






在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求,模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:
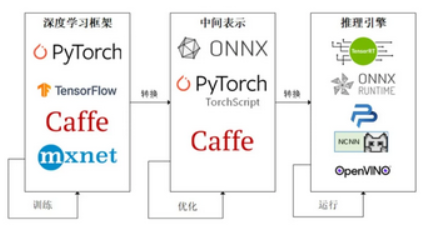
如上图,为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型,比如中间表示ONNX转换支持华为芯片推理的OM文件。
ONNX介绍
ONNX (Open Neural Network Exchange)是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。目前,在数家机构的共同维护下,ONNX 已经对接了多种深度学习框架和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。
图是由多个节点组成的,除输入和输出节点,每个节点表示一个算子,节点相互连接则形成有向无环图,静态图的含义是节点个数是确定的。
如下ONNX网络图:

输入节点名称:input
输出节点名称:values
算子节点:Conv、Sigmoid、Mul
箭头则表示网络图为有向无环图
构建ONNX图
现在我们通过ONNX库构建ONNX神经网络图。
构建神经网络图的流程图:

我们通过流程图编码实现基于ONNX的模型。
定义输入输出向量
import onnx
from onnx import helper
from onnx import TensorProto
# define tensor
input = helper.make_tensor_value_info('input', TensorProto.FLOAT, [1,3,256, 256])
roi = helper.make_tensor_value_info('roi',TensorProto.FLOAT,[])
scales = helper.make_tensor_value_info('scales',TensorProto.FLOAT,[4])
conv_input = helper.make_tensor_value_info('conv_input',TensorProto.FLOAT,[1,3,512,512])
conv_weight = helper.make_tensor_value_info('conv_weight',TensorProto.FLOAT,[32,3,3,3])
conv_bias = helper.make_tensor_value_info('conv_bias',TensorProto.FLOAT,[32])
conv_output = helper.make_tensor_value_info('conv_output',TensorProto.FLOAT,[1,32,512,512])
add_input = helper.make_tensor_value_info('add_input',TensorProto.FLOAT,[1])
output = helper.make_tensor_value_info('output',TensorProto.FLOAT,[1,32,512,512])通过make_tensor_value_info定义向量,参数分别表示:向量名称,向量类型和向量形状。如input向量名称是input,向量类型是TensorProto.FLOAT,向量大小是[1,3,256,256]。
构建节点
resize_node = helper.make_node("Resize",['input','roi','scales'],['conv_input'],name='resize')
conv_node = helper.make_node("Conv",['conv_input','conv_weight','conv_bias'],['conv_output'],name='conv')
add_node = helper.make_node('Add',['conv_output','add_input'],['output'],name='add')通过make_node构建节点,参数分别表示onnx算子,输入名称、输出名称和节点名称。如节点resize_node的onnx算子是Resize,输入名称是input,roi,scales,输出名称是conv_input,节点名称是resize。
构建图
graph = helper.make_graph([resize_node,conv_node,add_node],'resize_conv_add_graph',inputs=[input,roi,scales,conv_weight,conv_bias,add_input],outputs=[output])通过make_graph构建图,参数分别表示onnx节点,图名称,输入向量和输出向量
构建和检测模型
model = helper.make_model(graph) # 构建模型
onnx.checker.check_model(model) # 检测模型的准确性通过make_model构建模型,参数graph表示网络图,通过check_model检测构建的模型是否准确,参数model表示构建的模型。
保存模型
onnx.save(model, 'resize_conv_add.onnx')我们通过链接https://netron.app/可视化onnx模型。
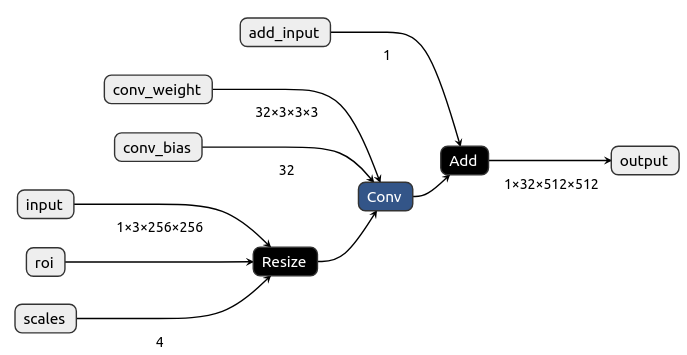
完成代码如下:
import onnx
from onnx import helper
from onnx import TensorProto
# define tensor
input = helper.make_tensor_value_info('input', TensorProto.FLOAT, [1,3,256, 256])
roi = helper.make_tensor_value_info('roi',TensorProto.FLOAT,[])
scales = helper.make_tensor_value_info('scales',TensorProto.FLOAT,[4])
conv_input = helper.make_tensor_value_info('conv_input',TensorProto.FLOAT,[1,3,512,512])
conv_weight = helper.make_tensor_value_info('conv_weight',TensorProto.FLOAT,[32,3,3,3])
conv_bias = helper.make_tensor_value_info('conv_bias',TensorProto.FLOAT,[32])
conv_output = helper.make_tensor_value_info('conv_output',TensorProto.FLOAT,[1,32,512,512])
add_input = helper.make_tensor_value_info('add_input',TensorProto.FLOAT,[1])
output = helper.make_tensor_value_info('output',TensorProto.FLOAT,[1,32,512,512])
# makenode
resize_node = helper.make_node("Resize",['input','roi','scales'],['conv_input'],name='resize')
conv_node = helper.make_node("Conv",['conv_input','conv_weight','conv_bias'],['conv_output'],name='conv')
add_node = helper.make_node('Add',['conv_output','add_input'],['output'],name='add')
# makegraph
graph = helper.make_graph([resize_node,conv_node,add_node],'resize_conv_add_graph',inputs=[input,roi,scales,conv_weight,conv_bias,add_input],outputs=[output])
# makemodel
model = helper.make_model(graph)
# checkmode
onnx.checker.check_model(model)
# print(model)
onnx.save(model, 'resize_conv_add.onnx')ONNX推理
我们使用推理引擎onnxruntime进行onnx推理。
完整代码如下:
"""
onnx推理
"""
import onnxruntime
import numpy as np
# 加载模型
weight_path = 'resize_conv_add.onnx'
session = onnxruntime.InferenceSession(weight_path) # 加载模型
# 获取输入节点名称
session.get_modelmeta()
input_name = session.get_inputs()[0].name
roi_name = session.get_inputs()[1].name
scales_name = session.get_inputs()[2].name
conv_weight_name = session.get_inputs()[3].name
conv_bias_name = session.get_inputs()[4].name
add_input_name = session.get_inputs()[5].name
output_name = session.get_outputs()[0].name
# 定义输入节点向量
input_data = np.random.randn(1,3,256,256).astype(np.float32)
roi_data = np.array([]).astype(np.float32)
scales_data = np.array([1,1,2,2]).astype(np.float32)
conv_weight_data = np.random.randn(32,3,3,3).astype(np.float32)
conv_bias_data = np.random.randn(32).astype(np.float32)
add_input_data = np.random.randn(1).astype(np.float32)
# 推理
input_dict = {input_name:input_data,roi_name:roi_data,scales_name:scales_data,conv_weight_name:conv_weight_data,
conv_bias_name:conv_bias_data,add_input_name:add_input_data}
result = session.run(None,input_dict) # 推理模型,输入向量采用字典类型表示
print('result[0]_shape=',result[0].shape)其中onnxruntime.InferenceSession加载模型,session.run推理输入数据,其中输入数据采用字典类型表示。
输出结果的大小:1,32,510,510
打印ONNX节点信息
有时候为了定位模型转换的问题,我们需要调试代码,以知道每个节点的信息。节点信息包括节点名称、输入向量的名称和大小、输出向量的名称和大小。
如下代码打印节点的名称、输入向量和输出向量名称。
# 加载ONNX模型
model_path = 'resize_conv_add.onnx'
onnx_model = onnx.load(model_path)
intermediate_layer_names = [onnx_model.graph.node[i].name for i in range(len(onnx_model.graph.node))]
print('node=',onnx_model.graph.node)
for node in onnx_model.graph.node:
print('node_name=',node)
print('node_input=',node.input)
print('node_output=',node.output)节点的输入输出向量大小可以通过可视化onnx进行估计,也可以通过指定输入向量的大小得到某个节点的输出向量大小。
完整代码:
"""
打印onnx节点信息
"""
import onnx
import onnxruntime as rt
import numpy as np
def get_layer_output(model, image):
inputs = []
outputs = []
for i,node in enumerate(model.graph.node):
if i>=1:
break
output = node.output[0]
input = node.input
inputs.append(input)
outputs.append(output)
model.graph.output.extend([onnx.ValueInfoProto(name=output)]) # 列表包含指定节点的输出变量
ort_session = rt.InferenceSession(model.SerializeToString(), providers=["CPUExecutionProvider"])
ort_inputs = {}
for i, input_ele in enumerate(ort_session.get_inputs()): # 获取输入节点和对应的输入向量
ort_inputs[input_ele.name] = image[i]
outputs = [x.name for x in ort_session.get_outputs()]
outputs = outputs[1:]
ort_outs = ort_session.run(outputs, ort_inputs) # 获取节点对应的输出向量
return inputs,outputs,ort_outs
# 加载ONNX模型
model_path = 'resize_conv_add.onnx'
onnx_model = onnx.load(model_path)
intermediate_layer_names = [onnx_model.graph.node[i].name for i in range(len(onnx_model.graph.node))]
print('node=',onnx_model.graph.node)
for node in onnx_model.graph.node:
print('node_name=',node)
print('node_input=',node.input)
print('node_output=',node.output)
#
input_data = np.random.randn(1,3,256,256).astype(np.float32)
roi_data = np.array([]).astype(np.float32)
scales_data = np.array([1,1,2,2]).astype(np.float32)
conv_weight_data = np.random.randn(32,3,3,3).astype(np.float32)
conv_bias_data = np.random.randn(32).astype(np.float32)
add_input_data = np.random.randn(1).astype(np.float32)
inputs,outputs,ort_outs = get_layer_output(onnx_model,[input_data,roi_data,scales_data,conv_weight_data,conv_bias_data,add_input_data])
print('output_node_shape=',ort_outs[0].shape)
# 结果
output_node_shape=(1,3,512,512)上述代码是打印resize节点的输出向量,定制化了代码,比较复杂。
实际工程项目上,我们也用不到。正确的模型部署流程是我们确认初始化模型是准确的,再转化为中间模型,这样会省事很多。
删除和新增ONNX节点
我们将中间onnx模型转换特定平台的文件时,会遇到特定平台不支持onnx算子的情况,那么需要删除该算子节点;或者遇到类型不匹配的情况,那么我们需要增加节点进行强制的类型转换。
删除onnx节点
原始ONNX网络图:
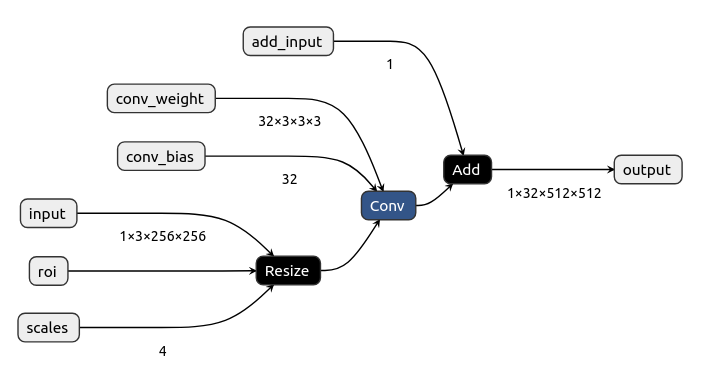
若我们删除Add的节点,那么就将Conv节点的输出连接到输出节点即可,同时需要删除图表Add节点的输入,代码:
def delete_add_node(nodes):
new_nodes = []
for node in nodes:
if node.name == "conv":
new_scale_node = onnx.helper.make_node(
"Conv",
inputs=['conv_input','conv_weight','conv_bias'],
outputs=['output'],
name="conv"
)
new_nodes += [new_scale_node]
elif node.name =='add':
continue
else:
new_nodes += [node]
return new_nodes
if __name__=='__main__':
model = onnx.load('resize_conv_add.onnx')
graph = model.graph
nodes = graph.node
opset_version = model.opset_import[0].version
graph_name = f"{graph.name}-int32"
new_nodes = delete_add_node(nodes)
graph_int32 = h.make_graph(
new_nodes,
graph_name,
graph.input[:-1], # 删除Add节点的输入向量
graph.output,
initializer=graph.initializer,
)
model_int32 = h.make_model(graph_int32, producer_name="onnx-typecast")
model_int32.opset_import[0].version = opset_version
ch.check_model(model_int32)
onnx.save_model(model_int32, "delete_add.onnx")可视化删除Add节点后的网络图:
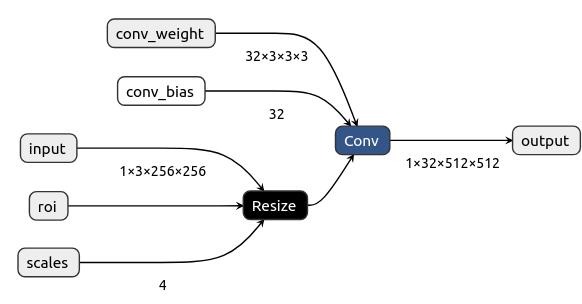
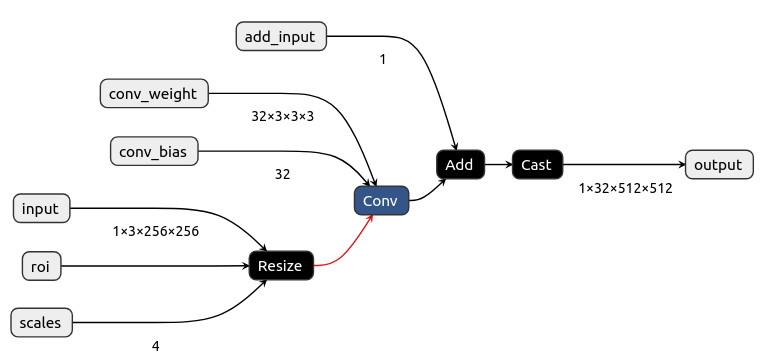
增加节点
若我们将Add节点后增加类型转换节点Cast,则需要将Cast节点的输入连接Add节点的输出,Cast节点的输出连接output,同时需要将输出节点的类型转换为Cast节点的输出类型。
代码:
"""
删除和新增onnx节点
"""
import onnx
from onnx import helper as h
from onnx import checker as ch
from onnx import TensorProto
def add_cast_node(nodes):
new_nodes = []
for node in nodes:
if node.name == "add":
new_scale_node = onnx.helper.make_node(
"Add",
inputs=['conv_output','add_input'],
outputs=['add_output'],
name='add')
new_add_node = onnx.helper.make_node(
'Cast',
inputs=['add_output'],
outputs=['output'],
name ='cast',
to= TensorProto.INT64
)
new_nodes += [new_scale_node, new_add_node]
else:
new_nodes += [node]
return new_nodes
if __name__=='__main__':
model = onnx.load('resize_conv_add.onnx')
graph = model.graph
nodes = graph.node
opset_version = model.opset_import[0].version
opset_version = 11
graph_name = f"{graph.name}-int32"
#new_nodes = delete_add_node(nodes)
new_nodes = add_cast_node(nodes)
graph.output[0].type.tensor_type.elem_type = 7
graph_int32 = h.make_graph(
new_nodes,
graph_name,
graph.input[:-1],
graph.output,
initializer=graph.initializer,
)
model_int32 = h.make_model(graph_int32, producer_name="onnx-typecast")
model_int32.opset_import[0].version = opset_version
ch.check_model(model_int32)
onnx.save_model(model_int32, "add_cast.onnx")onnx图:
pt模型转换onnx模型
本节开始涉及我们日常部署流程的第一步,将模型转换onnx模型。
通过函数torch.onnx.export将pt模型转onnx模型。
def export(model, args, f, export_params=True, verbose=False,training=TrainingMode.EVAL,input_names=None,output_names=None,aten=False, export_raw_ir=False,operator_export_type=None, opset_version=None, _retain_param_name=True,
do_constant_folding=True, example_outputs=None, strip_doc_string=True,
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,enable_onnx_checker=True, use_external_data_format=False):前三个必选参数为模型、模型输入、导出的 onnx 文件名,我们对这几个参数已经很熟悉了。我们来着重看一下后面的一些常用可选参数。
export_params
模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
input_names,output_names
设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。
ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。
在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
opset_version
转换时参考哪个 ONNX 算子集版本,默认为 9。
dynamic_axes
指定输入输出张量的哪些维度是动态的。
为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的
如下代码,根据Pytorch框架定义的模型转换onnx模型:
"""
自定义算子,同时看onnx实现pytorch算子的算法
"""
import torch
import torch.nn as nn
class Conv(nn.Module):
def __init__(self, in_ch=3,out_ch=32,kernel_size=3,stride=1,padding=1):
super(Conv, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.conv_module = nn.Sequential(
nn.Conv2d(in_channels=in_ch,out_channels=out_ch,kernel_size=kernel_size,stride=stride,padding=padding),
nn.BatchNorm2d(out_ch),
nn.SiLU()
)
def forward(self, img):
img1 = self.conv_module(img)
return img1
if __name__=='__main__':
conv_module = Conv()
img1 = torch.randn(5,3,640,640)
img2 = conv_module(img1)
print(img2.shape)
torch.onnx.export(conv_module, img1, "conv_module.onnx", input_names=["input"], output_names=["values"],opset_version=12)支持动态输入
我们通过参数dynamic_axes设置模型的动态输入。
dynamix_axes={'in':[2,3]} # 设置第2,3维为动态输入
torch.onnx.export(conv_module, img1, "conv_module.onnx",dynamic_axes=dynamix_axes,input_names=["input"], output_names=["values"],opset_version=12)自定义算子
在确保 torch.onnx.export() 的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。
在转换普通的 torch.nn.Module 模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
该算子可以一对一地翻译成一个 ONNX 算子。
该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
该算子没有定义翻译成 ONNX 的规则,报错。
若算子没有定义翻译成ONNX的规则时,我们需要定义算子的映射。根据我个人的经验,我不支持去扩展onnx算子,因为太复杂且非常耗时。
ATen是PyTorch内置的C++张量计算库,PyTorch算子在底层绝大多数计算都是用ATen实现的,现在我们开始如何定义算子的映射。
获取Aten算子接口定义。去 torch/_C/_VariableFunctions.pyi 和 torch/nn/functional.pyi搜索算子名。如asinh,对应的接口为def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
添加符号函数
onnx算子没有pytorch的asinh的映射规则,我们通过函数register_op将pytorch框架的asinh函数与onnx的Asinh算子进行映射,两个算子映射的输入向量和输出向量的维度和个数应一致。
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
from torch.onnx.symbolic_registry import register_op
def asinh_symbolic(g, input, *, out=None): # 定义onnx算子
return g.op("Asinh", input)
register_op('asinh', asinh_symbolic, '', 9) #注册,映射
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'asinh.onnx')结束语
这篇文章是自己在实际工作中总结出来比较重要的知识点,理解ONNX思想是解决模型部署问题的关键,希望对读者有用。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)


















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









