






最近又出了个比较吸引人眼球的Prompt Learning,甚至该方法还被称之为NLP的“第四范式”,具体有哪几项请参考以下链接:
综述文章:https://arxiv.org/pdf/2107.13586.pdf
相关资源:http://pretrain.nlpedia.ai
Part1什么是Prompt Learning
从BERT诞生开始,使用下游任务数据微调预训练语言模型 (LM)已成为 NLP 领域的通用做法。直到GPT-3模型首先将自然语言的提示信息(prompt)和任务示例(demonstration)作为上下文输入给GPT-3,使得GPT-3只需要少数的几个样本,不需要训练底层的参数便能够处理任务。应该是受到这一做法的启发,目前很多研究聚焦在Prompt Learning上,只为了更好的激发语言模型的潜能。
在了解Prompt Learning之前,首先我们要知道什么是prompt。prompt是提示的意思,也就是说需要提示模型我们想让它干什么。通常在GPT-3中,我们输入一段描述,再加上“翻译”或者“问答”的prompt,那么GPT-3会生成相应的结果。最近该玩法在NLU中也得到了应用,比如情感分类任务,给定一句话“I missed the bus today.”,在其之后添加一个prompt:“I felt so __”,之后让语言模型用一个情感类的词进行完型填空,再将填空的词语映射到标签,这样一来就能够解决分类任务了。
大家发现没有,这样一来减少了训练和测试阶段之间的gap,因为我们在预训练的时候使用的MLM任务就是一个完型填空任务,通常使用分类任务fine-tuning模型的时候需要加一个hidden_size * label_size的FFN,还得专门去训练这个FFN的参数。但是如果使用Prompt Learning的方式,就省略了这一步了。这样一来岂不是不用花大力气训练模型了?哈哈是的,很多研究证明Prompt Learning在小样本(few-shot)场景下很有效。
Part2Few-shot Learner
论文标题:Making Pre-trained Language Models Better Few-shot Learners
论文来源:ACL2021
论文链接:https://arxiv.org/pdf/2012.15723.pdf
论文代码:https://github.com/princeton-nlp/LM-BFF
本文主要有两个贡献点:
(1)基于提示(prompt)进行微调,关键是如何自动化生成提示模板;
(2)将样本示例以上下文的形式添加到每个输入中,关键是如何对示例进行采样;
1prompt-based fine-tuning
之前说过GPT-3模型基于prompt生成文本。受到该启发本文提出了一种可以应用于任意预训练模型的prompt learning模型——LM-BFF(小样本微调预训练模型)。
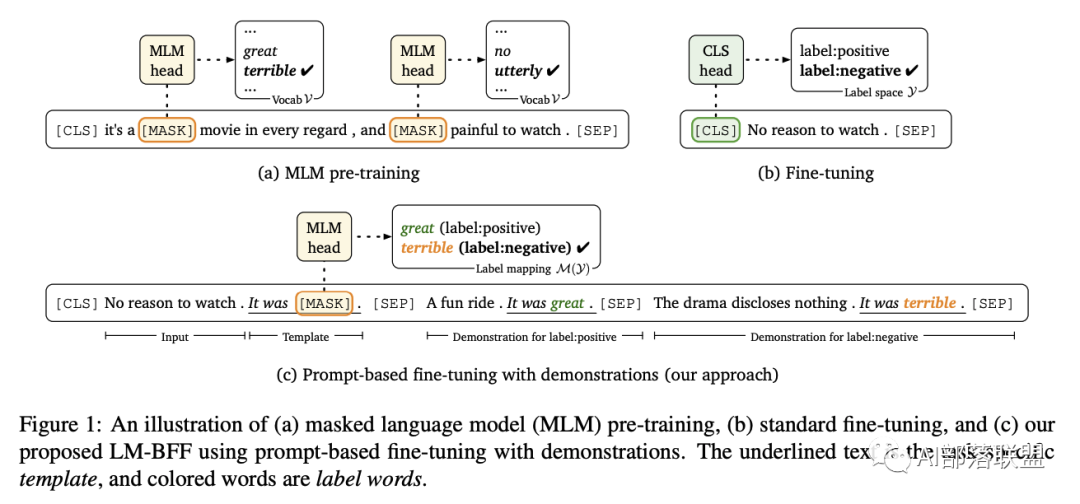
从上图可以看出在预训练的时候使用的MLM任务就是一个完型填空任务,在分类任务中微调的时候需要加一个hidden_size * label_size的FFN,微调的过程需要训练这个FFN的参数。在使用Prompt Learning的方式的时候省略了这一步。这样一来就不用花大力气训练模型了,而且该方法减少了训练和测试阶段之间的gap,在小样本(few-shot)场景下很有效。
在具体的实验过程中,作者发现使用不同的模板或不同的标签词进行微调得到的效果是不同的,如下图所示:
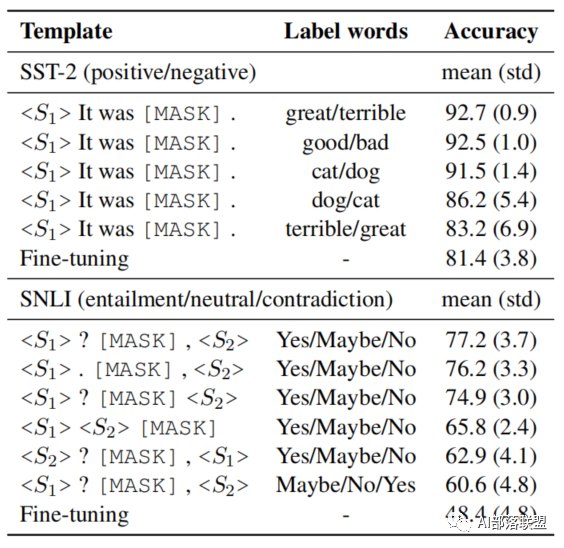
比如对于同一个标签词,如果使用的prompt的模板不同(替换了某个单词或者删除某一个标点符号),得到的结果会有较大的波动;而且当选择不同的标签词时,对预测的结果也会产生影响。这是由于人工设计模板和标签词时候和模型本身具有的gap带来的缺陷。因此作者提出一种自动创建模板的方法。
2Automatic Prompt Generation
Prompt的自动生成又分为了两个部分(label的生成和模板的生成):
Label Generation
这个部分主要分成3步:
(1)首先在训练集中,针对未经过微调的语言模型,对于每个label都找到使其条件概率最大Topk个单词;
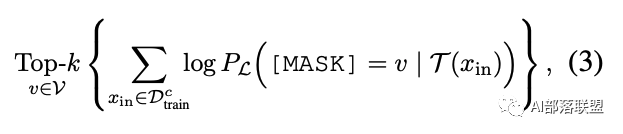
(2)综合每个类别下的候选标签词,然后找出使得训练集正确率最大的top-n个分配方式;
(3)使用dev集对模型进行微调,从n个分配方式中选择最佳的一个标签词,构建标签映射关系M。
Prompt Generation
模板的生成则是使用的T5模型,固定标签词,生成固定模板。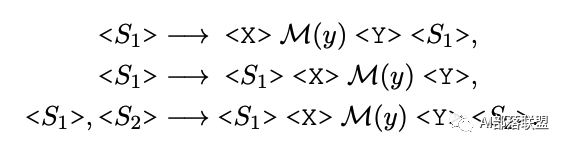
整体过程如下所示: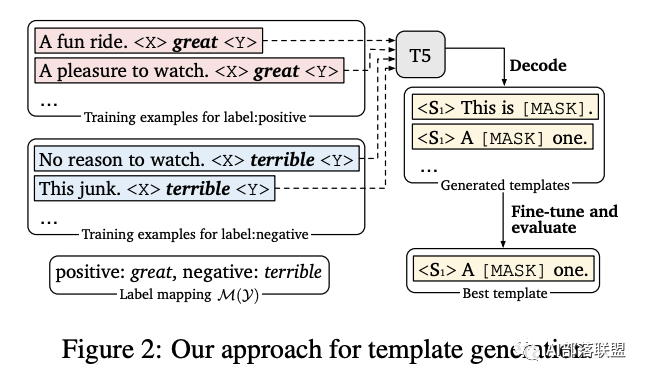
Fine-tuning with Demonstration
在GPT-3中,微调的时候从训练集中随机抽取32个示例,以上下文的形式添加到每个输入中;
这种方式的缺陷在于:样本示例的数量会受到模型最大输入长度的限制;不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
LM-BFF采用2种简单的方式进行了改进:
对于每个输入,从每个类别中随机采样一个样本示例,最终将所有类别下的采样示例进行拼接输入;
对于每个输入,在每个类别中,通过与Sentence-BERT进行相似度计算、并从排序得分的top50%中随机选择一个样本示例。
Results
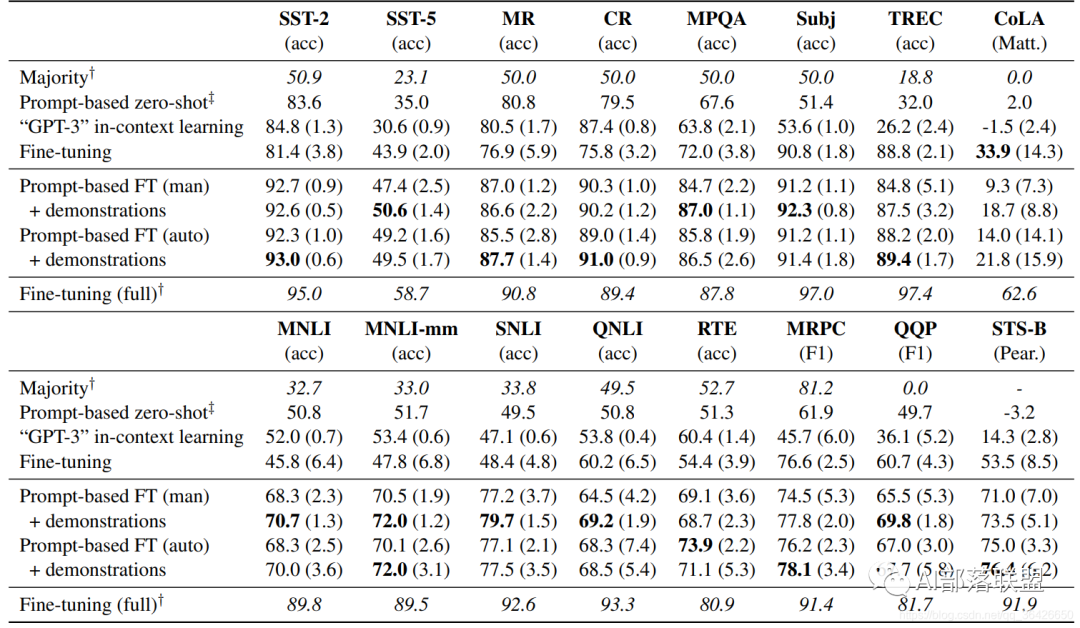
本文提出了一种简单而又有效的小样本微调方法——LM-BFF。主要包括2部分:
采用提示自动构建方式来进行「基于模板的微调方法」。
动态选择样本示例,作为输入的上下文。但LM-BFF也有以下缺陷:
LM-BFF仍落后基于全量标注数据的标准微调方法(PS:废话,数据目前还是越多好~)
LM-BFF自动构建提示的方法虽然有效,但扩展搜索空间在现实应用中仍是一个巨大挑战;
LM-BFF仅支持几种特定的任务:1)能自然转化为「空白填空」问题,如结构化预测的NER任务可能就不适合;2)句子输入不要太长;3)不要包含过多的类别;其中2)和3)可以在长距离语言模型中进行改善。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑黄海广老师《机器学习课程》课件合集
本站qq群851320808,加入微信群请扫码:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









