






公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
今天给大家分享的是关于特征工程的文章:数据的归一化和标准化。
数据的归一化和标准化都是对数据做变换,指通过某种处理方法将待处理的数据限制在一定的范围内或者符合某种分布。
它们都是属于特征工程中的
特征缩放过程。特征缩放的目的是
使得所有特征都在相似的范围内,因此在建模的时候每个特征都会变得相同重要。一般在建模的过程中,大多数模型对数据都要求特征缩放,比如
KNN、SVM、Kmeans等涉及到距离的模型,但是对决策树、随机森林等树模型是不需要进行特征缩放。
本文基于一份模拟的数据,介绍为什么及如何进行归一化和标准化:
线性归一化:通用的Normalization模式
均值归一化:Mean Normalization
标准化:Standardization(z-score)
模拟数据
导入相关的第三方库:
In [1]:
import pandas as pd
import numpy as np
import plotly_express as px
import plotly.graph_objects as go
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
np.random.seed(0)In [2]:
# 1、身高
# 样本数
sampleNo = 200
# 均值
mu = 170
# 标准差
sigma = 10
height = np.round(np.random.normal(mu, sigma, sampleNo),0)
height[:20]Out[2]:
array([188., 174., 180., 192., 189., 160., 180., 168., 169., 174., 171.,
185., 178., 171., 174., 173., 185., 168., 173., 161.])In [3]:
# 2、收入
salary = np.random.randint(100000,200000,sampleNo)
salary[:20]Out[3]:
array([195868, 186179, 111834, 182865, 162570, 173929, 156620, 183725,
147993, 167398, 166439, 195952, 115352, 164022, 190616, 189935,
114297, 105896, 112003, 173478])In [4]:
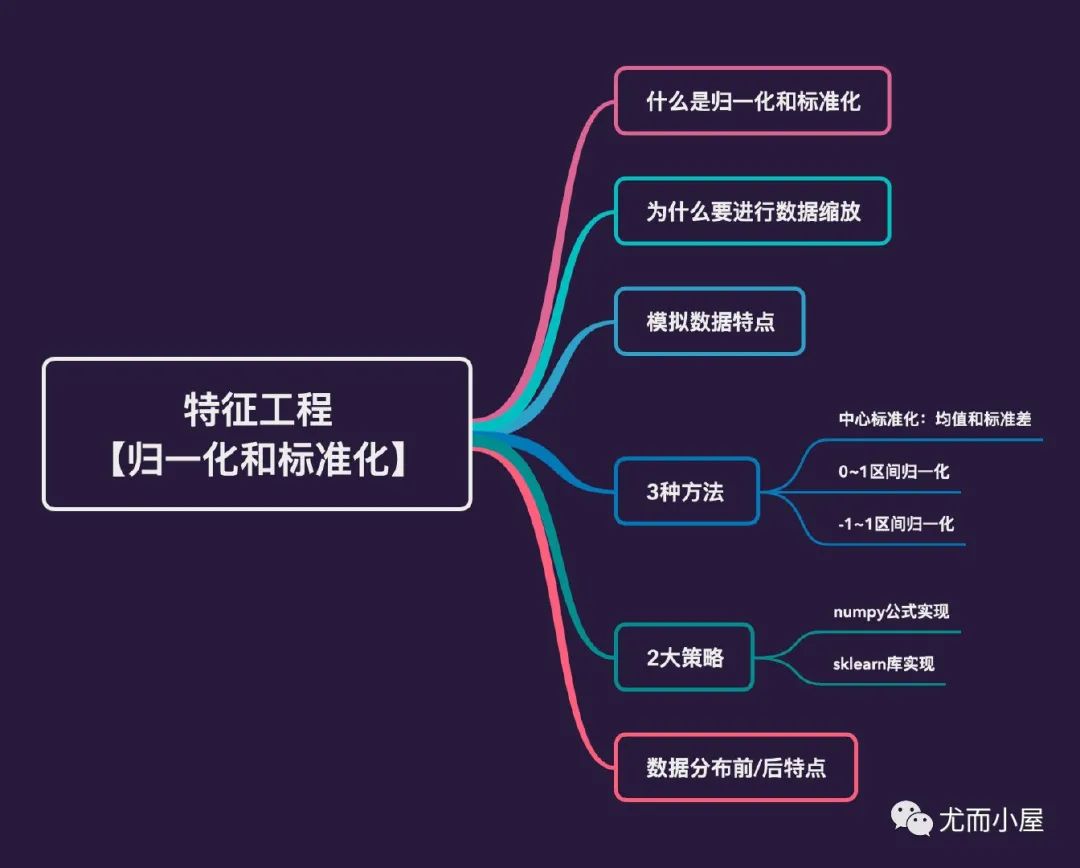
df = pd.DataFrame({"height":height,
"salary":salary
})
df.head()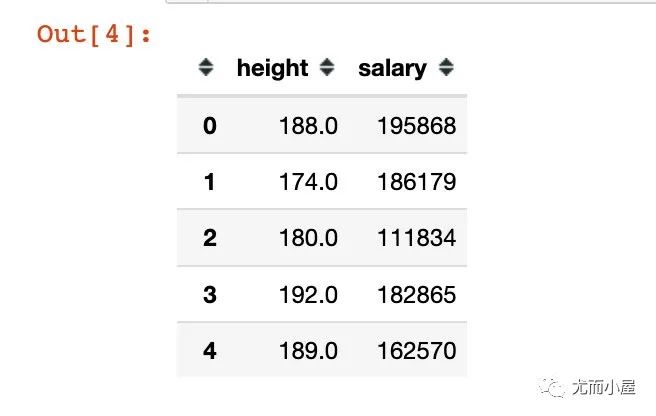
将上面的数据字段转成整型int:
df = df.astype(int) # 转成整型int
df.head()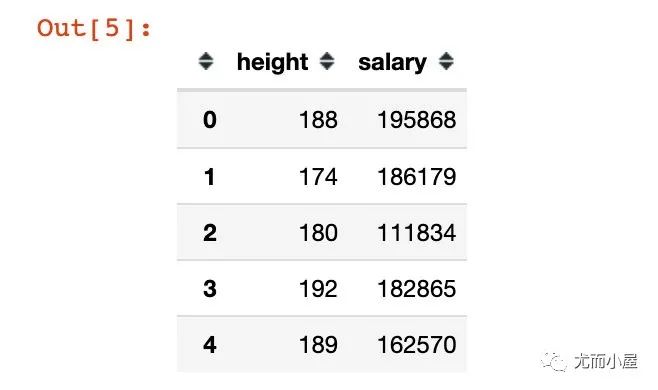
模拟的两个字段数据,height的数值明显比salary小,二者不在一个数量级,即:量纲是不同的。查看数据的描述统计信息:
# 描述统计信息
df.describe()
为什么需要归一化?
比如,当我们使用和距离相关的算法模型(KNN、k-means、SVM等)进行两个样本之间的欧式距离计算,此时salary的数值明显大于height的数值,求解的结果几乎取决于salary。
这样就会导致整个结果的值会过度依赖于salary。但是实际上,建模的过程中height和salary的重要性是一致的,因此在这种情况下,我们需要将两组数据的值缩放到相同的范围内,再进行计算和建模。
数据分布
身高height
In [7]:
fig = px.violin(df,x="height")
fig.show()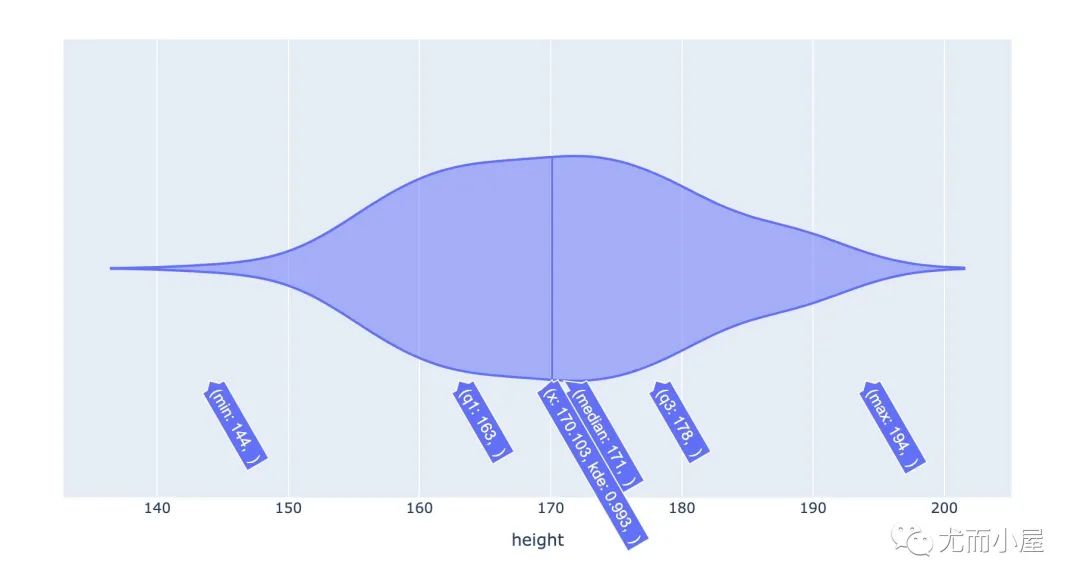
plt.hist(df["height"], 30)
plt.show()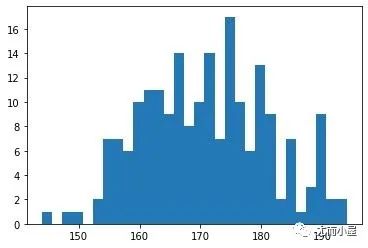
# 基于sns + y轴是频数
sns.histplot(data=df, x="height",bins=30)
plt.show()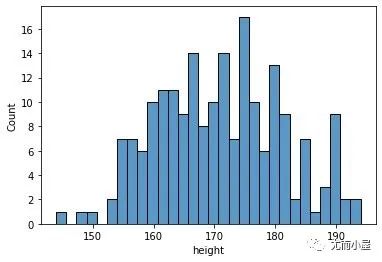
# 基于sns + y轴是概率
sns.histplot(data=df,
x="height",
bins=30,
kde=True,
stat="frequency")
plt.show()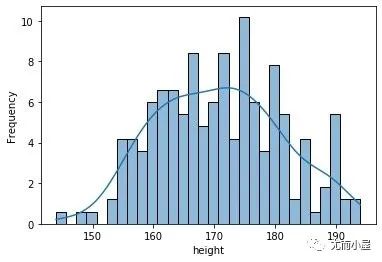
收入salary
In [11]:
fig = px.violin(df,x="salary")
fig.show()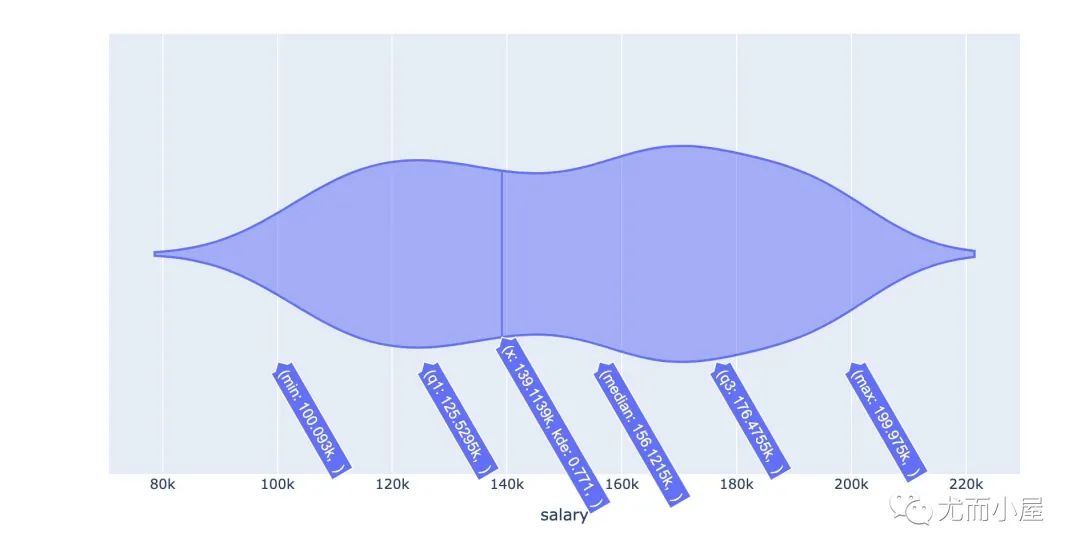
plt.hist(df["salary"], 20)
plt.show()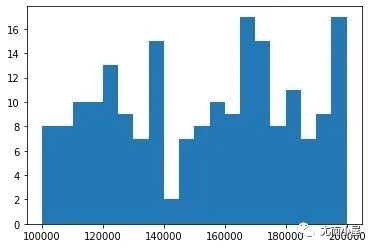
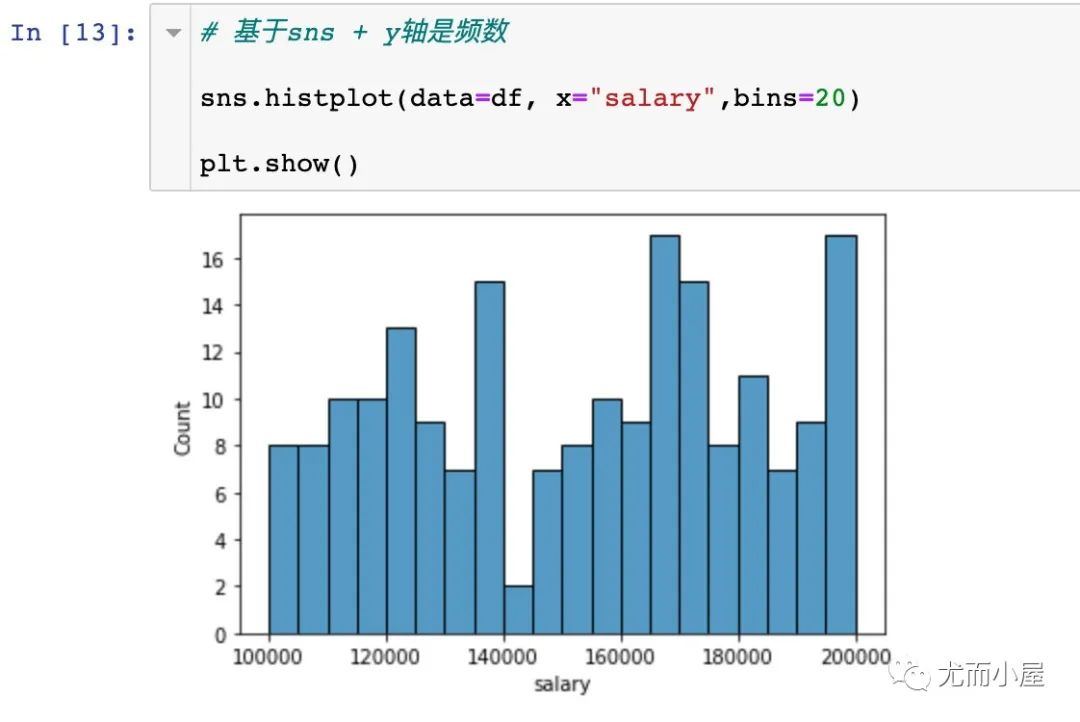
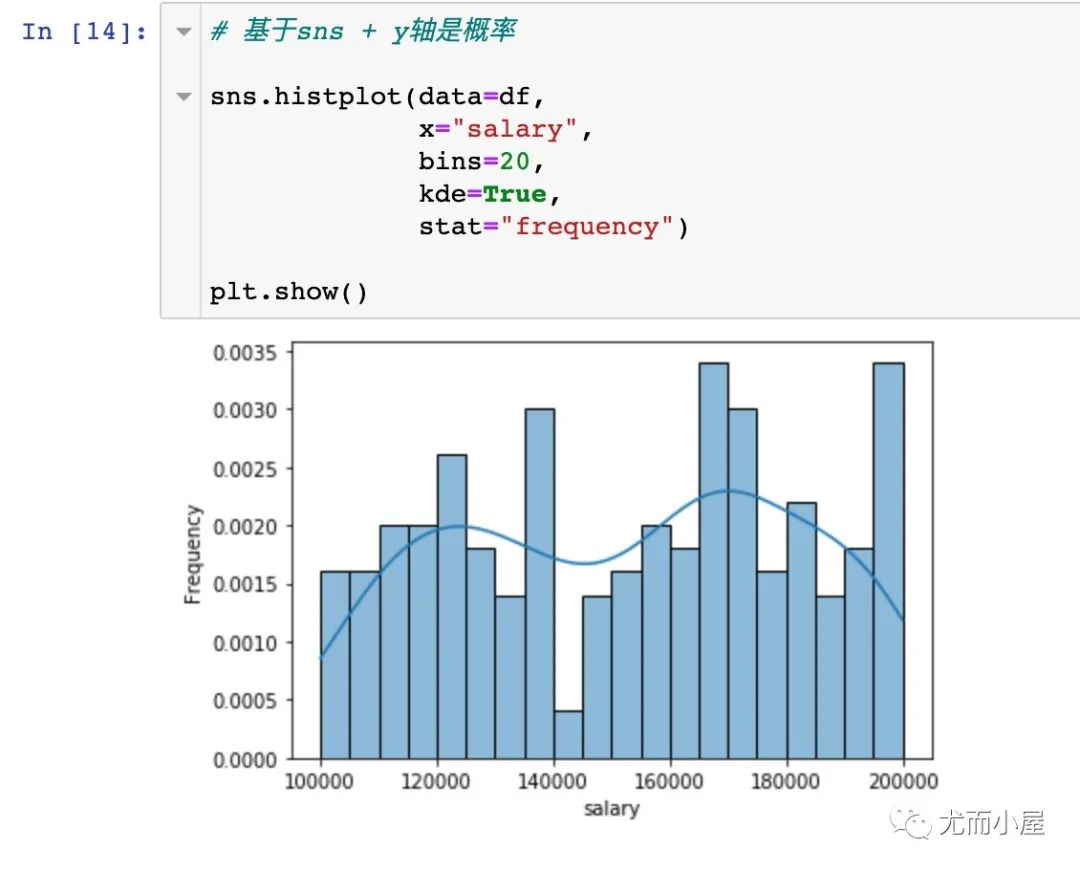
二者散点分布
基于两个字段的散点分布:
In [15]:
fig = px.scatter(df,x="height",y="salary")
fig.show()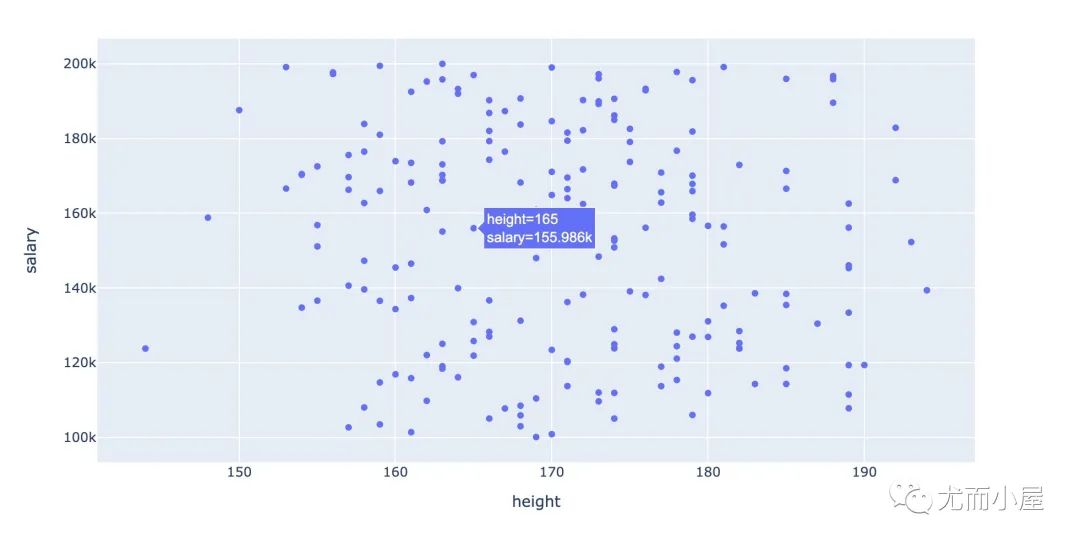
二者密度分布
In [16]:
身高取值的密度分布:
sns.distplot(df["height"], color="red",label="Height")
plt.show()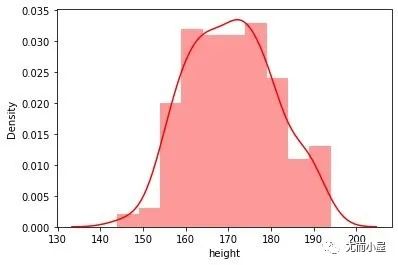
sns.distplot(df["salary"], color="blue", label="Salary")
plt.show()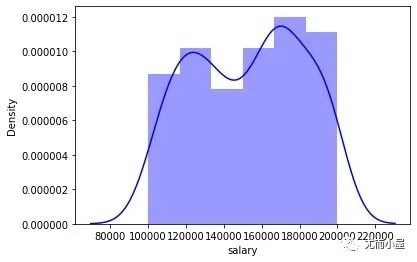
如果将两个字段的密度分布图放在一个画布中:
sns.distplot(df["height"], color="red",label="Height")
sns.distplot(df["salary"], color="blue", label="Salary")
plt.show()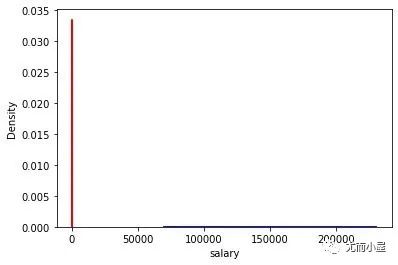
可以看到salary的密度值明显是小于height的密度。
标准化(中心标准化z-score)
中心标准化(Z-score normalization)的做法是将所有特征的数值被转化成为均值u为0、标准差std为1的正态分布。
要求原数据满足正态分布,实施变换后的数据也是满足正态分布的
用sklearn的StandardScaler模块也能实现。
1、首先对身高height进行标准化操作:
In [19]:
下面的操作是针对副本:
df1 = df.copy() # 副本In [20]:
mean_h = df1["height"].mean()
mean_hOut[20]:
170.71In [21]:
std_h = np.std(df1["height"])
std_hOut[21]:
10.218899157932816我们在创建数据的时候,均值是170,方差是10。与求出来的相比较:基本是一致的。
In [22]:
df1["height"] = df1["height"].apply(lambda x: (x - mean_h) / std_h)
df1.head()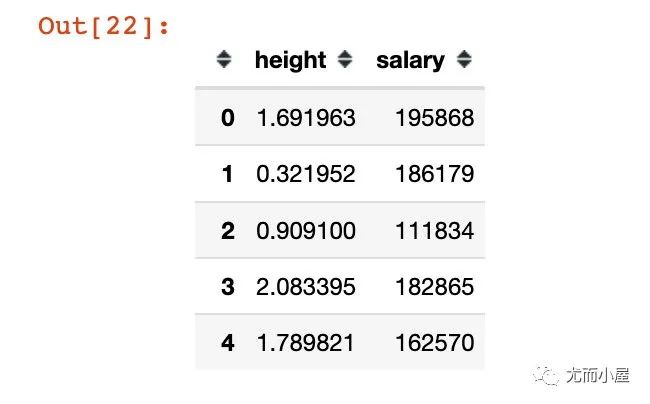
2、对收入salary进行同样的操作:
In [23]:
mean_s = df1["salary"].mean()
std_s = np.std(df1["salary"])In [24]:
df1["salary"] = df1["salary"].apply(lambda x: (x - mean_s) / std_s)
df1.head()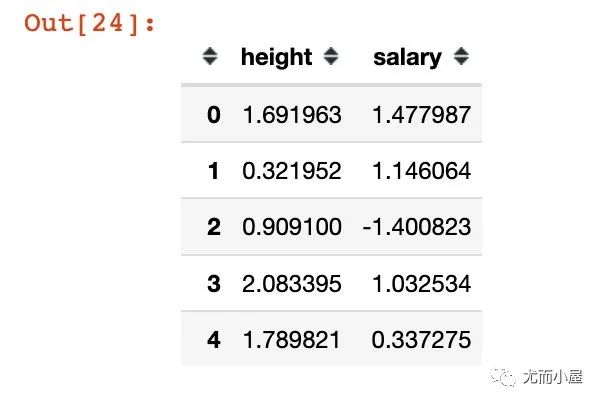
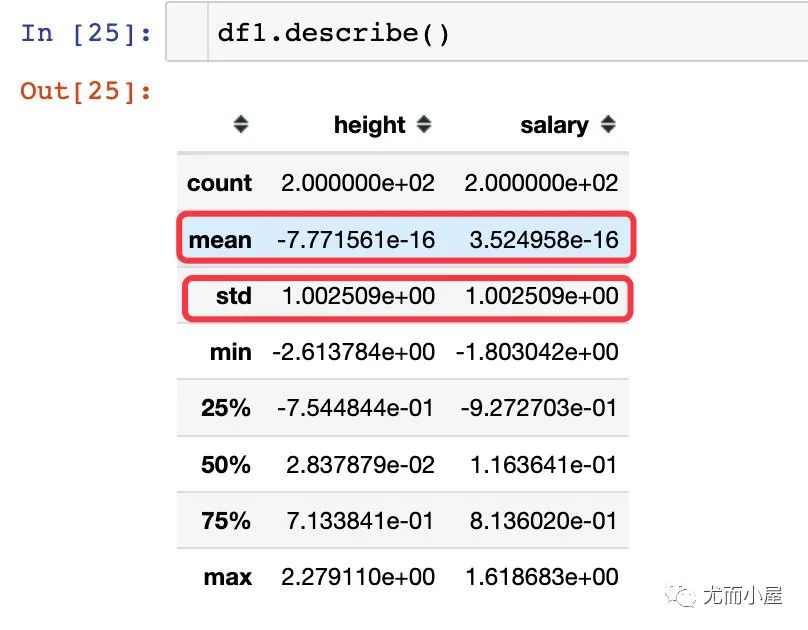
再次查看两个字段的描述统计信息:经过标准化之后,均值为0,标准差为1.
绘制标准化后的密度分布图:
sns.distplot(df1["height"], color="red")
sns.distplot(df1["salary"], color="blue")
plt.title("Z-Score Normalization")
plt.show()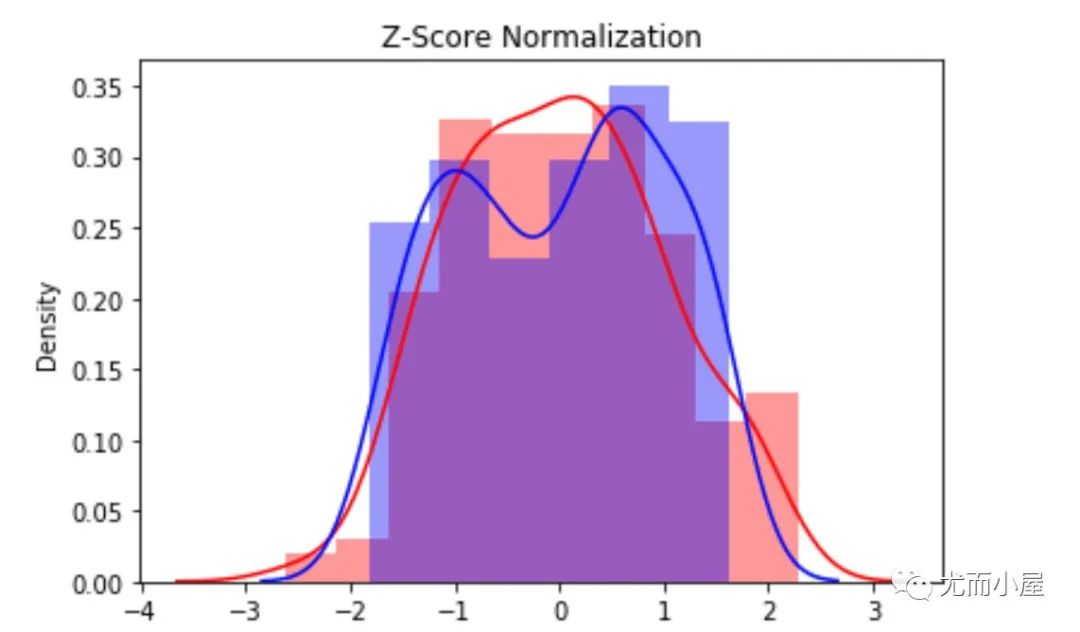
归一化
Max-Min:0-1之间
通过下面的公式进行转化:
对于每个特征,最小值被转化为0,最大值被转化为1。
In [27]:
df2 = df.copy() # 副本
max_h = max(df2["height"])
min_h = min(df2["height"])In [28]:
df2["height"] = df2["height"].apply(lambda x: (x - min_h) / (max_h - min_h)) # 实施缩放
df2.head()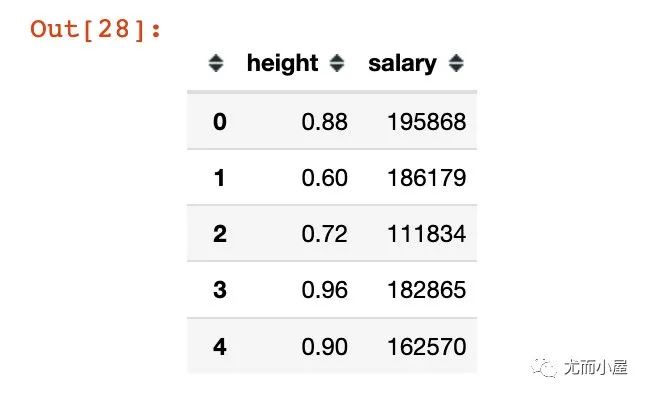
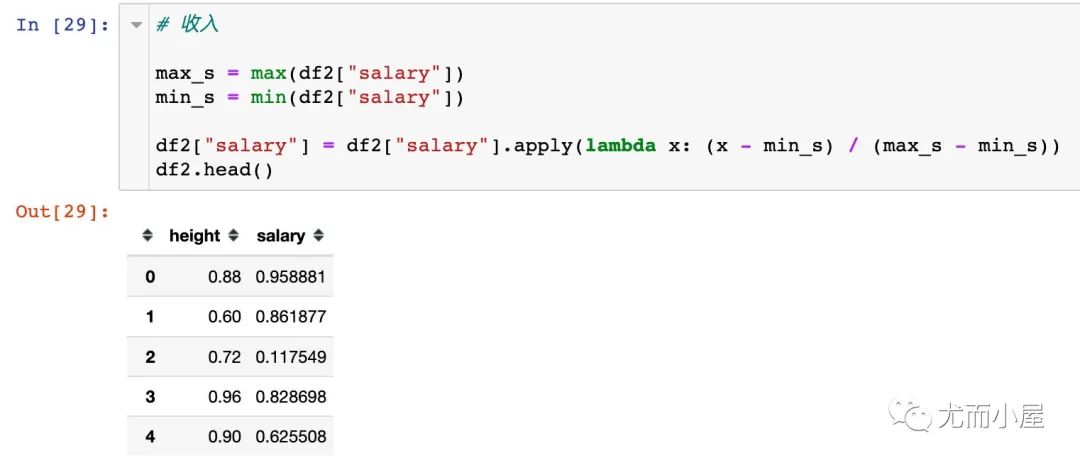
对salary实施相同的操作:
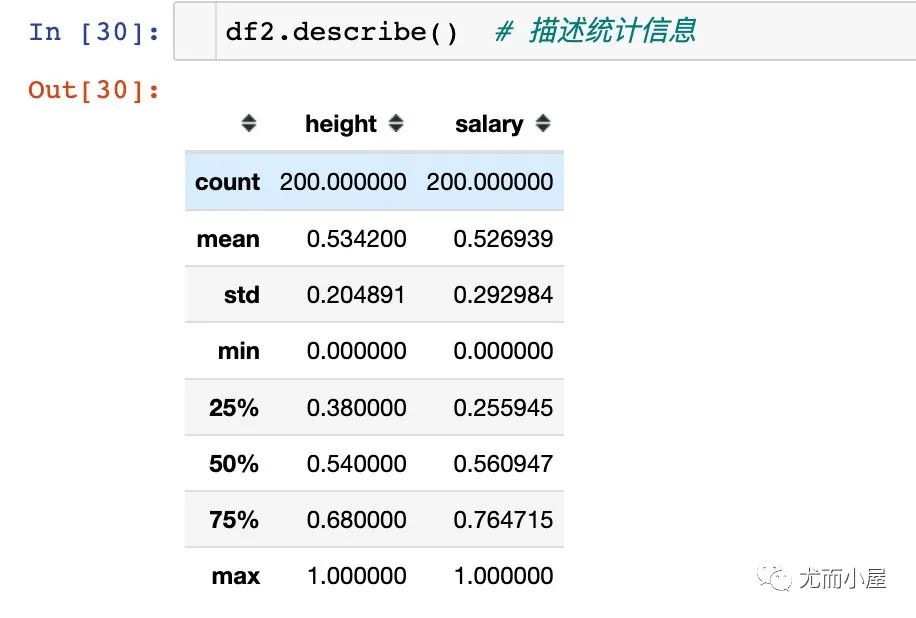
查看数据统计信息:
sns.distplot(df2["height"], color="red",label="Height")
sns.distplot(df2["salary"], color="blue", label="Salary")
plt.title("[0-1] Normalization")
plt.show()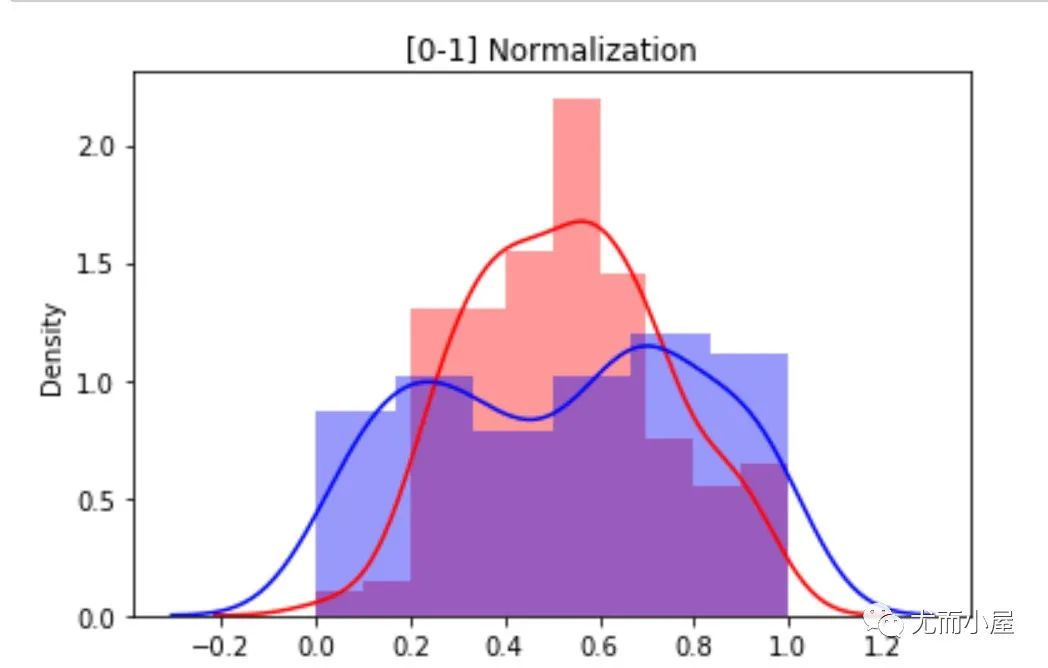
ax-Abs:-1-1之间
通过下面的公式进行转换
In [32]:
df3 = df.copy()In [33]:
minmax_h = max(abs(df3["height"])) # 选择绝对值大者
minmax_hOut[33]:
194In [34]:
df3["height"] = df3["height"].apply(lambda x: x / minmax_h)
df3.head()Out[34]:
| height | salary | |
|---|---|---|
| 0 | 0.969072 | 195868 |
| 1 | 0.896907 | 186179 |
| 2 | 0.927835 | 111834 |
| 3 | 0.989691 | 182865 |
| 4 | 0.974227 | 162570 |
In [35]:
minmax_s = max(abs(df3["salary"])) # 选择绝对值大者
df3["salary"] = df3["salary"].apply(lambda x: x / minmax_s)
df3.head()Out[35]:
| height | salary | |
|---|---|---|
| 0 | 0.969072 | 0.979462 |
| 1 | 0.896907 | 0.931011 |
| 2 | 0.927835 | 0.559240 |
| 3 | 0.989691 | 0.914439 |
| 4 | 0.974227 | 0.812952 |
In [36]:
sns.distplot(df3["height"], color="red",label="Height")
sns.distplot(df3["salary"], color="blue", label="Salary")
plt.title("[-1~1] Normalization")
plt.show()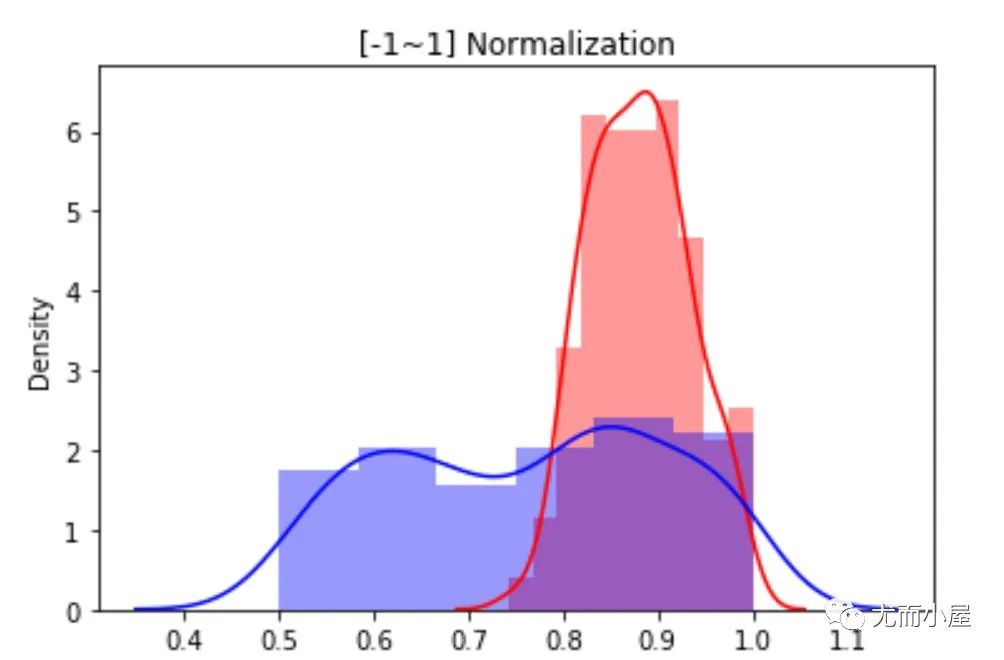
sklearn实现归一化和标准化
使用sklearn库也能够快速实现数据的归一化和标准化:
In [37]:
from sklearn import preprocessing方法1:StandardScaler
In [38]:
ss = preprocessing.StandardScaler()
ss_h = ss.fit_transform(df["height"].values.reshape(-1,1))
ss_h[:20]
ss_s = ss.fit_transform(df["salary"].values.reshape(-1,1))
sns.distplot(ss_h, color="red",label="Height")
sns.distplot(ss_s, color="blue",label="Height")
plt.title("StandardScaler()")
plt.show()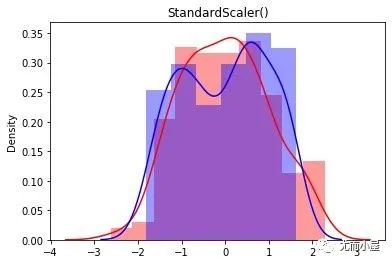
方法2:MinMaxScaler
In [40]:
mm = preprocessing.MinMaxScaler()
mm_h = mm.fit_transform(df["height"].values.reshape(-1,1))
mm_s = mm.fit_transform(df["salary"].values.reshape(-1,1))
# 绘制
sns.distplot(mm_h, color="red",label="Height")
sns.distplot(mm_s, color="blue",label="Height")
plt.title("MinMaxScaler()")
plt.show()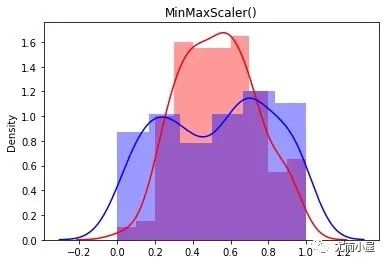
方法3:MaxAbsScaler
In [42]:
ma = preprocessing.MaxAbsScaler()
ma_h = ma.fit_transform(df["height"].values.reshape(-1,1))
ma_s = ma.fit_transform(df["salary"].values.reshape(-1,1))
sns.distplot(ma_h, color="red",label="Height")
sns.distplot(ma_s, color="blue",label="Height")
plt.title("MaxAbsScaler()")
plt.show()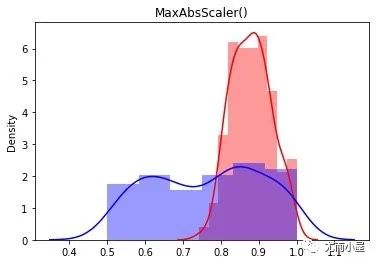
参考
https://www.zhihu.com/question/20467170
https://plotly.com/python/histograms/
https://scikit-learn.org/stable/modules/preprocessing.html
https://seaborn.pydata.org/generated/seaborn.histplot.html
https://blog.csdn.net/weixin_36604953/article/details/102652160

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









