






作者丨王剑波
编辑丨极市平台
导读
本文为ECV2022竞赛获得客流统计识别的冠军方案分享,作者团队简要分享了他们的比赛思路。
前言
极市计算机视觉开发者榜单大赛自2018年首次举办以来,至今已成功举办四届赛事。随着赛事的逐年升级,极市计算机视觉开发者榜单大赛的影响力也在逐步提升,如今已逐渐成为AI圈最受瞩目的算法大赛之一。
赛题分析
赛题描述
项目背景:商场门店需要统计客流情况,对公司营销决策添加辅助信息。
项目目的:统计门店客流,根据工牌信息进行员工统计的去重(开关控制是否开启),并识别进店人员的年龄、性别。
数据集描述和分析
数据集中的人头(head)和 工牌( badge )采用了2D bbox标注。其中人头没有采用ReID标注。
数据集还有 性别(sex)和 年龄(age)的标注。

整个训练数据集(V8,V10,V11)一共包括 57447张图像。
其中包括 人头(head)的标注有 222460 个,工牌(badge)的标注有 8421个,且工牌一共分为五种工牌,分别是white_XP_badge、blue_XP_badge、black_XP_badge、white_BH_badge、blue_BH_badge。
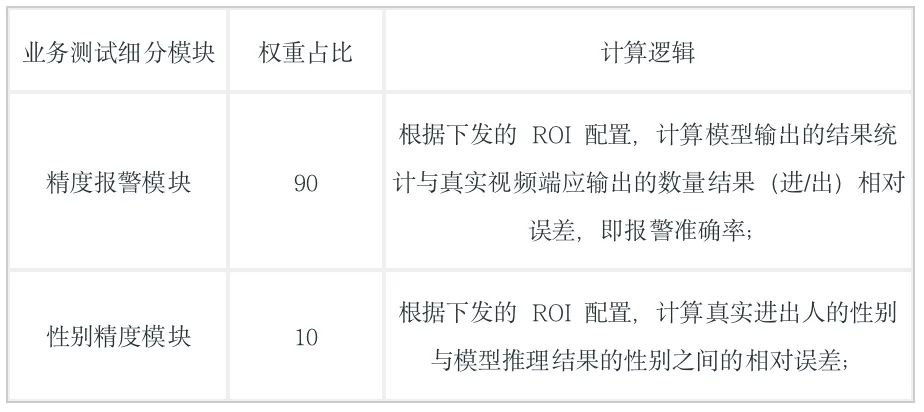
评测方法
模型榜

◎实战榜
算法思路
考虑数据集的中 人头(head) 的标注为2D bbox标注,没有ReID标注,因此采用目标检测 + 基于运动目标追踪的方法。
由于算法有实时性的要求,因此目标检测算法应当选用轻量级one-stage检测框架的目标检测算法。
对于追踪可以选用的方法有SORT、ByteTrack、OC-SORT、BoT-SORT。
模型加速采用C++和TensorRT进行模型推理加速。
通过追踪结果和平面几何知识,对ROI区域内的人流进行统计出入人数。
算法流程和实现
模型选型
根据现有的目标检测算法调研结果,考虑到本赛题要求算法具有实时性和模型训练和部署的便捷性,因此我们选用YOLOv5作为本算法的目标检测器。
根据现有的目标追踪算法调研结果,考虑到本赛题要求算法是基于运动的模型和模型部署的便捷性,因此我们选用ByteTrack作为本算法的目标追踪器。
YOLOv5模型训练
考虑到模型需要对人头进行检测和追踪,而且还要对其进行性别和年龄分析,如果直接采用纯目标检测的方法势必造成样本分布不均匀,造成人头检测效果差。因此本算法提出YOLOv5 + 属性分类的方法,采用该方法还能减小模型计算量。
class_id, cx, cy, w, h class_id, attr_set_1, attr_set_2, …, attr_set_n, cx, cy, w, h

网络的类别输出设置为2 + 3 + 11 + 6,而纯YOLOv5的方法网络输出是5 + 10 * 2
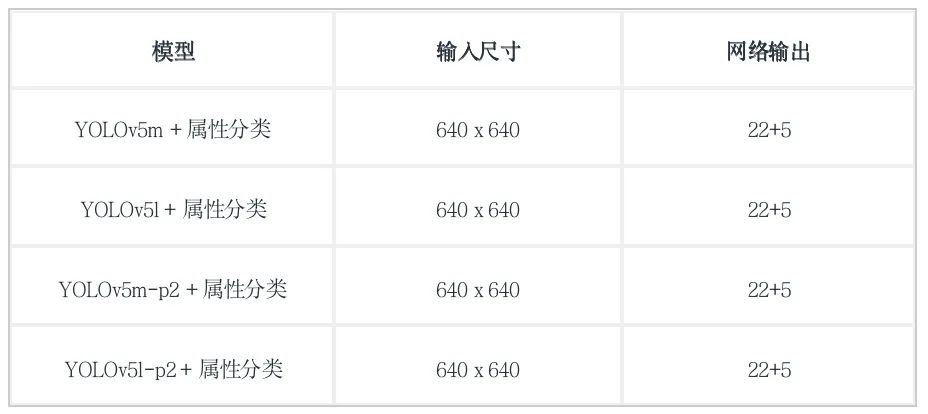
模型参数选择:选取YOLOv5m作为 baseline,模型输入尺寸都设置为640 x 640,其余参数采用默认设置
考虑到人头(head)和工牌(badge)都是相对较小的小目标,因此可以选用YOLOv5的P2模型。
进行如下模型调优实验,选取最佳模型:
ByteTrack
ByteTrack基本原理

一个简单有效、通用的数据关联方法。获取所有检测框,将这些检测框分成高分数和低分数的两个集合。首先把高分数检测框关联进轨迹中,之后关联低分数检测框给没有和高分数检测框匹配的轨迹,并过滤掉背景。

第一阶段:通过检测器获取检测框和对应的检测分数,对检测框进行分类,如果分数高于T_high,将检测框分类为高分数类,分数低于T_high,高于T_low时,将检测框分类为低分数类。

第二阶段:进行第一次匹配,使用IoU距离对轨迹和高分数检测框进行相似度计算,然后使用匈牙利算法来完成轨迹和检测框的匹配,如果IoU距离计算出的分数低于0.2,将会被丢弃,在匈牙利算法中没有匹配的轨迹和检测框保留下来。

第三阶段:进行第二次匹配,使用IoU距离对轨迹和低分数检测框进行相似度计算,方法跟第二阶段方法一致。

第四阶段:两次匹配都没有匹配到的轨迹当成丢失的轨迹,在之后可能会被重新激活;对两次匹配都没有匹配到的检测框,将它们初始化成新的轨迹。
业务逻辑
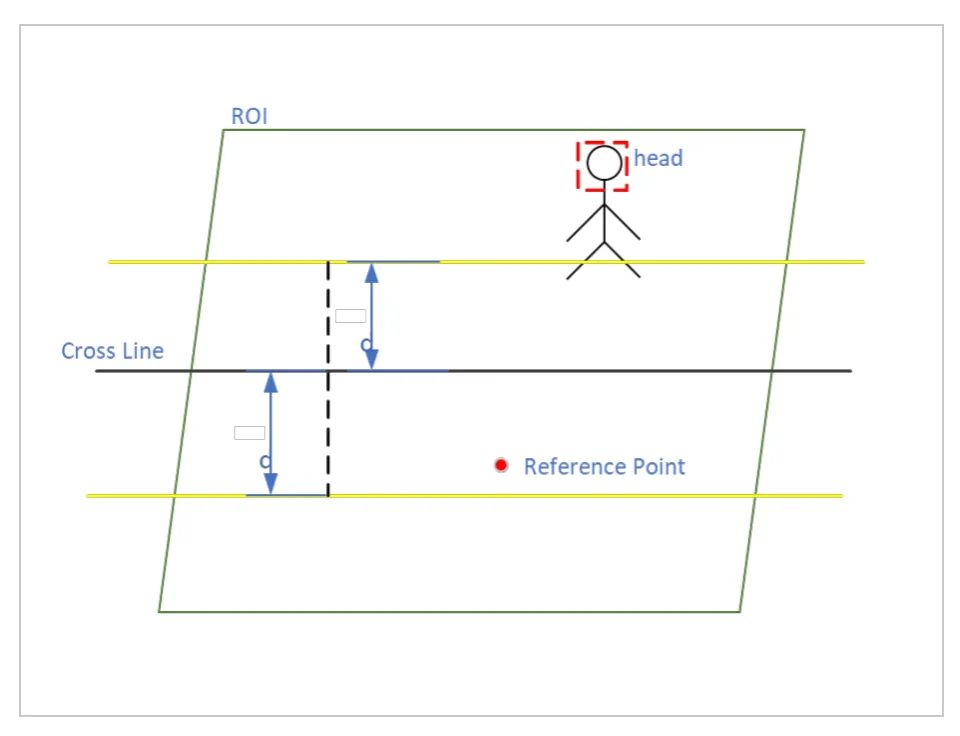
如果 cross line 的斜率存在, 那么其直线方程斜率 , 其中 是直线上的 两点, 因此可以得到其直线方程
如果 cross line 的斜率不存在, 那么其直线方程为 , 其中 是直线上的两点。假设 Reference point 的坐标 ,人头 (head) 中心点的坐标为 :
室内室外的判定 可以通过cross line的直线方程判断Reference point和人头(head)中心点是否属于同一侧,判断公式如下:
进出的判定 可以通过人头的前后状态变化,判断是否进出。例如,前一时刻在室内,下一时刻在室外,那么就是出。
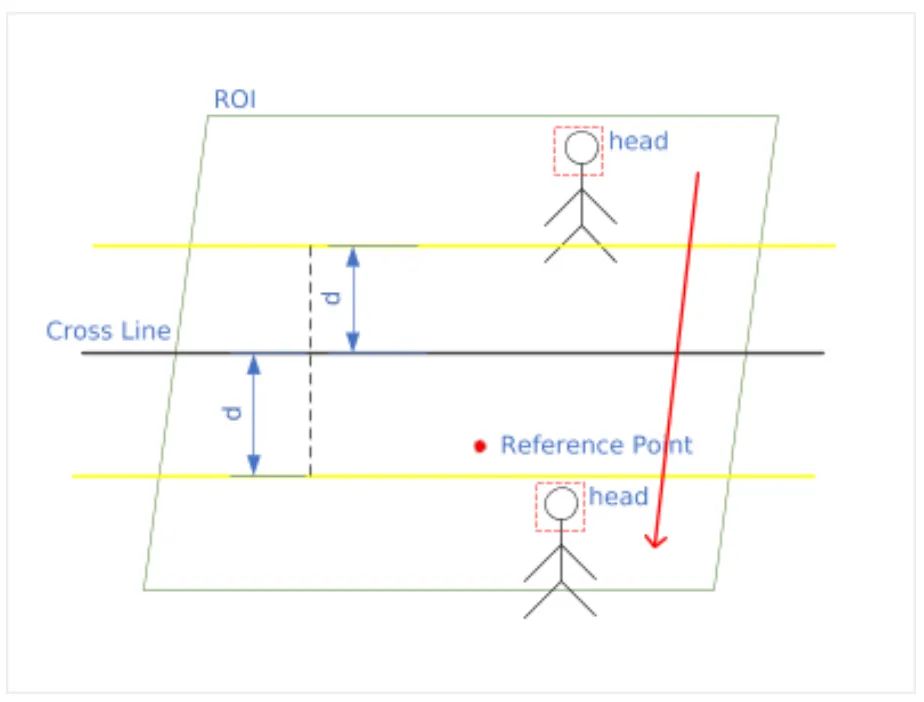
如何缓解徘徊问题 事实上如果仅仅只是按照上述方法进行判断进出,那么还存在一定的问题。当有人重复再边缘徘徊,就会造成数据失真。为了避免这种问题,提出了两种策略缓解徘徊的问题。
1.设定缓冲区,具体是在cross line两边设置距离为d的缓冲区,当行人在缓冲区内行走时,当前状态不会立即发生改变,只有当行人走出缓冲区,才会发生状态变化。
2.在追踪过程中,只对追踪目标进行一次进出计数。
算法实现图

结果展示
模型测试
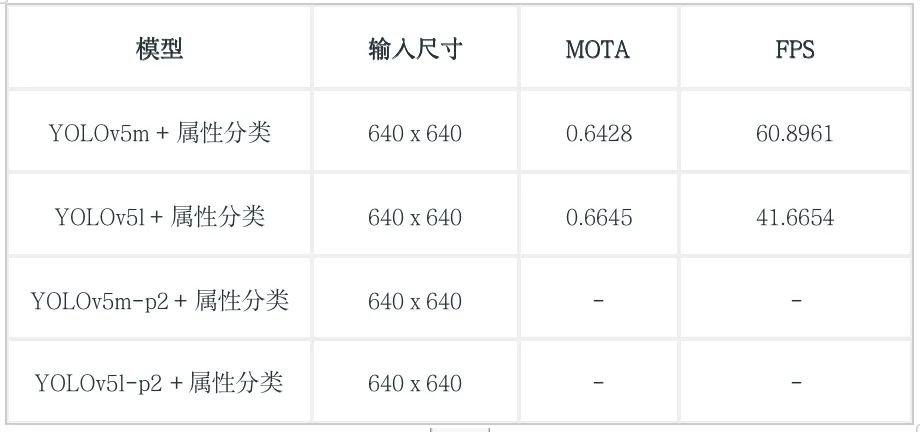
模型榜
实战榜
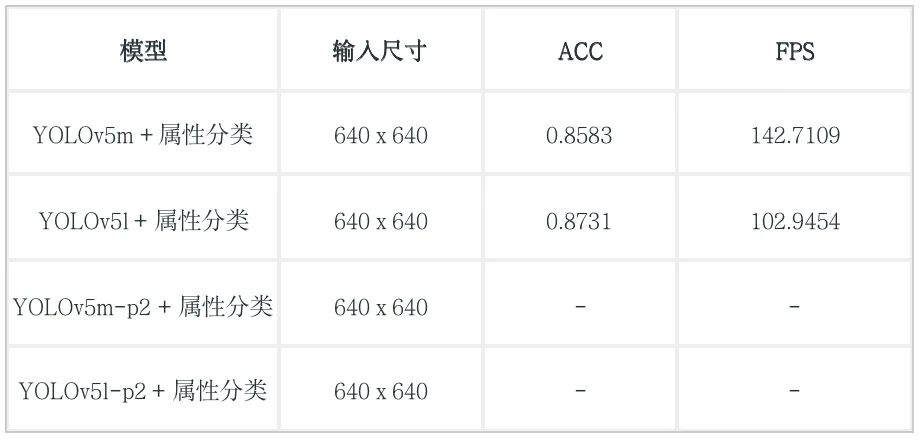
备注:由于p2模型的推理代码出了一点问题,因此有关p2的模型没有测试结果
可视化展示:
https://player.bilibili.com/player.html?bvid=BV1xe4y197pv
参考文献
https://github.com/ultralytics/yolov5
https://cvmart.net/community/detail/6179
Zhang Y , Sun P , Jiang Y , et al. ByteTrack: Multi-Object Tracking by Associating Every Detection Box[J]. ECCV, 2021.
https://github.com/ExtremeMart/ev_sdk_demo4.0_vehicle_plate_detection

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









