







先看效果:演示效果视频
双链表的好处就不提了,在linux内核中对链表的设计简直就是天才的设计,内核双链表与普通的链表不一样。
在普通的链表中,头尾指针与数据绑定在一起,即存放在同一个结构体中,创建每一个结点时就需要指明需要何种类型的数据这是无疑的,比如:
typedef struct line{
struct line * prior; //指向直接前趋
int data;
struct line * next; //指向直接后继
}line;
按照平常的学习顺序,接下来就是初始化节点、增删改查等了,增删改查的过程,需要通过line类型的结构体来操作前驱和后驱的指针,此时就决定了不同的结构类型则需要不同的操作函数,比如这次保存int数据是line类型结构体,当需要保存char型数据则需要另外的结构体类型,这就导致了所有的操作函数都要重写,非常麻烦。
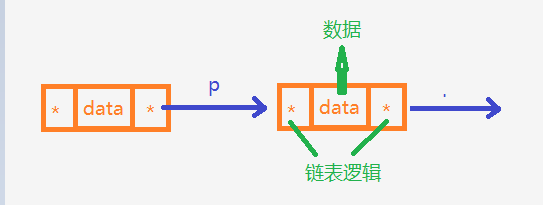
传统链表的节点不仅包含了表达链表逻辑的指针,更包含了某一种具体的数据,而关键是这些指针指向了整个节点,这就导致了无法将逻辑表逻辑与具体的数据分开,p是特殊的指针,不具有通用性。
linux内核链表则将链表中的链抽象出来,此时的链表单纯只包含前后指针,而不含有任何特殊的数据,这时候才是真正的链。此时如果要处理数据,只需要将链嵌入到数据里就行,对链表的增删改查则全都是对于链的操作,而与数据并无太大关系。
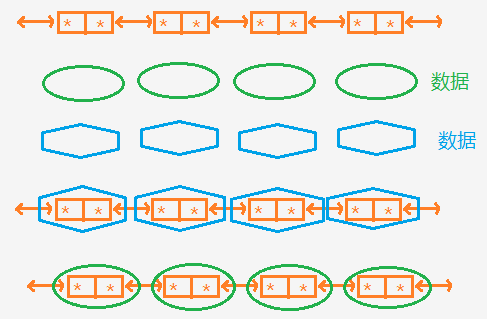
上面红色的为纯粹的链表,其只负责记录前后结点,对链表的操作相对就比较容易了,蓝色和绿色的则为数据。实际中我们想要的效果是,当将链表嵌入到数据后,对链表的操作在表层的体现仅仅是操作链表,而内层实则也对数据进行了操作,并且操作方法适用于不同类型数据的链表,换句话说,数据其实一直没有动过。内核双链表定义如下:
// 小结构体
// 构成纯粹的链表
typedef struct node{
struct node *next;
struct node *prev;
}listNode,*listNodePtr;
//数据结构体
typedef struct data{
int data;
char name[20];
listNode list;
}dataNode,*dataNodePtr;
想象一下,如果一个结点同时处于三个链表中该怎么实现?只需在该结点的dataNode中多定义两个链表结点就好了,并且在不同链表中,每一链表结点(小结构体)的操作都是一模一样的。
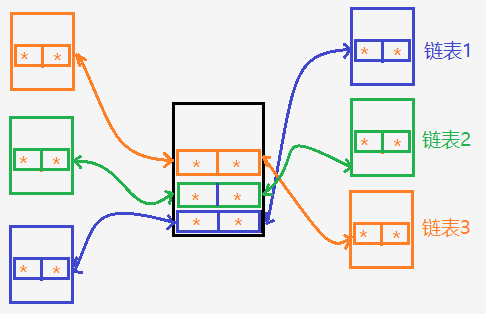
linux内核链表的突出优点是:由于可以非常方便地将其标准实现(即“小结构体”)镶嵌到任意结点,因此任何数据组成地链表的所有操作都被完全统一。另外在后期维护过程要对结点成员进行升级修改,也完全不影响该结点原有的链表结构。
初始化链表头结点,指向自己:
//写法一:
// 初始化标准结构体(小结构体),指向自己
#define INIT_LIST_NODE(ptr) do { \
(ptr)->next = (ptr); \
(ptr)->prev = (ptr); \
} while (0)
//写法二:
//初始化小结构体,内联函数,检测类型
#define LIST_HEAD_INIT(NAME) {&name,&name}
#define LIST_HEAD(name) (listNode name=LIST_HEAD_INIT(NAME))
static inline void INIT_LIST_HEAD(listNodePtr list)
{
list->next = list;
list->prev = list;
}
/*
listNode tmp;
INIT_LIST_HEAD(&tmp);
//等价于
listNode tmp = {&tmp,&tmp};
*/
插入操作,可插入到头结点之后或者头结点之前,传入参数是listNode类型的结构体,因此插入操作与大结构体没有任何关系:
static inline void __list_add(listNodePtr new,
listNodePtr prev, listNodePtr next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
// 将节点new,插入到链表head的末尾
// 即:插入到head的前面
static inline void list_add_tail(listNodePtr new,
listNodePtr head)
{
__list_add(new, head->prev, head);
}
// 将节点new,插入到链表head的首部
// 即:插入到head的后面
static inline void list_add(listNodePtr new, listNodePtr head)
{
__list_add(new, head, head->next);
}
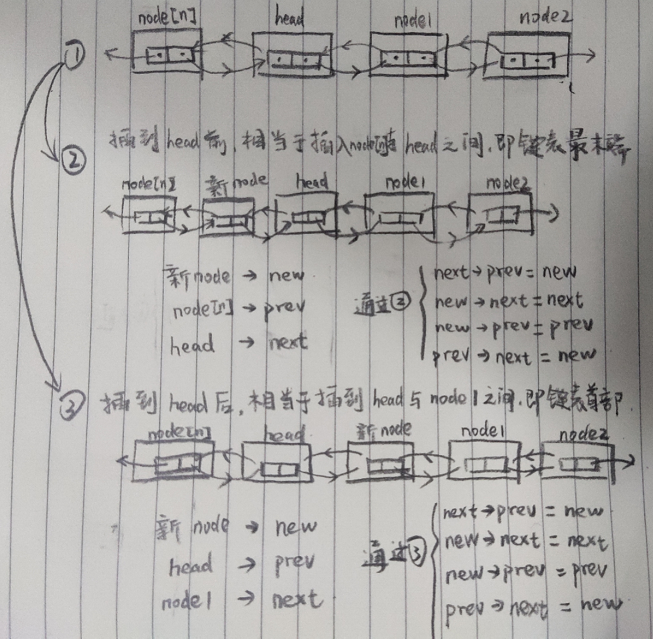
可以发现,不管是前插还是后插,最终通过③的计算是一样的,区别只在于传入的参数,即可完成前插或者后插的操作,并且,重点是!整个插入的过程均是链表结点之间的操作,与大的结构体没有任何关系!
删除操作,实际是将一个结点从链表中剔除,与传统链表的删除操作一样,只不过需要注意的是,即使在链表将该结点(小结构体)剔除整个链表,但是大结构通过malloc来的地址并没有释放掉,在后续操作函数中需要注意:
static inline void __list_del(listNodePtr prev, listNodePtr next)
{
//更改剔除结点的前后结点的指向
next->prev = prev;
prev->next = next;
}
// 将entry从链表中剔除出去
static inline void list_del(listNodePtr entry)
{
__list_del(entry->prev, entry->next);
entry->next = (void *) 0;
entry->prev = (void *) 0;
}
遍历操作,有多种遍历方法,遍历过程得到的每个结点,可以删除或不能删除,主要由是否传入一个临时结点进去进行缓冲而决定:
// 遍历算法1: 从head开始往后遍历每一个节点
// pos为每次遍历得到的小结构体指针,不可删除
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
// 遍历算法2: 从head开始往前遍历每一个节点
// pos为每次遍历得到的小结构体指针,不可删除
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
// 遍历算法3: 从head开始往后遍历每一个节点
// pos为每次遍历得到的小结构体指针,可删除节点
// n为临时存储变量,从调用处给入,不可操作
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
// 遍历算法4: 从head开始往后遍历每一个节点,并且直接获得大结构体的指针
// pos为每次遍历得到的大结构体指针,不可删除节点
// member为小结构体在大结构体中的名称,比如dataNode中的list
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
// 遍历算法5: 从head开始往后遍历每一个节点,并且直接获得大结构体的指针
// pos为每次遍历得到的大结构体指针,可删除节点
// n为临时存储变量,从调用处给入,不可操作
// member为小结构体在大结构体中的名称,比如dataNode中的list
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
上面遍历方法4和5中出现的list_entry也是一个链表操作函数,主要作用为从小结构体指针获取得到大结构体指针(结点的基地址),这一步是实现内核链表非常关键重要的一步,其定义如下:
// 从小结构体ptr,获得大结构体的指针
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(size_t)(&((type *)0)->member)))
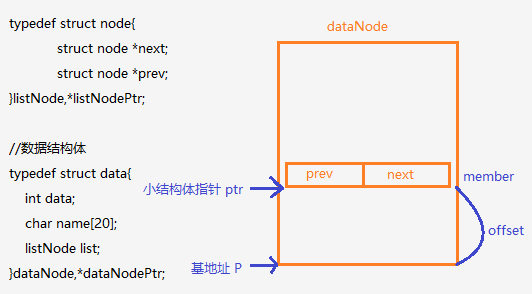
回顾前面对链表的操作,唯一只涉及到 listNodePtr 指针(即小结构体),链表的相连也都是靠 listNodePtr 记录 listNodePtr 来实现的(并不是记录大结构体的地址),因此 listNodePtr 才是重点。如上图,基地址P是dataNode类型结构体的首地址,member为小结构体在大结构体中的成员们(即list),如果我们要从 ptr 访问到大结构体中的数据,就得先求出大结构体基地址 P,实际求出偏移量 offset 即可。
比如,对于以下结构体进行计算
//先定义一个大结构体
dataNode tmp;
//两种方式可得到 ptr 地址为
ptr = &tmp->list
ptr = &tmp + offset
//等式代换得
offset = &tmp->list - &tmp
- 实际中&tmp并不重要,它是通过malloc申请得到的内存
- 有无数个结点申请,都会有对应的&tmp
- 但唯一不会改变的是tmp与tmp.list之间的地址差值offset
- 也就是说,tmp地址的改变,并不会影响到offset的值
如果假如tmp的地址为0,那么刚好ptr的地址就为offset,如果tmp的地址为1,那么此时ptr的地址就为(offset+1),以此类推,说白了就是tmp的地址不会对offset的值产生任何影响,为了计算方便,直接当作0地址来计算:
offset = &(0)->list - (0) = &(0)->list
//上式的0为数学上的0,需要转换为大结构体类型
offset = &((type *)0)->list
//此时offset还是一个链表节点类型的指针,需要转为整形表示字节数
offset = (size_t)(&((type *)0)->list)
offset的值得到了,可发现,只要通过大结构体的类型(并不是大结构体地址,比如dataNode)和小结构体在其中的成员名称(即list),就可以得到在该大结构体中,基地址与小结构体地址之间的差值了(单位为字节)。
//求大结构体的基地址
P = ptr - (size_t)(&((type *)0)->list)
//为了使ptr运算时将offset作为字节偏移量来对待
//需转为(char *)类型,即指针每移动一次步长为1字节
P = (char *)ptr - (size_t)(&((type *)0)->list)
//此时得到的P为大结构体真正的地址,但是没有类型指明,需要转换
P = (type *)((char *)ptr - (size_t)(&((type *)0)->list))
完结撒花,因此通过以下宏,即可从小结构体指针得出大结构体指针:
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(size_t)(&((type *)0)->member)))
如果还不能理解,可以再通俗一点,已知指针移动的步长与它的类型有关(比如int * 指针加1就移动4字节,char * 加1就移动1字节)。
(c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









