







内存分配的重要因素: 速度。
不同 malloc 分配速度对比:
| malloc | 耗时 | 减少锁争用 | 空间效率 |
|---|---|---|---|
| ptmalloc2 | 300 ns | 线程 arena | 每个对象 4Bytes 头,大小四舍五入为 8 的倍数 |
| TCMalloc | 50 ns | 1. 小对象几乎没有争用 2. 大对象使用细粒度和高效的自旋锁 | 1% 空间开销 |
注: ptmalloc2 不能从一个 arena 移到另一个 arena
问题
- 为什么 TCMalloc 比 ptmalloc2 分配的速度快?
简介
TCMalloc 为每个线程分配线程本地缓存。
小对象:
TCMalloc 中 <= 32K 为小对象。
- 小对象从
Thread-local cache分配 - 分配时对象从
Central移到Thread-local cache - gc 周期性的将对象从
Thread-local cache移回Central
大对象:
- 大对象使用页级分配器从 Central 分配
- 页按 4K 对齐
页可被划分为一系列大小相等的小对象。例如:1页(4K)可分为 32 个 128 Bytes 的对象。

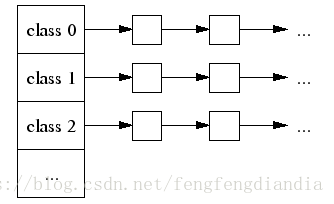
小对象分配
划分
- 按尺寸被映射为 170 个级别
- 尺寸按 8 bytes 分隔,较大的按 16 Bytes,再大些的按 32 Bytes,以此类推。最大间距为 256 Bytes(size >= 2K)
管理
- Thread Cache 包含每种尺寸级别的单链表
分配
- 根据分配的大小找到相应的尺寸级别
- 查看 Thread Cache 中相应的空闲列表
- 如果 Thread Cache 空闲列表非空
- 移除第 1 个对象并返回
- 如果 Thread Cache 空闲列表为空,查 Central 空闲列表
- 如果 Central 空闲列表非空
- 从 Central 空闲列表获取一堆该大小的对象(所有线程共享 Central)
- 将这些对象放到 Thread Cache 空闲列表
- 返回 1 个对象给程序
- 如果 Central 空闲列表为空
- Central 的页级分配器分配一系列页
- 将这一系列页分为该尺寸的对象
- 将新对象放到 Central 空闲列表中
- 将一些对象放到 Thread Cache 空闲列表
- 如果 Central 空闲列表非空
优点:这种方式分配 TCMalloc 不需要加锁。
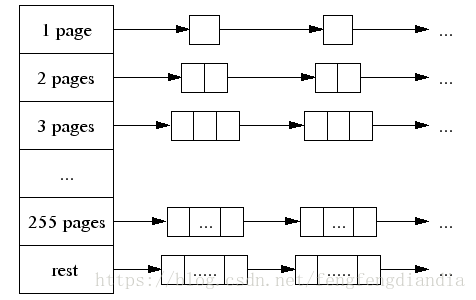
大对象分配
划分
超过 32K 的对象由 central page heap 管理,central page heap 是一个由 1~255 page + rest page 组成的空闲链表。
分配
- 如果分配 K页大小就找第 K 个空闲链表
- 如果该空闲列表为空就依次查找,直到最后一个
- 如果仍然为空,通过 sbrk,mmap 等方式从系统分配
- 如果 K页足够满足分配需求,将剩余的放回到相应的空闲列表中
Span
TCMalloc 所管理的heap是由 page组成,而page又是由Span对象组成。
Span 有两种状态已分配和空闲:
- 如果空闲,则在 page heap 空闲链表上
- 如果已分配,则被大小对象处理,尺寸记录在 span 中
span 属于哪个 page 可以通过 central 数组的页码索引找到。例如:span a 占 2 pages, span b 占 1 page, span c 占 5 pages,span d 占 3 pages.
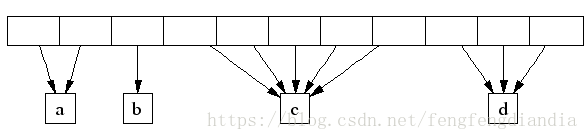
32 bit 地址空间可以容纳 2^20 个 4K 页面,共 4MB 空间。
释放
当一个对象要被释放时,我们计算页码并在 central 找到相应的 span 对象。
- 如果是小对象,则插入到 Thread Cache 的相应空闲列表中。
- 如果 Thread Cache 的空闲列表超过预定大小(默认 2M)则使用 gc 将对象移回 Central 的空闲列表中。
- 如果是大对象,判断对象的 page 覆盖范围,假设是 [p, q],还需查找 p-1 和 q+1,如果临近的 span 也是空闲的,则进行合并,然后插入到 page heap 相应的空闲列表中。
Central 空闲列表基本由两部分组成:
- 一组 span
- 每个 span 的空闲对象列表
class CentralFreeList {
private:
struct TCEntry {
void *head; // Head of chain of objects.
void *tail; // Tail of chain of objects.
};
Span empty_;
TCEntry tc_slots_[kMaxNumTransferEntries];
};















 5889
5889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









