






一、简介
fastText 是 Facebook 于2016年开源的一个词向量训练与文本分类工具,其典型应用场景是“无监督的词向量学习”和“有监督的文本分类”。fastText 提供简单而高效的文本分类和词表征学习方法,性能比肩深度学习但速度优势明显。在文本分类任务中,fastText(浅层网络)往往能取得和深度学习分类器相媲美的精度,却在训练和预测时间上快深度网络许多数量级。在标准的多核 CPU 上,10亿词级别语料库的词向量能够在10分钟以内训练完成,在1分钟之内能够分类有着31万类别的50多万条句子。
github地址:https://github.com/facebookresearch/fastText star:22.9k
论文及地址:
Bag of Tricks for Efficient Text Classification:https://arxiv.org/abs/1607.01759
Enriching Word Vectors with Subword Information:https://arxiv.org/abs/1607.04606
FastText.zip: Compressing text classification models:https://arxiv.org/abs/1612.03651
二、模型架构
介绍模型之前,我们先稍微聊一点八卦。fastText 的其中一个作者是 Thomas Mikolov。熟悉 word2vec 的同学应该对这个名字很熟悉,正是他当年在 Google 带了一个团队倒腾出来了 word2vec,很好的解决了传统词袋表示的缺点,极大地推动了 NLP 领域的发展。后来这位大哥跳槽去了 Facebook,才有了现在的 fastText。从“血缘”角度来看,fastText 和 word2vec 可以说是一脉相承。
fastText 中词向量的无监督训练过程使用的是 word2vec 中的 CBOW 架构和 Skip-gram 架构。在文本分类任务中,fastText 模型架构和 word2vec 中的 CBOW 很相似,不同之处在于 fastText 最终预测的是文档类别标签(label)而 CBOW 预测的是中间词(middle word),即模型架构类似但模型的任务有所不同。如下为 CBOW 的结构:

word2vec 将单词间的上下文关系转化为多分类任务,通过训练逻辑回归模型得到单词的词向量,每次多分类任务的类别数量为词库大小 。通常的文本语料中,词库单词少则数万、多则上百万,直接训练多分类逻辑回归并不现实。word2vec 中提供了两种针对大规模多分类问题的优化手段:negative sampling 和 hierarchical softmax。在训练中,negative sampling 对于当前单词只随机采样少量负样本,从而减轻了计算量;hierarchical softmax 根据词库中单词的词频(count)构建一棵霍夫曼树,从根结点到叶子结点的路径可以表示为一系列二分类器,一次多分类计算的复杂度从 降低到了 , 为词向量的维度。

上图为 fastText 模型架构,此架构展示的是文本分类任务过程,没有展示词向量的训练过程。其中 表示文档或句子中的单词和 n-gram 向量,整个文档可以使用所有单词和 n-gram 向量累加后的均值表示,即 ,然后经过一个线性分类器得到输出层的 label。对比 word2vec 中的 CBOW 模型,可以发现两个模型非常相似,只不过 fastText 模型最后预测的是文档的 label,而 CBOW 模型预测的是窗口中间的词,前者是有监督的学习,后者是无监督的学习。另外,fastText 分类模型的输入层为文档中的所有词和 n-gram,而 CBOW 模型的输入层只包括当前窗口内除中心词的所有词,没有 n-gram 和 subword 信息。
三、数学原理
fastText 本质上可以看成是一个浅层的神经网络,因此其前向传播(forward propogation)过程可描述如下:
其中 表示从隐藏层到输出层的权重矩阵, 是输出层的输出向量。由于模型需要预测文档属于某个类别的概率,因此需要对输出向量加一个 softmax 层,损失函数可以定义为:
当文档类别数很多时,softmax 层的计算会比较耗时,为了加快训练过程,fastText 同样采用了和word2vec 类似的方法。一种方法是使用 hierarchical softmax,当类别数为 ,词向量维度为 时,计算复杂度可以从 降到 。另一种方法是采用 negative sampling,即每次从除当前 label 外的其他 label 中采样几个作为负样本,训练逻辑回归模型。
Hierarchical softmax
fastText 中基于 hierarchical softmax 的文本分类结构如下图所示:
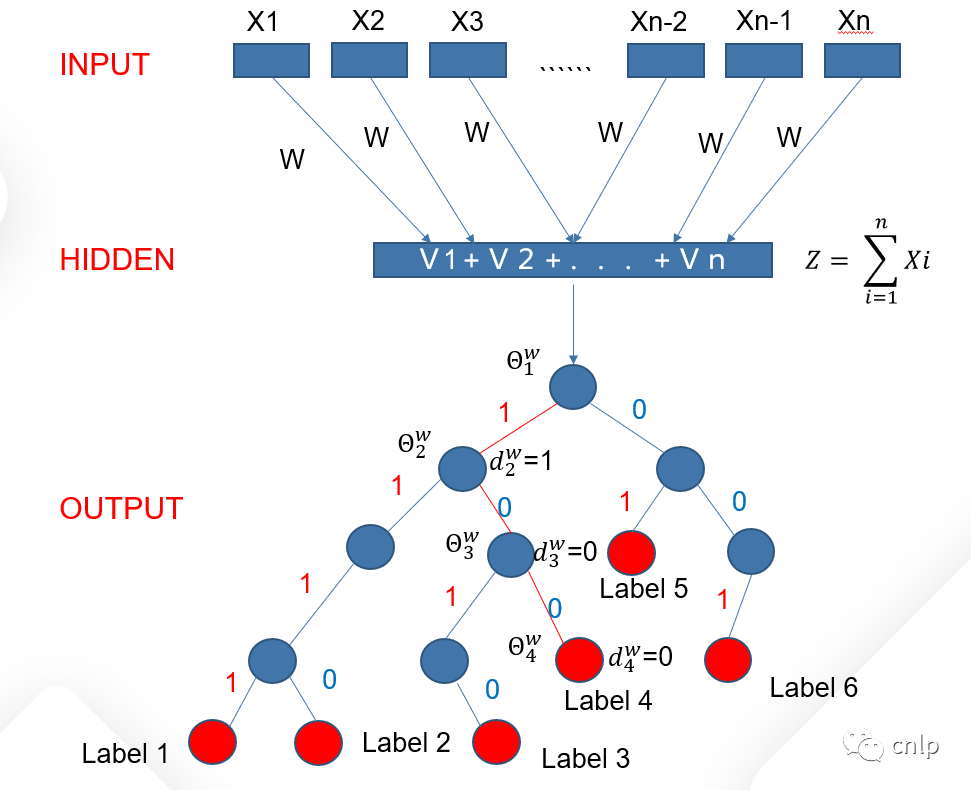
输出层对应一棵二叉树,它是以训练语料中的所有文档标签为叶子结点,以各个标签下的文档数量为权值构造出来的霍夫曼树。在这棵 Huffman 树中,叶子结点共 个,分别表示语料中的文档类别标签,非叶子结点 个,每个非叶子结点对应一个二分类所需的权重向量 。考虑 Huffman 树中的某个叶子结点,假设它对应语料中第 个类别,记
:从根结点出发到达类别 对应叶子结点的路径。
:路径 中包含的结点个数。
:路径 中的所有结点,其中第一个表示根结点,最后一个表示类别 对应的叶子结点。
类别 对应叶子结点的霍夫曼编码:,其中 表示路径 中第 个结点对应的编码(根结点不对应编码)。
:路径 中每个非叶子结点对应的二分类权重。
对于训练语料中的每个类别 ,Huffman 树中必然存在一条从根结点到类别 对应叶子结点的路径 (且这条路径是唯一的)。路径上存在 个分支,将每个分支看成一次二分类,每一次二分类就产生一个概率,将这些概率连乘起来,就是单个样本的似然函数 ,可表示为:
其中 为文档 的向量表示,在前文中已经介绍过。上式中:
因此
整个训练语料的对数似然函数可以表示为:
损失函数为负的对数似然函数,即
fastText 中使用随机梯度下降法最小化上述损失函数。
Negative sampling
fastText 中使用 Negative Sampling(简称为NEG)主要是为了提高训练速度。与 Hierarchical Softmax 相比,NEG 不再使用复杂的 Huffman 树,而是利用相对简单的随机负采样,能大幅度提高性能,因此可作为 Hierarchical Softmax 的一种替代。
对于一个给定的文档类别 ,如何生成它对应的负样本集合 呢?训练语料中不同类别标签的文档数量有多有少,对于那些文档数量多的类别,被选为负样本的概率就应该比较大;反之,对于那些低频类别标签,被选为负样本的概率就应该比较小。这本质上是一个带权采样问题,fastText 中使用如下方法初始化负采样中需要用到的查找表:
std::vector<int32_t> negative_tables(const std::vector<int64_t>& targetCounts,
const int32_t NEGATIVE_TABLE_SIZE = 10000000) {
float z = 0.0;
std::vector<int32_t> negatives;
for (size_t i = 0; i < targetCounts.size(); i++) {
z += pow(targetCounts[i], 0.5);
}
for (size_t i = 0; i < targetCounts.size(); i++) {
float c = pow(targetCounts[i], 0.5);
for (size_t j = 0; j < c * NEGATIVE_TABLE_SIZE / z; j++) {
negatives.push_back(i);
}
}
return negatives;
}在实际进行类别 的负采样时,首先随机生成一个 ~ 之间的正整数 ,然后判断查找表中对应的 是否等于类别 ,如果相等,则重复上述过程,直至生成一个不为 的负类别标签。
基于 negative sampling 方法的单个样本似然函数可以表示为:
其中 为文档 的向量表示, 为类别 对应的权重向量, 为对类别 进行负采样的负标签集合。上式中:
整个训练语料的损失函数可以表示为:
其中 为语料中文档 的类别。fastText 中使用随机梯度下降法最小化上述损失函数。
N-gram特征
文本分类任务中常用的特征提取方法是词袋模型(Bag-of-words),但词袋模型不能考虑词与词之间的顺序,丢失了词序信息。为了弥补这个不足,fastText 增加了 N-gram 的特征,其 N-gram 特征包括两种:(1) 词与词之间的 n-gram 特征;(2) 单个词内的 subword 特征,即字符级别的 n-gram 特征。举个例子来说,假设某篇文档包含如下几个词:
machine learning and data mining algorithms对于词与词之间的 n-gram 特征
相应的 bigram 词组为:machine learning,learning and,and data,data mining,mining algorithms;
相应的 trigram 词组为:machine learning and,learning and data,and data mining,data mining algorithms
对于字符级别的 n-gram 特征,以 machine 为例,假设 ,可以得到 machine 的6个字符级 4-gram 如下:<mac,mach,achi,chin,hine,ine>。
在文本分类任务中,文档的向量表示计算为文档内每个单词、词与词之间的 n-gram 以及单个词内的 subwords 的向量求和后取平均。在词向量任务中,单词的向量表示计算为该单词以及其 subwords 的向量求和后取平均。与 word2vec 相比,fastText 在词向量训练时融入了 subword 信息。通过随机梯度下降法,fastText 可以同时学到单词的向量表示和两种 n-gram 的向量表示。
具体实现上,由于 n-gram 的量远比单词数大的多,完全存下所有的 n-gram 也不现实。fastText 采用了 Hash 桶的方式,把所有的 n-gram 都哈希到 个桶中,哈希到同一个桶的所有 n-gram 共享一个 embedding vector。如下图所示:

图中 是 Embedding 矩阵,每行代表一个 word 或 n-gram 的表示向量,其中前 行是 word embeddings,后 行是 n-gram embeddings。每个 n-gram 经哈希函数哈希到 ~ 的位置,得到对应的 embedding 向量。用哈希的方式既能保证查找是 的效率,又能把内存消耗控制在 范围内。不过这种方法潜在的问题是存在哈希冲突,不同的 n-gram 可能会共享同一个 embedding。如果桶大小取的足够大,这种影响会很小。
fastText 中使用 n-gram 特征有如下优点:
为罕见的单词生成更好的词向量。根据上面的字符级别的 n-gram 来说,即使这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量。
在词汇单词中,即使单词没有出现在训练语料库中,仍然可以根据字符级 n-gram 的向量构造出单词的词向量。
n-gram 特征可以让模型学习到局部单词顺序的部分信息,如果不考虑 n-gram 则便是取每个单词,这样无法考虑到词序所包含的信息,也可理解为上下文信息,因此通过 n-gram 的方式关联相邻的几个词,会让模型在训练时保持词序信息。
四、文本分类
首先将 fastText 代码库克隆到本地,进入代码库,并进行编译:
git clone --recursive https://github.com/facebookresearch/fastText.git
cd fastText/
make编译完成后生成 fasttext 可执行文件,运行 ./fasttext 命令后得到:
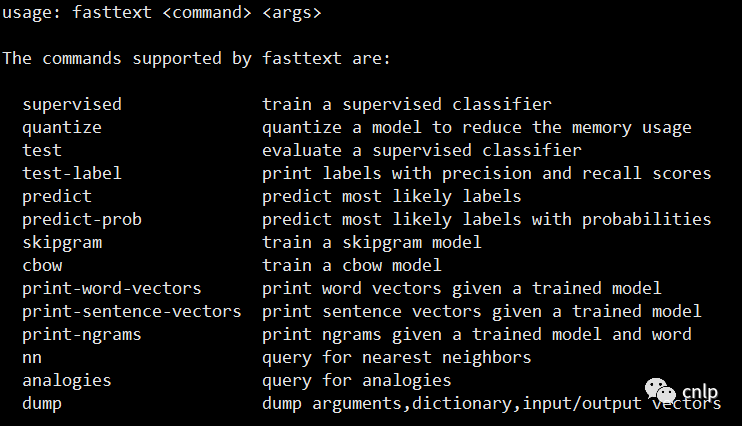
fasttext 支持使用有监督的语料训练一个文本分类器,使用无监督的语料训练 cbow 和 skipgram 词向量模型。运行代码仓库中 classification-example.sh 的如下部分代码,下载文本分类需要用到的训练数据和测试数据,并进行预处理:
myshuf() {
perl -MList::Util=shuffle -e 'print shuffle(<>);' "$@";
}
normalize_text() {
tr '[:upper:]' '[:lower:]' | sed -e 's/^/__label__/g' | \
sed -e "s/'/ ' /g" -e 's/"//g' -e 's/\./ \. /g' -e 's/<br \/>/ /g' \
-e 's/,/ , /g' -e 's/(/ ( /g' -e 's/)/ ) /g' -e 's/\!/ \! /g' \
-e 's/\?/ \? /g' -e 's/\;/ /g' -e 's/\:/ /g' | tr -s " " | myshuf
}
RESULTDIR=result
DATADIR=data
mkdir -p "${RESULTDIR}"
mkdir -p "${DATADIR}"
if [ ! -f "${DATADIR}/dbpedia.train" ]
then
wget -c "https://github.com/le-scientifique/torchDatasets/raw/master/dbpedia_csv.tar.gz" -O "${DATADIR}/dbpedia_csv.tar.gz"
tar -xzvf "${DATADIR}/dbpedia_csv.tar.gz" -C "${DATADIR}"
cat "${DATADIR}/dbpedia_csv/train.csv" | normalize_text > "${DATADIR}/dbpedia.train"
cat "${DATADIR}/dbpedia_csv/test.csv" | normalize_text > "${DATADIR}/dbpedia.test"
fi预处理后的训练数据和测试数据位于新建的 data 文件夹下,分别对应 dbpedia.train 和 dbpedia.test,其格式如下:

每行表示一个样本,行首是该样本的类别标签:__label__3 形式。使用如下命令训练一个文本分类器:
./fasttext supervised -input "${DATADIR}/dbpedia.train" -output "${RESULTDIR}/dbpedia" -dim 10 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 5 -thread 4其中 DATADIR 和 RESULTDIR 在前面代码中已经定义,-input 参数为如上形式的训练数据文件,-output 参数为模型和词向量的保存路径,-dim 参数为词向量的维度,-wordNgrams 参数为加入词的几阶 ngram 信息,-epoch 参数为迭代次数。训练过程如下所示:

训练完成后,在 -output 参数对应的路径下会有一个 .bin 模型文件和 .vec 词向量文件。使用如下命令在测试数据集上评估分类模型效果:
./fasttext test-label "${RESULTDIR}/dbpedia.bin" "${DATADIR}/dbpedia.test"输出模型在测试数据集上每个类别的 Precision、Recall 和 F1-Score 信息如下:
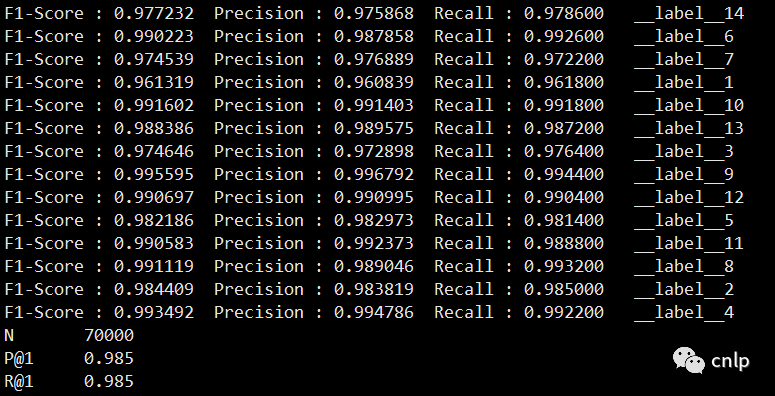
可以看出 fastText 在 dbpedia 数据集上训练得到的文本分类模型效果很好而且速度很快。基于训练好的分类模型,使用如下命令进行输入文本的类别预测:
./fasttext predict "${RESULTDIR}/dbpedia.bin" "${DATADIR}/dbpedia.test" > "${RESULTDIR}/dbpedia.test.predict"dbpedia.test.predict 文件为模型预测得到的类别标签文件。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑黄海广老师《机器学习课程》视频课本站qq群851320808,加入微信群请扫码:
















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









