table);
sock_flow_table = rcu_dereference(rps_sock_flow_table);
if (flow_table && sock_flow_table) {
u16 next_cpu;
struct rps_dev_flow *rflow;
rflow = &flow_table->flows[hash & flow_table->mask];
tcpu = rflow->cpu;
next_cpu = sock_flow_table->ents[hash & sock_flow_table->mask];
/*
* If the desired CPU (where last recvmsg was done) is
* different from current CPU (one in the rx-queue flow
* table entry), switch if one of the following holds:
* - Current CPU is unset (equal to RPS_NO_CPU).
* - Current CPU is offline.
* - The current CPU's queue tail has advanced beyond the
* last packet that was enqueued using this table entry.
* This guarantees that all previous packets for the flow
* have been dequeued, thus preserving in order delivery.
*/
if (unlikely(tcpu != next_cpu) &&
(tcpu == RPS_NO_CPU || !cpu_online(tcpu) ||
((int)(per_cpu(softnet_data, tcpu).input_queue_head -
rflow->last_qtail)) >= 0)) {
tcpu = next_cpu;
rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
}
if (tcpu != RPS_NO_CPU && cpu_online(tcpu)) {
*rflowp = rflow;
cpu = tcpu;
goto done;
}
}
//如果没有在设备流表rps_flow_table和全局流表
//rps_sock_flow_table中找到目标cpu,则使用hash在
//rps_map中找一个cpu即可。
if (map) {
tcpu = map->cpus[reciprocal_scale(hash, map->len)];
if (cpu_online(tcpu)) {
cpu = tcpu;
goto done;
}
}
done:
return cpu;
RFS
从RPS选择cpu方法可知,就是使用skb的hash随机选择一个cpu,没有考虑到应用层运行在哪个cpu上,如果执行软中断的cpu和运行应用层的cpu不是同一个cpu,势必会降低cpu cache命中率,降低性能。
所以就有了RFS,原理是将运行应用的cpu(为了高性能,一般都会将应用和cpu绑定起来),保存到一个表中,在get_rps_cpu时,从这个表中获取cpu,即可保证执行软中断的cpu和运行应用层的cpu是同一个cpu。
这个表就是 /proc/sys/net/core/rps_sock_flow_entries。
从下面代码可知,设置这个表其实就是分配内存数组,并将所有ents初始化为RPS_NO_CPU。显然只有这个空表是没用的,需要动态填充,而且表的索引是通过skb->hash得到的。
//全局流表
/*
* The rps_sock_flow_table contains mappings of flows to the last CPU
* on which they were processed by the application (set in recvmsg).
*/
struct rps_sock_flow_table {
unsigned int mask;
//ents指向分配的内存,每个元素代表最新的运行application的cpu
u16 ents[0];
};
//设置 /proc/sys/net/core/rps_sock_flow_entries 时,调用如下函数
rps_sock_flow_sysctl
for (i = 0; i < size; i++)
sock_table->ents[i] = RPS_NO_CPU;
if (sock_table)
static_key_slow_inc(&rps_needed);
保存skb->hash到sk->sk_rxhash,并设置数据流对应的cpu为无效
tcp_v4_do_rcv
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
sock_rps_save_rxhash(sk, skb);
return 0
if (sk->sk_state == TCP_LISTEN) {
if (nsk != sk) {
sock_rps_save_rxhash(nsk, skb);
else
sock_rps_save_rxhash(sk, skb);
将skb的hash值保存到sk->sk_rxhash中,后面通过socket收发数据时,可以实时保存cpu到全局流表中
static inline void sock_rps_save_rxhash(struct sock *sk,
const struct sk_buff *skb)
{
#ifdef CONFIG_RPS
if (unlikely(sk->sk_rxhash != skb->hash)) {
sock_rps_reset_flow(sk);
sk->sk_rxhash = skb->hash;
}
#endif
}
static inline void sock_rps_reset_flow(const struct sock *sk)
{
#ifdef CONFIG_RPS
sock_rps_reset_flow_hash(sk->sk_rxhash);
#endif
}
static inline void sock_rps_reset_flow_hash(__u32 hash)
{
#ifdef CONFIG_RPS
struct rps_sock_flow_table *sock_flow_table;
rcu_read_lock();
sock_flow_table = rcu_dereference(rps_sock_flow_table);
rps_reset_sock_flow(sock_flow_table, hash);
rcu_read_unlock();
#endif
}
static inline void rps_reset_sock_flow(struct rps_sock_flow_table *table,
u32 hash)
{
if (table && hash)
table->ents[hash & table->mask] = RPS_NO_CPU;
}
下面几个函数调用会更新当前处理的数据流的cpu信息
inet_accept
inet_recvmsg
inet_sendmsg
tcp_poll
sock_rps_record_flow(sk);
static inline void sock_rps_record_flow(const struct sock *sk)
{
#ifdef CONFIG_RPS
//sk->sk_rxhash在连接阶段从skb->hash获取
sock_rps_record_flow_hash(sk->sk_rxhash);
#endif
}
static inline void sock_rps_record_flow_hash(__u32 hash)
{
#ifdef CONFIG_RPS
struct rps_sock_flow_table *sock_flow_table;
rcu_read_lock();
sock_flow_table = rcu_dereference(rps_sock_flow_table);
rps_record_sock_flow(sock_flow_table, hash);
rcu_read_unlock();
#endif
}
static inline void rps_record_sock_flow(struct rps_sock_flow_table *table,
u32 hash)
{
if (table && hash) {
unsigned int cpu, index = hash & table->mask;
/* We only give a hint, preemption can change cpu under us */
cpu = raw_smp_processor_id();
//将运行应用的cpu保存到hash到的表中
if (table->ents[index] != cpu)
table->ents[index] = cpu;
}
}
经过上面的设置,执行软中断的cpu就可以和运行应用的cpu是同一个CPU了,如果此时用户将应用绑定到其他cpu了,但是之前cpu的backlog还有未处理完的数据包,就会导致同一个流的数据包在不同的cpu上处理,会造成包乱序,所以又有了另一个基于队列的表 /sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt,这个表可以记录之前cpu bachkog上数据包何时处理完,等数据包都处理完后就可以将流迁移到新的cpu上了。
代码分析:
struct rps_dev_flow {
//cpu在set_rps_cpu中被赋值成最新的运行application的cpu
u16 cpu;
u16 filter;
//last_qtail用来记录cpu指定的percpu队列input_pkt_queue入
//队数据包的个数。初始值为input_queue_head,后续入队一
//个skb就加一
unsigned int last_qtail;
};
//设备流表,flows指向额外分配的内存,每个元素是一个
//rps_dev_flow 结构。使用skb->hash算出使用哪个rps_dev_flow
struct rps_dev_flow_table {
unsigned int mask;
struct rcu_head rcu;
struct rps_dev_flow flows[0];
};
/* This structure contains an instance of an RX queue. */
struct netdev_rx_queue {
#ifdef CONFIG_RPS
struct rps_dev_flow_table __rcu *rps_flow_table;
#endif
} ____cacheline_aligned_in_smp;
//设置 /sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt 时
store_rps_dev_flow_table_cnt
table->mask = mask;
for (count = 0; count <= mask; count++)
table->flows[count].cpu = RPS_NO_CPU;
只有下面这两个表同时设置才生效,下面再次分析get_rps_cpu,看看RFS是如何生效的
/proc/sys/net/core/rps_sock_flow_entries
/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt
/*
* get_rps_cpu is called from netif_receive_skb and returns the target
* CPU from the RPS map of the receiving queue for a given skb.
* rcu_read_lock must be held on entry.
*/
static int get_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow **rflowp)
{
struct netdev_rx_queue *rxqueue;
struct rps_map *map;
struct rps_dev_flow_table *flow_table;
struct rps_sock_flow_table *sock_flow_table;
int cpu = -1;
u16 tcpu;
u32 hash;
//通过skb->queue_mapping获取接收skb的rx queue index
if (skb_rx_queue_recorded(skb)) {
u16 index = skb_get_rx_queue(skb);
if (unlikely(index >= dev->real_num_rx_queues)) {
WARN_ONCE(dev->real_num_rx_queues > 1,
"%s received packet on queue %u, but number "
"of RX queues is %u\n",
dev->name, index, dev->real_num_rx_queues);
goto done;
}
rxqueue = dev->_rx + index;
} else
rxqueue = dev->_rx;
map = rcu_dereference(rxqueue->rps_map);
if (map) {
//如果rps_map只配置了一个CPU,并且没有配置
//rps_flow_table,并且rps_sock_flow_entries 配置的这
//个cpu在线,则直接使用这个cpu。如果这个cpu不在
//线,则返回-1.
if (map->len == 1 &&
!rcu_access_pointer(rxqueue->rps_flow_table)) {
tcpu = map->cpus[0];
if (cpu_online(tcpu))
cpu = tcpu;
goto done;
}
//没有配置 rps_map,也没有配置 rps_flow_table
} else if (!rcu_access_pointer(rxqueue->rps_flow_table)) {
goto done;
}
skb_reset_network_header(skb);
hash = skb_get_hash(skb);
if (!hash)
goto done;
flow_table = rcu_dereference(rxqueue->rps_flow_table);
sock_flow_table = rcu_dereference(rps_sock_flow_table);
if (flow_table && sock_flow_table) {
u16 next_cpu;
struct rps_dev_flow *rflow;
//tcpu记录的是处理数据包的cpu
rflow = &flow_table->flows[hash & flow_table->mask];
tcpu = rflow->cpu;
//next_cpu记录的是运行application的cpu
next_cpu = sock_flow_table->ents[hash & sock_flow_table->mask];
//数据刚来时,tcpu和next_cpu 都为RPS_NO_CPU,最
//终会在rps_map中根据hash选择一个cpu(这个cpu就比
//较随机了,有可能不是运行application的cpu)。
//数据包上送到协议栈后,通过socket收包时(调用socket
//的cpu肯定是运行application的cpu),会调用
//sock_rps_record_flow将数据流和运行application的cpu
//绑定起来,即记录到rps_sock_flow_table表中。
//第二个数据包走到此处时,tcpu和next_cpu不相等,并
//且tcpu为RPS_NO_CPU,所以调用set_rps_cpu更新
//rps_flow_table中skb->hash对应的cpu为next_cpu,将
//rflow->last_qtail 设置为per_cpu(softnet_data,
//next_cpu).input_queue_head,并且返回next_cpu,这
//样application就可以快速的收到这个数据包。
//第三个,第四个等后续的数据包,tcpu和next_cpu相
//等,就可以返回tcpu,application就可以快速的收到数
//据包。假如这个cpu对应的percpu队列有100个数据包
//还没处理完,但是application被移动到另一个cpu上运
//行了,为了防止数据包乱序,只有等到这个cpu的队列
//上队列上数据包都被处理完后,才能调用set_rps_cpu
//将新的cpu更新到rps_flow_table上
/*
* If the desired CPU (where last recvmsg was done) is
* different from current CPU (one in the rx-queue flow
* table entry), switch if one of the following holds:
* - Current CPU is unset (equal to RPS_NO_CPU).
* - Current CPU is offline.
* - The current CPU's queue tail has advanced beyond the
* last packet that was enqueued using this table entry.
* This guarantees that all previous packets for the flow
* have been dequeued, thus preserving in order delivery.
*/
//next_cpu表示运行application的cpu,如果和tcpu不相
//等,并且满足下面三个条件时就需要更新
//rps_flow_table,否则数据包所在cpu就和application所
//在cpu不是同一个,导致cache命中率降低影响性能。
//这三个条件是:
//a. tcpu为初始值RPS_NO_CPU,发生在最开始数据包刚来时
//b. tcpu从online变成offline了,即变成不可用了,所以需要更新
//c.application从一个cpu移动到另一个cpu了,并且之前
//cpu队列上的数据包都被处理后,需要更新,以便以后
//的数据都放在新的cpu队列上。
if (unlikely(tcpu != next_cpu) &&
(tcpu == RPS_NO_CPU || !cpu_online(tcpu) ||
((int)(per_cpu(softnet_data, tcpu).input_queue_head -
rflow->last_qtail)) >= 0)) {
tcpu = next_cpu;
rflow = set_rps_cpu(dev, skb, rflow, next_cpu);
}
if (tcpu != RPS_NO_CPU && cpu_online(tcpu)) {
*rflowp = rflow;
cpu = tcpu;
goto done;
}
}
//如果没有在设备流表rps_flow_table和全局流表rps_sock_flow_table中找到目标cpu,
//则使用hash在rps_map中找一个cpu即可。
if (map) {
tcpu = map->cpus[reciprocal_scale(hash, map->len)];
if (cpu_online(tcpu)) {
cpu = tcpu;
goto done;
}
}
done:
return cpu;
}
更新rflow->cpu为next_cpu,并且记录next_cpu队列的input_queue_head到rflow->last_qtail中,后续数据包入队到next_cpu队列上时,rflow->last_qtail都会加1,通过判断input_queue_head和rflow->last_qtail来判断next_cpu队列是否为空。
static struct rps_dev_flow *
set_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow *rflow, u16 next_cpu)
{
if (next_cpu != RPS_NO_CPU) {
rflow->last_qtail =
per_cpu(softnet_data, next_cpu).input_queue_head;
}
rflow->cpu = next_cpu;
return rflow;
}
Accelerated RFS
RFS是将skb放在运行应用的cpu的backlog中处理的,而且我们知道默认情况下哪个cpu处理硬件中断,就由哪个cpu处理软件中断,即who trigger, who run,那能不能通过网卡的fdir功能(流重定向)将数据流重定向到运用应用的cpu所处理的队列上呢?这就是Accelerated RFS的作用。
除了使能RFS的两个表,没其他需要使能的,前提是网卡驱动得支持函数 ndo_rx_flow_steer,不过貌似支持的网卡没几个。
static struct rps_dev_flow *
set_rps_cpu(struct net_device *dev, struct sk_buff *skb,
struct rps_dev_flow *rflow, u16 next_cpu)
{
if (next_cpu != RPS_NO_CPU) {
#ifdef CONFIG_RFS_ACCEL
struct netdev_rx_queue *rxqueue;
struct rps_dev_flow_table *flow_table;
struct rps_dev_flow *old_rflow;
u32 flow_id;
u16 rxq_index;
int rc;
/* Should we steer this flow to a different hardware queue? */
if (!skb_rx_queue_recorded(skb) || !dev->rx_cpu_rmap ||
!(dev->features & NETIF_F_NTUPLE))
goto out;
rxq_index = cpu_rmap_lookup_index(dev->rx_cpu_rmap, next_cpu);
if (rxq_index == skb_get_rx_queue(skb))
goto out;
rxqueue = dev->_rx + rxq_index;
flow_table = rcu_dereference(rxqueue->rps_flow_table);
if (!flow_table)
goto out;
flow_id = skb_get_hash(skb) & flow_table->mask;
rc = dev->netdev_ops->ndo_rx_flow_steer(dev, skb,
rxq_index, flow_id);
if (rc < 0)
goto out;
old_rflow = rflow;
rflow = &flow_table->flows[flow_id];
rflow->filter = rc;
if (old_rflow->filter == rflow->filter)
old_rflow->filter = RPS_NO_FILTER;
out:
#endif
rflow->last_qtail =
per_cpu(softnet_data, next_cpu).input_queue_head;
}
rflow->cpu = next_cpu;
return rflow;
}
XPS
前面的几种技术都是接收方向的,XPS是针对发送方向的,即从网卡发送出去时,如果有多个发送队列,选择使用哪个队列。
可通过如下命令设置,此命令表示运行在f指定的cpu上的应用调用socket发送的数据会从网卡的tx-n队列发送出去。
echo f > /sys/class/net/<dev>/queues/tx-<n>/xps_cpus
虽然设置的是设备的tx queue对应的cpu列表,但是转换到代码中保存的是每个cpu可使用的queue列表。因为查找xps_cpus时,肯定是已知cpu id,寻找从哪个tx queue发送。
选择tx queue时,优先选择xps_cpu指定的queue,如果没有指定就使用skb hash计算出来一个。当然也不是每个报文都得经过这个过程,只有socket的第一个报文需要,选择出queue后,将此queue设置到sk->sk_tx_queue_mapping,后续报文直接获取sk_tx_queue_mapping即可。
和XPS相关的几个结构体
/*
* This structure holds an XPS map which can be of variable length. The
* map is an array of queues.
*/
//percpu的结构,queues用来保存此cpu可以使用哪几个queue
struct xps_map {
unsigned int len;
unsigned int alloc_len;
struct rcu_head rcu;
u16 queues[0];
};
/*
* This structure holds all XPS maps for device. Maps are indexed by CPU.
*/
//cpu_map大小为cpu个数
struct xps_dev_maps {
struct rcu_head rcu;
struct xps_map __rcu *cpu_map[0];
};
//perdevice结构,xps_maps用来保存设备tx queue和cpu的对应关系
struct net_device {
#ifdef CONFIG_XPS
struct xps_dev_maps __rcu *xps_maps;
#endif
设置xps_cpus时调用如下函数
static ssize_t store_xps_map(struct netdev_queue *queue,
struct netdev_queue_attribute *attribute,
const char *buf, size_t len)
{
struct net_device *dev = queue->dev;
unsigned long index;
cpumask_var_t mask;
int err;
if (!capable(CAP_NET_ADMIN))
return -EPERM;
if (!alloc_cpumask_var(&mask, GFP_KERNEL))
return -ENOMEM;
//获取设置的队列索引
index = get_netdev_queue_index(queue);
//获取设置的cpu列表
err = bitmap_parse(buf, len, cpumask_bits(mask), nr_cpumask_bits);
if (err) {
free_cpumask_var(mask);
return err;
}
//更新queue和cpu的映射关系
err = netif_set_xps_queue(dev, mask, index);
free_cpumask_var(mask);
return err ? : len;
}
int netif_set_xps_queue(struct net_device *dev, const struct cpumask *mask,
u16 index)
{
struct xps_dev_maps *dev_maps, *new_dev_maps = NULL;
struct xps_map *map, *new_map;
int maps_sz = max_t(unsigned int, XPS_DEV_MAPS_SIZE, L1_CACHE_BYTES);
int cpu, numa_node_id = -2;
bool active = false;
mutex_lock(&xps_map_mutex);
dev_maps = xmap_dereference(dev->xps_maps);
/* allocate memory for queue storage */
for_each_online_cpu(cpu) {
if (!cpumask_test_cpu(cpu, mask))
continue;
if (!new_dev_maps)
new_dev_maps = kzalloc(maps_sz, GFP_KERNEL);
if (!new_dev_maps) {
mutex_unlock(&xps_map_mutex);
return -ENOMEM;
}
map = dev_maps ? xmap_dereference(dev_maps->cpu_map[cpu]) :
NULL;
map = expand_xps_map(map, cpu, index);
if (!map)
goto error;
RCU_INIT_POINTER(new_dev_maps->cpu_map[cpu], map);
}
if (!new_dev_maps)
goto out_no_new_maps;
for_each_possible_cpu(cpu) {
if (cpumask_test_cpu(cpu, mask) && cpu_online(cpu)) {
/* add queue to CPU maps */
int pos = 0;
map = xmap_dereference(new_dev_maps->cpu_map[cpu]);
while ((pos < map->len) && (map->queues[pos] != index))
pos++;
if (pos == map->len)
map->queues[map->len++] = index;
#ifdef CONFIG_NUMA
if (numa_node_id == -2)
numa_node_id = cpu_to_node(cpu);
else if (numa_node_id != cpu_to_node(cpu))
numa_node_id = -1;
#endif
} else if (dev_maps) {
/* fill in the new device map from the old device map */
map = xmap_dereference(dev_maps->cpu_map[cpu]);
RCU_INIT_POINTER(new_dev_maps->cpu_map[cpu], map);
}
}
rcu_assign_pointer(dev->xps_maps, new_dev_maps);
/* Cleanup old maps */
if (dev_maps) {
for_each_possible_cpu(cpu) {
new_map = xmap_dereference(new_dev_maps->cpu_map[cpu]);
map = xmap_dereference(dev_maps->cpu_map[cpu]);
if (map && map != new_map)
kfree_rcu(map, rcu);
}
kfree_rcu(dev_maps, rcu);
}
dev_maps = new_dev_maps;
active = true;
out_no_new_maps:
/* update Tx queue numa node */
netdev_queue_numa_node_write(netdev_get_tx_queue(dev, index),
(numa_node_id >= 0) ? numa_node_id :
NUMA_NO_NODE);
if (!dev_maps)
goto out_no_maps;
/* removes queue from unused CPUs */
for_each_possible_cpu(cpu) {
if (cpumask_test_cpu(cpu, mask) && cpu_online(cpu))
continue;
if (remove_xps_queue(dev_maps, cpu, index))
active = true;
}
/* free map if not active */
if (!active) {
RCU_INIT_POINTER(dev->xps_maps, NULL);
kfree_rcu(dev_maps, rcu);
}
out_no_maps:
mutex_unlock(&xps_map_mutex);
return 0;
error:
/* remove any maps that we added */
for_each_possible_cpu(cpu) {
new_map = xmap_dereference(new_dev_maps->cpu_map[cpu]);
map = dev_maps ? xmap_dereference(dev_maps->cpu_map[cpu]) :
NULL;
if (new_map && new_map != map)
kfree(new_map);
}
mutex_unlock(&xps_map_mutex);
kfree(new_dev_maps);
return -ENOMEM;
}
设置完xps_cpus后,就可以在发送数据时选择指定的queue
//__dev_queue_xmit为通用发送函数,其中会调用netdev_pick_tx选择合适的tx queue
static int __dev_queue_xmit(struct sk_buff *skb, void *accel_priv)
txq = netdev_pick_tx(dev, skb, accel_priv);
struct netdev_queue *netdev_pick_tx(struct net_device *dev,
struct sk_buff *skb,
void *accel_priv)
{
int queue_index = 0;
//设备tx queue个数大于1才需要选择
if (dev->real_num_tx_queues != 1) {
const struct net_device_ops *ops = dev->netdev_ops;
//如果网卡驱动提供了ndo_select_queue,则使用
//ndo_select_queue选择queue。没有合适的还得调用
//__netdev_pick_tx。
if (ops->ndo_select_queue)
queue_index = ops->ndo_select_queue(dev, skb, accel_priv,
__netdev_pick_tx);
else
queue_index = __netdev_pick_tx(dev, skb);
if (!accel_priv)
queue_index = netdev_cap_txqueue(dev, queue_index);
}
//将tx queue索引保存到skb->queue_mapping
skb_set_queue_mapping(skb, queue_index);
//根据索引获取指定的netdev_queue
return netdev_get_tx_queue(dev, queue_index);
}
static u16 __netdev_pick_tx(struct net_device *dev, struct sk_buff *skb)
{
struct sock *sk = skb->sk;
//取出sk中保存的tx queue
int queue_index = sk_tx_queue_get(sk);
//在以下三种情况下才会更新tx queue
//a. queue_index小于0,这是初始情况
//b. skb->ooo_okay(ooo全称out of order),一个标志位,只
//有在socket发送完数据后才会设置,表示可以切换queue(假
//如初始设置的queue是1,突然改成3了,为了防
//止报文乱序,要等socket中的数据都发送完成后,设置
//ooo_okay标志后,才可以将 发送queue改成3),只对tcp
//socket有效
//c. queue_index大于设备queue总数
if (queue_index < 0 || skb->ooo_okay ||
queue_index >= dev->real_num_tx_queues) {
//从xps_cpu中选择queue
int new_index = get_xps_queue(dev, skb);
if (new_index < 0)
//如果没有设置,就根据hash和设备queue总数计算出一个
new_index = skb_tx_hash(dev, skb);
if (queue_index != new_index && sk &&
rcu_access_pointer(sk->sk_dst_cache))
//将queue索引更新到 sk->sk_tx_queue_mapping
sk_tx_queue_set(sk, new_index);
queue_index = new_index;
}
return queue_index;
}
根据当前运行的cpu raw_smp_processor_id,来查找tx queue。
如果此cpu只对应一个queue,就使用这个queue,如果设置了多个queue,还得使用skb hash选择一个。
static inline int get_xps_queue(struct net_device *dev, struct sk_buff *skb)
{
#ifdef CONFIG_XPS
struct xps_dev_maps *dev_maps;
struct xps_map *map;
int queue_index = -1;
rcu_read_lock();
dev_maps = rcu_dereference(dev->xps_maps);
if (dev_maps) {
map = rcu_dereference(
dev_maps->cpu_map[raw_smp_processor_id()]);
if (map) {
if (map->len == 1)
queue_index = map->queues[0];
else
queue_index = map->queues[reciprocal_scale(skb_get_hash(skb),
map->len)];
if (unlikely(queue_index >= dev->real_num_tx_queues))
queue_index = -1;
}
}
rcu_read_unlock();
return queue_index;
#else
return -1;
#endif
}














 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









