






TLDR: 本文详细介绍了端侧推荐系统的最新进展情况,具体包括端侧推理与部署、端侧训练与更新以及端侧推荐系统的安全与隐私等部分。最后介绍了这一研究领域所面临的潜在挑战以及未来可期的研究主题等。

论文:https://arxiv.org/abs/2401.11441
推荐系统作为一种帮助在线用户有效地从海量数据中定位相关信息的重要技术,已经在许多应用领域得到了广泛应用,比如电子商务、多媒体平台、基于位置的服务等。通常,大多数现有的推荐系统都部署在云服务器上,这种范式的推荐模型可以以集中存储的方式进行训练和托管。云推荐系统(CloudRSs)的典型工作机制如图1(a)所示。
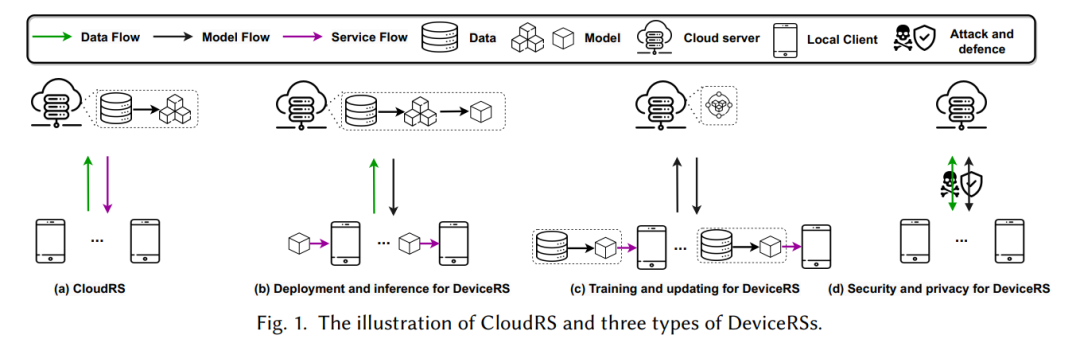
然而,由于这种工作流程的内在特点,其不可避免地存在以下局限性:
(1) 资源消耗高: 一方面,用户和物品相关的大量数据需要集中存储,包括用户-物品交互数据、用户和物品的特征以及模型的参数,如神经网络的权重和用户/物品嵌入等;另一方面,不断更新和训练模型以捕捉不断变化的用户偏好也大大增加了资源消耗。
(2) 响应延迟: 云推荐架构的另一个固有限制是由于通信开销导致的云和用户设备之间的响应延迟。例如,设备需要从服务端接收显示的结果,而有限的互联网连接或高流量周期可能会影响响应时间。此外,许多模型依赖历史数据而不是实时用户数据进行训练和预测,这通常导致无法捕捉用户偏好的实时变化。
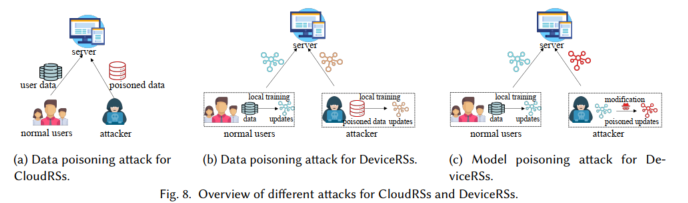
(3) 安全与隐私: 在数据中心保存所有用户数据可能会对数据安全和隐私造成风险。此外,随着欧洲的GDPR、美国的CCPA、中国的PIPL等数据保护法规的出台,用户对加强数据隐私保护的需求日益强烈。此外,云推荐范式很容易受到攻击,这些攻击可以操纵它们的输出,导致生成错误或有偏差的结果。
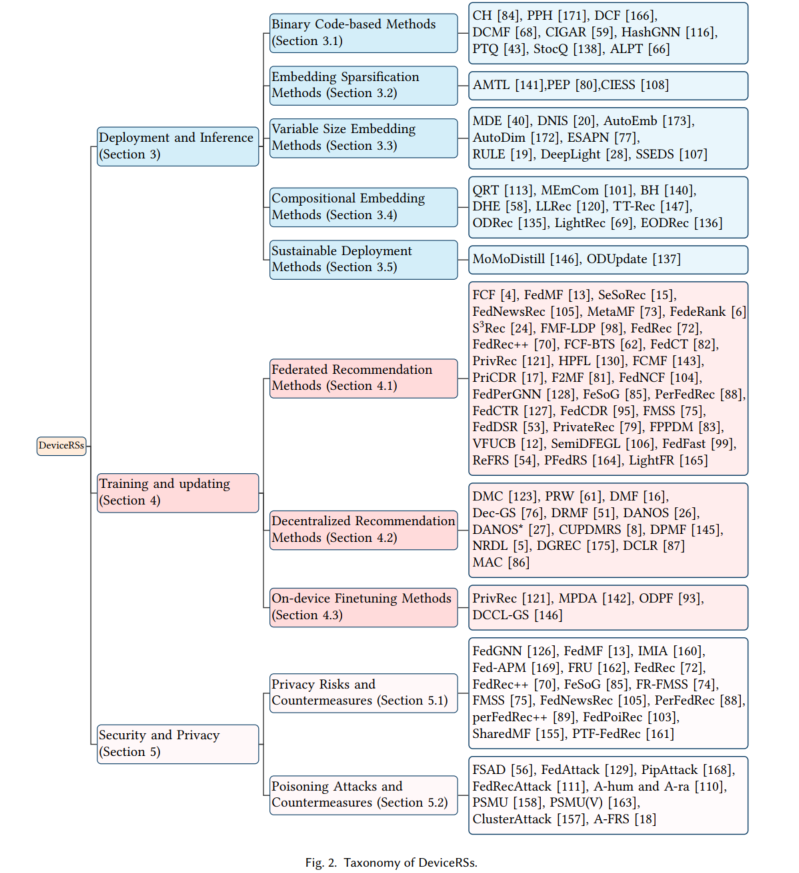
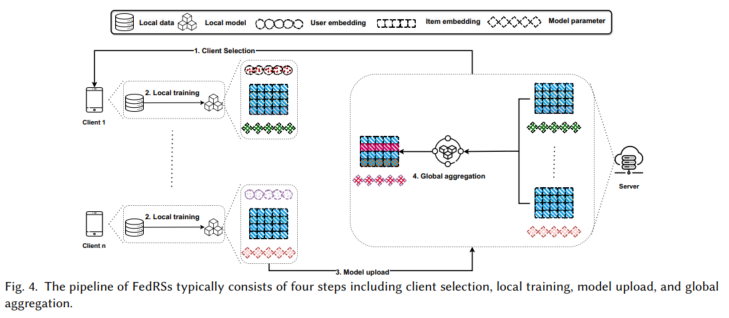
近年来,边缘计算技术飞速发展,其大大提升了在存储、通信和计算方面的能力。为此,一种全新的推荐范式——端侧推荐系统(on-device recommendation systems, DeviceRSs)被广泛研究,将所有或大部分的计算和存储操作从云服务器转移到用户的终端设备上,如手机、平板电脑、智能家居等。鉴于端侧推荐系统通过将模型部署在终端设备上,甚至推荐模型训练也下放到设备端来解决上述问题的能力,如淘宝的EdgeRec,谷歌的TFL Recommendation,以及快手的移动设备短视频推荐。具体来说,如图2中系统概述的那样,现有的端侧推荐系统可以分为三个大类,即端上推理与部署、端上训练与更新以及端上推荐系统的安全与隐私。
端侧推理与部署
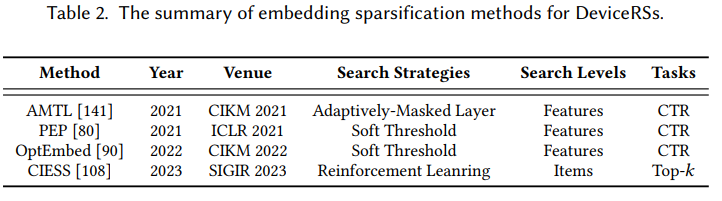
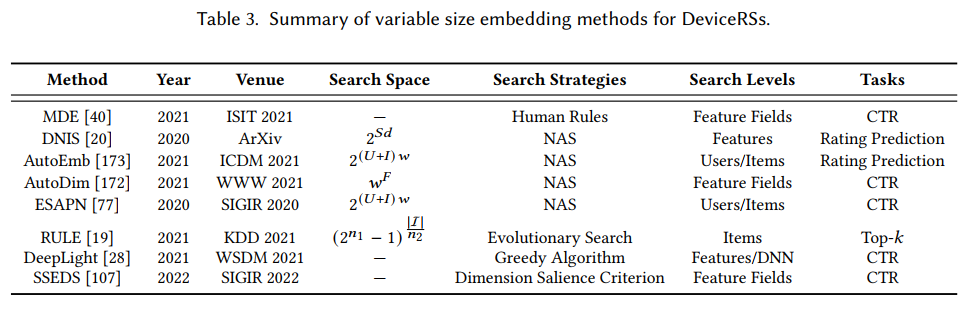
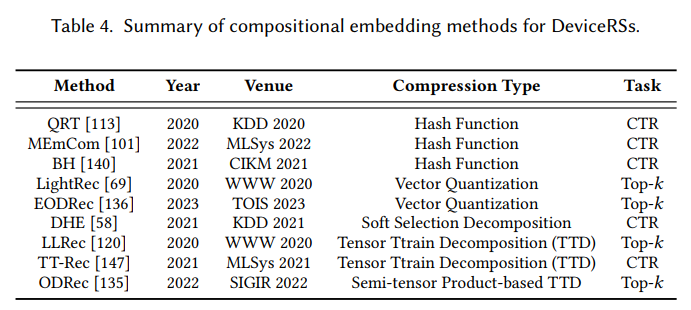
端侧推荐范式的部署和推理旨在在资源受限的设备上部署一个轻量级的推荐模型,如图1(b)所示。这使得推荐模型可以快速地在设备上进行模型推理,以此缓解资源消耗和响应延迟等问题。与这类方法相关的主要技术挑战是如何在压缩原始模型的同时尽可能地保持其性能。现有的方法可以进一步分为几种不同的类型,包括基于二进制代码的方法,嵌入稀疏方法,组合嵌入方法,可变大小的嵌入方法和可持续部署方法。具体方法的示意图如下图所示。
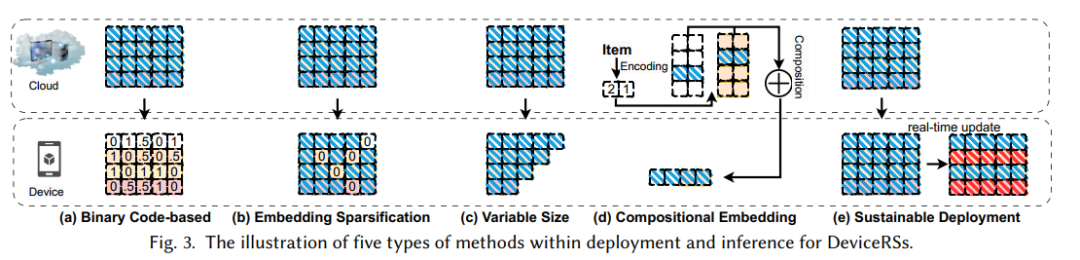
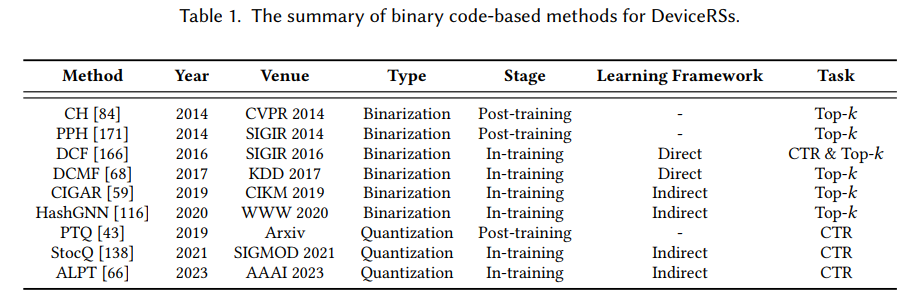
下文列举了每种大类方法经典的轻量化代表方法,比如基于二进制码的CH、PPH以及DCF等方法。嵌入稀疏方法中的AMTL以及PEP等方法,可变嵌入大小的MDE以及AutoDim等方法,组合嵌入中的DHE等方法。
端侧训练与更新
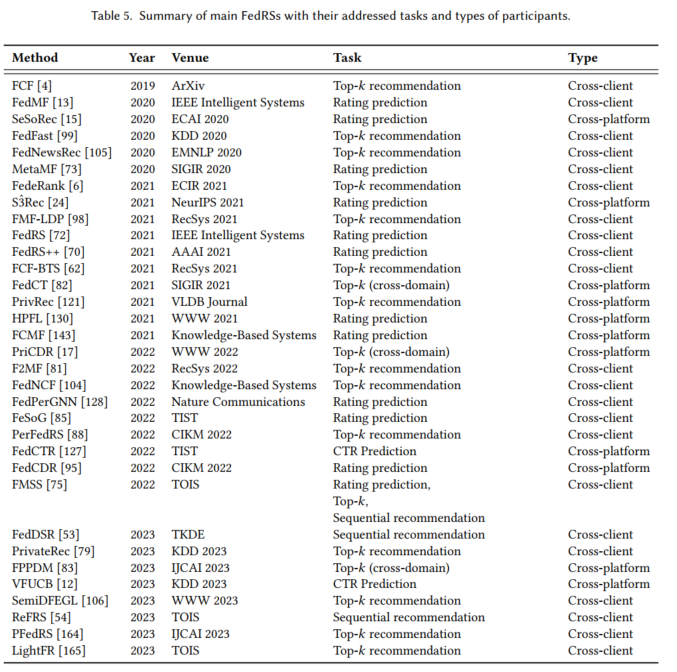
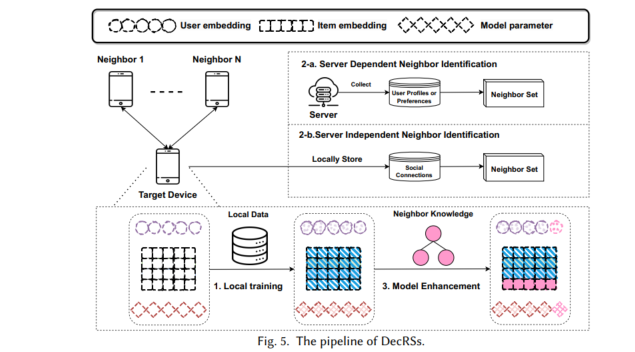
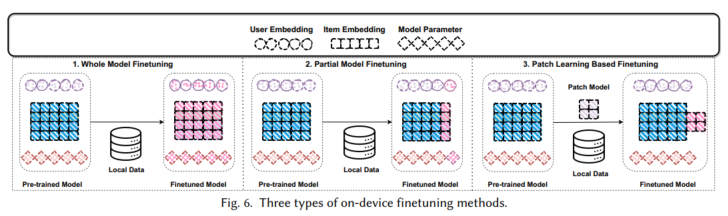
端侧训练与更新涉及通过利用本地存储的数据将训练过程转移到设备端,如图1(c)所示,从而缓解与数据上传过程相关的安全和隐私问题。此外,局部模型更新可以及时捕捉用户偏好的变化。然而,由于推荐系统固有的数据稀疏特性,每个设备上的训练数据通常是有限的,使得仅通过本地数据训练获得良好性能具有挑战性。为了解决这个问题,该领域中的一些方法涉及到一个中心服务器,它协调一组设备进行服务器和设备之间的协同训练(如联邦推荐系统),其他方法采用P2P协议在设备之间进行分布式的协同训练(分布式推荐系统)。最近,一些研究专注于通过使用本地数据进行微调,使云服务器上预训练的大型通用模型适应设备端的学习任务(端侧微调技术)。
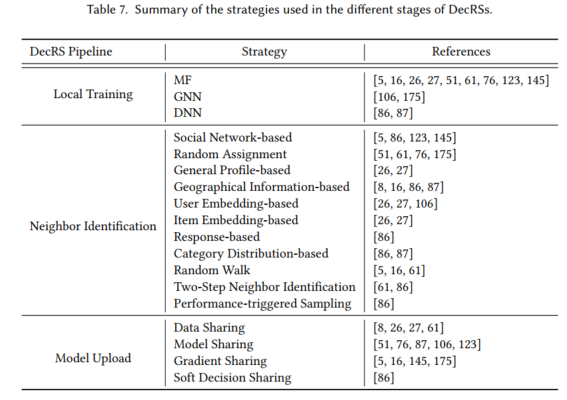
下文总结了联邦推荐系统、分布式推荐系统以及端侧微调技术的详细训练示意图以及代表性的方法。比如联邦推荐系统的FCF、FedMF等,分布式推荐系统的本地训练、模型更新等技术以及端侧微调中的全集微调与部分微调等技术。
端侧推荐系统的安全与隐私
端侧推荐系统的安全与隐私旨在保护用户和设备上的模型免受潜在的恶意攻击,如图1(d)所示。一方面,当本地模型有助于共享学习过程时,存在泄露用户敏感数据的风险。尽管直接的用户数据可能不会被共享,但对模型更新的复杂分析可能会泄露个人信息。在模型更新反映了推荐环境中独特的用户行为或偏好的场景中尤其如此。另一方面,由于系统依赖于来自用户设备的本地数据来训练和更新模型,因此攻击者有可能操纵这些数据或模型的学习过程。例如,攻击者可能会在本地数据集中引入有毒数据或对抗性输入,这可能会导致生成不准确或有偏差的推荐结果。
下文总结了端侧推荐范式存在的隐私和安全问题,具体包括用户行为数据泄露、用户敏感属性泄露以及用户数据的所有权等隐私问题,以及云推荐范式的数据中毒攻击、端侧推荐范式的数据中毒攻击与模型中毒攻击等。
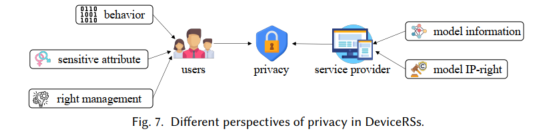
针对上述隐私泄露和攻击等问题,本文总结了隐私保护的技术手段,比如基于混淆的保护方法(数据混淆、模型混淆)、基于加密的保护方法(同态加密、秘钥共享、多方安全计算等)。
最后,本文总结了该领域潜在的研究问题,比如端侧推荐范式的异质性、公平性、用户动态演化、模型版权保护以及端侧推荐范式的基础模型等。
更多技术细节请阅读原始论文。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









