






2025 年,用这 15 款 Python 库构建各类强大应用。

在Python的技术生态中,丰富多样的库是其一大亮点,这些出色的库大大拓展了Python的应用边界,堪称改变编程格局的“利器”。当下,技术迭代日新月异,若想在2025年的编程领域中抢占先机,有几款极具变革性的现代库不容错过。
1 Polars——极速数据帧库
Polars是用Rust编写的超快速数据帧库,用于处理结构化数据。

优势:Polars比Pandas快10到100倍。支持对大型数据集进行延迟求值,并且能与Apache Arrow原生协作。
文档:https://docs.pola.rs/
安装:
pip install polars示例:以下是使用Polars创建数据帧的简单示例:
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)输出结果:
shape: (4, 4)
┌────────────────┬────────────┬────────┬────────┐
│ name ┆ birthdate ┆ weight ┆ height │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ date ┆ f64 ┆ f64 │
╞════════════════╪════════════╪════════╪════════╡
│ Alice Archer ┆ 1997-01-10 ┆ 57.9 ┆ 1.56 │
│ Ben Brown ┆ 1985-02-15 ┆ 72.5 ┆ 1.77 │
│ Chloe Cooper ┆ 1983-03-22 ┆ 53.6 ┆ 1.65 │
│ Daniel Donovan ┆ 1981-04-30 ┆ 83.1 ┆ 1.75 │
└────────────────┴────────────┴────────┴────────┘2 Ruff——最快的Python格式化和代码检查工具
Ruff是基于 Rust 语言编写的超快速代码检查工具,其设计初衷便是凭借自身强大功能,以 “一器之力” 取代 Flake8、Black 和 isort 这几款传统工具,为开发者提供更高效、便捷的代码检查与格式化解决方案 。
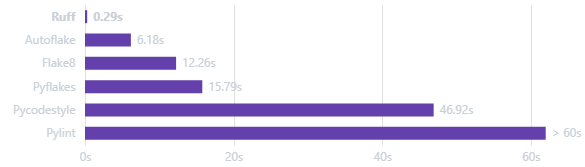
优势:它比Flake8快20倍,支持自动修复问题,兼具格式化和代码检查功能。
文档:https://docs.astral.sh/ruff/
安装:
pip install ruff示例:我们可以使用uv初始化一个项目:
uv init --lib demo这条命令会创建一个具有以下结构的Python项目:
demo
├── README.md
├── pyproject.toml
└── src
└── demo
├── __init__.py
└── py.typed然后,将src/demo/__init__.py的内容替换为以下代码:
from typing import Iterable
import os
def sum_even_numbers(numbers: Iterable[int]) -> int:
"""给定一个整数的可迭代对象,返回其中所有偶数的和。"""
return sum(
num for num in numbers
if num % 2 == 0
)接下来,将Ruff添加到项目中:
uv add --dev ruff然后,可以通过uv run ruff check在项目上运行Ruff代码检查:
$ uv run ruff check
src/numbers/__init__.py:3:8: F401 [*] `os` imported but unused
Found 1 error.
[*] 1 fixable with the `--fix` option.通过运行ruff check --fix自动解决这个问题:
$ uv run ruff check --fix
Found 1 error (1 fixed, 0 remaining).3 PyScript——在浏览器中运行Python
PyScript让开发者可以在浏览器中编写和执行Python代码,类似于JavaScript。
优势:PyScript支持开发基于Python的网页应用,可直接在HTML中使用,无需后端。
文档:https://docs.pyscript.net/2025.2.4/
安装:无需安装PyScript,只需在HTML文档的<head>标签中添加一个<script>和链接标签即可。
<!-- PyScript CSS -->
<link rel="stylesheet" href="https://pyscript.net/releases/2025.2.4/core.css">
<!-- 此脚本标签用于启动PyScript -->
<script type="module" src="https://pyscript.net/releases/2025.2.4/core.js"></script>示例:创建一个简单的.html文件,并使用<py-script>标签编写Python代码。
<!doctype html>
<html>
<head>
<!-- 推荐的元标签 -->
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<!-- PyScript CSS -->
<link rel="stylesheet" href="https://pyscript.net/releases/2025.2.4/core.css">
<!-- 此脚本标签用于启动PyScript -->
<script type="module" src="https://pyscript.net/releases/2025.2.4/core.js"></script>
</head>
<body>
<!-- 现在可以使用<py-script>标签在其中编写Python代码 -->
<py-script>
import sys
from pyscript import display
display(sys.version)
</py-script>
</body>
</html>4 Pandera——用于Pandas的数据验证工具
Pandera通过基于模式的验证方式,帮助验证Pandas的数据帧(DataFrames)和序列(Series)。

优势:Pandera可以在数据处理前捕获数据错误,工作方式类似于Pydantic,但专为Pandas设计,并且支持对数据进行单元测试!
文档:https://pandera.readthedocs.io/en/stable/
安装:
pip install pandera示例:
import pandas as pd
import pandera as pa
# 待验证的数据
df = pd.DataFrame({
"column1": [1, 4, 0, 10, 9],
"column2": [-1.3, -1.4, -2.9, -10.1, -20.4],
"column3": ["value_1", "value_2", "value_3", "value_2", "value_1"],
})
# 定义模式
schema = pa.DataFrameSchema({
"column1": pa.Column(int, checks=pa.Check.le(10)),
"column2": pa.Column(float, checks=pa.Check.lt(-1.2)),
"column3": pa.Column(str, checks=[
pa.Check.str_startswith("value_"),
# 定义自定义检查函数,该函数接受一个序列作为输入,并输出布尔值或布尔序列
pa.Check(lambda s: s.str.split("_", expand=True).shape[1] == 2)
]),
})
validated_df = schema(df)
print(validated_df)输出结果:
column1 column2 column3
0 1 -1.3 value_1
1 4 -1.4 value_2
2 0 -2.9 value_3
3 10 -10.1 value_2
4 9 -20.4 value_15 Textual——用Python构建终端用户界面应用程序
Textual允许开发者使用丰富的组件,用Python构建现代化的终端用户界面(TUI)应用程序。
优势:用于创建美观的终端应用程序,可与Rich库配合进行样式设置,无需前端开发经验。
文档:https://textual.textualize.io/tutorial/
安装:
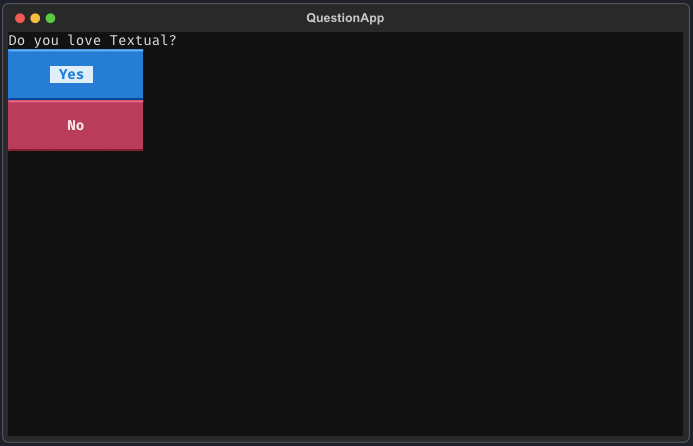
pip install textual示例:创建TUI应用程序的简单示例。
from textual.app import App, ComposeResult
from textual.widgets import Label, Button
class QuestionApp(App[str]):
def compose(self) -> ComposeResult:
yield Label("Do you love Textual?")
yield Button("Yes", id="yes", variant="primary")
yield Button("No", id="no", variant="error")
def on_button_pressed(self, event: Button.Pressed) -> None:
self.exit(event.button.id)
if __name__ == "__main__":
app = QuestionApp()
reply = app.run()
print(reply)运行此应用程序将得到以下结果:
6 LlamaIndex——构建定制AI助手
LlamaIndex简化了为基于大语言模型(LLM)的应用程序对大型数据集进行索引和查询的过程。
优势:LlamaIndex用于检索增强生成(RAG),可与OpenAI的GPT模型协同工作,并且能够处理结构化和非结构化数据。
文档:https://docs.llamaindex.ai/en/stable/#getting-started
安装:
pip install llama-index示例:让我们从一个简单示例开始,使用一个可以通过调用工具进行基本乘法运算的智能体。创建名为starter.py的文件:
设置一个名为
OPENAI_API_KEY的环境变量,并赋予其OpenAI API密钥。
import asyncio
from llama_index.core.agent.workflow import AgentWorkflow
from llama_index.llms.openai import OpenAI
# 定义一个简单的计算器工具
def multiply(a: float, b: float) -> float:
"""用于将两个数相乘。"""
return a * b
# 使用我们的计算器工具创建一个智能体工作流
agent = AgentWorkflow.from_tools_or_functions(
[multiply],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="You are a helpful assistant that can multiply two numbers.",
)
asyncdef main():
# 运行智能体
response = await agent.run("What is 1234 * 4567?")
print(str(response))
# 运行智能体
if __name__ == "__main__":
asyncio.run(main())运算结果:1234×4567的结果是5,678,678。
7 Robyn——最快的Python Web框架
Robyn是Flask和FastAPI的高性能替代框架,针对多核处理进行了优化。

优势: Robyn比FastAPI快5倍。支持异步和多线程,并且借助Rust提升速度。
文档:https://robyn.tech/documentation/en
安装:
pip install robyn示例:使用以下命令创建一个简单的项目:
$ python -m robyn --create产生以下输出:
$ python3 -m robyn --create
? Directory Path:.
? Need Docker? (Y/N) Y
? Please select project type (Mongo/Postgres/Sqlalchemy/Prisma):
❯ No DB
Sqlite
Postgres
MongoDB
SqlAlchemy
Prisma这会创建一个具有以下结构的新应用程序:
├── src
│ ├── app.py
├── Dockerfile现在你可以在app.py文件中编写代码:
from robyn import Request
@app.get("/")
async def h(request: Request) -> str:
return "Hello, world"可以使用以下命令运行服务器:
python -m robyn app.py8 DuckDB——闪电般快速的内存数据库
DuckDB是一个内存中的SQL数据库,在分析方面比SQLite更快。

优势:在分析方面速度极快,无需服务器即可运行,并且能轻松与Pandas和Polars集成。
文档:https://duckdb.org/docs/stable/clients/python/overview.html
安装:
pip install duckdb --upgrade示例:使用pandas数据帧的简单示例:
import duckdb
import pandas as pd
pandas_df = pd.DataFrame({"a": [42]})
duckdb.sql("SELECT * FROM pandas_df")输出结果:
┌───────┐
│ a │
│ int64 │
├───────┤
│ 42 │
└───────┘9 Django——全栈Web框架
Django是高级Python Web框架,用于快速构建安全、可扩展的应用程序。

优势:Django内置对象关系映射(ORM)、包含身份验证系统、具有可扩展性和安全性,还有更多优势。
文档:https://docs.djangoproject.com/en/5.2/
安装:
pip install django示例:创建一个新的Django项目:
django-admin startproject myproject
cd myproject
python manage.py runserver你应该会看到应用程序在http:127.0.0.1:8000/上运行。
10 FastAPI——高性能API框架
FastAPI是个轻量级且快速的Python Web框架,用于构建支持异步的RESTful API。

优势:内置异步支持、自动生成OpenAPI和Swagger UI,并且速度快(基于Starlette和Pydantic构建)。
文档:https://fastapi.tiangolo.com/learn/
安装:
pip install fastapi uvicorn示例:使用FastAPI创建API的简单示例:
# main.py
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"message": "Hello, FastAPI!"}运行服务器:
uvicorn main:app --reload你应该会看到应用程序在http:127.0.0.1:8000/上运行。
11 LangChain——人工智能驱动的应用框架
LangChain是Python框架,简化了与像OpenAI的GPT这样的大语言模型(LLM)的协作过程。

优势:LangChain可以与OpenAI、Hugging Face等集成,将多个大语言模型调用链接在一起,并且支持基于记忆和检索的查询。
文档:https://python.langchain.com/docs/introduction/
安装:
pip install langchain示例:使用OpenAI模型创建聊天机器人的简单示例:
pip install -qU "langchain[openai]"import getpass
import os
from langchain.chat_models import init_chat_model
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
model = init_chat_model("gpt-4o-mini", model_provider="openai")
model.invoke("Hello, world!")你会看到聊天机器人的回复。
12 Pydantic——数据验证与解析
Pydantic通过Python类型提示实现数据验证,在FastAPI中有着广泛应用。

优势:Pydantic具备自动数据验证功能,基于类型提示进行数据解析,与FastAPI搭配使用效果极佳。
文档:https://docs.pydantic.dev/latest/
安装:
pip install pydantic示例:
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
user = User(name="Aashish Kumar", age=25)
print(user) # User(name='Aashish Kumar', age=25)
print(user.name) # 'Aashish Kumar'
print(user.age) # 2513 Flet——用Python构建Web、移动和桌面UI
Flet仅使用Python就能构建现代化的Web、桌面和移动应用(无需HTML/CSS/JS )。

优势:无需掌握JavaScript或前端知识,可在Web、Windows、macOS和Linux等平台使用,是一款响应式UI框架。
文档:https://flet.dev/docs/
安装:
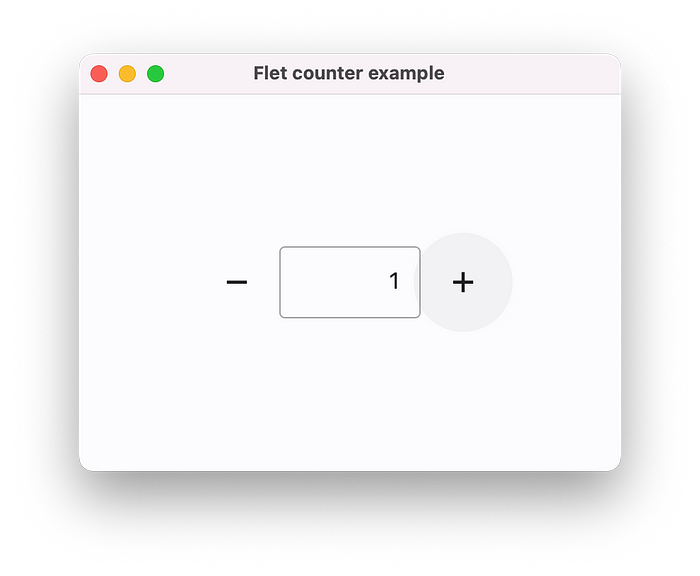
pip install flet示例:构建一个简单的计数器应用:
import flet
from flet import IconButton, Page, Row, TextField, icons
def main(page: Page):
page.title = "Flet counter example"
page.vertical_alignment = "center"
txt_number = TextField(value="0", text_align="right", width=100)
def minus_click(e):
txt_number.value = str(int(txt_number.value) - 1)
page.update()
def plus_click(e):
txt_number.value = str(int(txt_number.value) + 1)
page.update()
page.add(
Row(
[
IconButton(icons.REMOVE, on_click=minus_click),
txt_number,
IconButton(icons.ADD, on_click=plus_click),
],
alignment="center",
)
)
flet.app(target=main)运行程序:
python counter.py应用程序将在原生操作系统窗口中启动,这是替代Electron的不错选择。
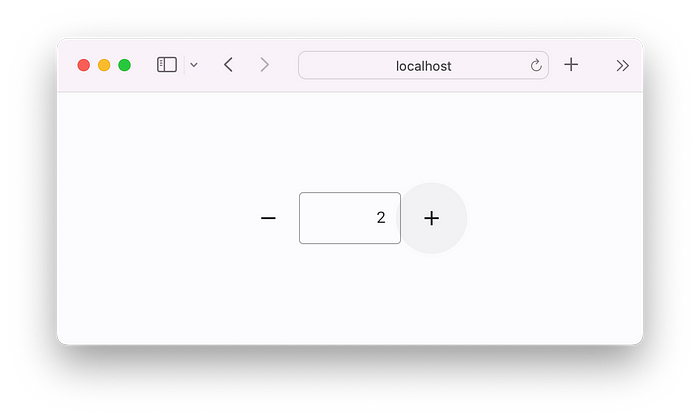
如果想将应用作为Web应用运行,只需将最后一行代码替换为:
flet.app(target=main, view=flet.AppView.WEB_BROWSER)再次运行,即可立即获得Web应用:
14 Weaviate——用于AI与搜索的向量数据库
Weaviate是一款快速的开源向量数据库,适用于语义搜索和AI应用。

优势:是人工智能驱动搜索的理想选择,可存储文本、图像和嵌入向量,能应对大规模数据集的需求。
文档:https://weaviate.io/developers/weaviate
安装:
pip install -U weaviate-client示例:使用Docker以默认设置运行Weaviate,在终端中运行以下命令:
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.29.0Docker实例默认运行在http://localhost:8080。
若要连接到本地实例且无需身份验证:
import weaviate
client = weaviate.connect_to_local()
print(client.is_ready())15 Reflex——用Python构建Web应用(前端+后端)
Reflex是一个全栈Web框架,用于使用Python构建现代化Web应用,与Streamlit类似,但可定制性更强。

优势:可以用Python构建类似React的用户界面,具备状态管理功能,前后端代码集成在一处。
文档:https://reflex.dev/docs/getting-started/introduction/
安装:
pip install reflex示例:使用以下命令创建一个Reflex项目:
mkdir my_app_name
cd my_app_name
reflex init创建简单应用:
# app.py
import reflex as rx
import openai
openai_client = openai.OpenAI()
# 后端代码
class State(rx.State):
"""应用程序状态。"""
prompt = ""
image_url = ""
processing = False
complete = False
def get_image(self):
"""根据提示获取图片。"""
if self.prompt == "":
return rx.window_alert("Prompt Empty")
self.processing, self.complete = True, False
yield
response = openai_client.images.generate(
prompt=self.prompt, n=1, size="1024x1024"
)
self.image_url = response.data[0].url
self.processing, self.complete = False, True
# 前端代码
def index():
return rx.center(
rx.vstack(
rx.heading("DALL-E", font_size="1.5em"),
rx.input(
placeholder="Enter a prompt..",
on_blur=State.set_prompt,
width="25em",
),
rx.button(
"Generate Image",
on_click=State.get_image,
width="25em",
loading=State.processing
),
rx.cond(
State.complete,
rx.image(src=State.image_url, width="20em"),
),
align="center",
),
width="100%",
height="100vh",
)
# 将状态和页面添加到应用程序
app = rx.App()
app.add_page(index, title="Reflex:DALL-E")运行开发服务器:
reflex run你会看到应用在http://localhost:3000运行。


















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









