






 Hana数据库利用Dictionary Encoding实现数据压缩,显著减少内存和磁盘空间。Dictionary Encoding通过创建字典存储不同值,并用Attribute Vector进行数据映射。在80亿行、200字节每行的数据集上,first name列经过压缩,压缩比例达到约94%。虽然需要考虑dictionary额外空间,但整体压缩效果仍然出色。
Hana数据库利用Dictionary Encoding实现数据压缩,显著减少内存和磁盘空间。Dictionary Encoding通过创建字典存储不同值,并用Attribute Vector进行数据映射。在80亿行、200字节每行的数据集上,first name列经过压缩,压缩比例达到约94%。虽然需要考虑dictionary额外空间,但整体压缩效果仍然出色。
Hana数据压缩:Dictionary Encoding
Hana的好处
- 在Hana中使用数据压缩技术,可以增加投资回报率,减少总体成本
- 数据压缩减少磁盘空间,但是Hana可以减少内存使用,带来更好的成本效益,Hana是一个内存平台
- 数据库压缩技术不是新的概念,许多数据库已经在使用,Hana独特之处是在内存中压缩算法,不想市场上的其他压缩系统。
- Hana大概可以压缩原数据大小到1/3
Dictionary Encoding
Dictionary Encoding是一种压缩技术,许多其他压缩技术都依赖于这种技术。

两个基本对象:
- dictionary
dictionary仅仅储值不同的值,可以在valueID列上创建索引 - Attribute Vector
Attribute Vector做原始表中的数据与Dictionary表的一对一映射,在position上创建索引。
举例说明
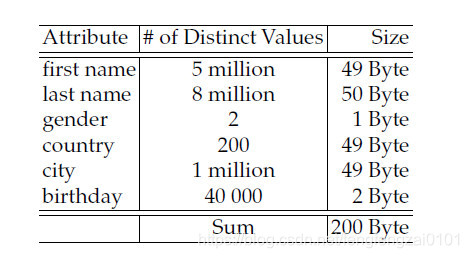
拥有80亿行的数据,每行数据是200字节,数据大小为:
8.000.000.000 x 200 = 1.6TB
以first name列为例做压缩,需要多少bits能够存储first name,这里使用二进制对数函数。
Log2(5.000.000) = 23
使用23bits可以存储49字节的first name列。
我们做一下数据压缩对比:
8.000.000.000 x 49 Bytes = 392.000.000.000 Bytes / 1024 / 1024 / 1024 = 365.1GB
vs
8.000.000.000 x 23 Bits = 184.000.000.000 Bits / 8 / 1024 / 1024 / 1024 = 21.4GB
压缩比例达到94%,当然我们也需要加上dictionary额外的空间
49 bytes x 5.000.000 / 1024 / 1024 / 1024 = 0.23GB
尽管这样,压缩比例也相当可观。
通过上面的方法可以作用于其他列。
总结:
- Dictionary Encoding压缩比例非常可观
- 压缩比例不仅依赖于数据类型,还依赖于拥有多少不同的值,数据集的大小

















 8558
8558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









