










最近准备了两篇文章,主要是针对MOM中的关键技术zero copy(物理层面和逻辑层面)进行一些介绍。
在基于文件存储的MOM Kafka,ActiveMQ以及其它诸如Hornetq,Kestrel中的Journal设计实现中,无不见zero copy的神威。为此我准备了一个系列文章,希望能够为大家解开zero copy的神秘面纱,也希望大家能够喜欢。
这篇文章主要聚焦在zero copy的基础部分。首先通过E文导读来理解其内在原理,理解为什么zero copy能够提升一些IO密集型应用的性能,为什么能够将上下文切换从4次降到2次,数据copy从4次降低到3次(注:只有一次会占用CPU cycle)?其次,简单介绍下Java世界,尤其是Netty中的zero-copy的设计实现。最后通过几篇扩展阅读,开阔一下视野,带领大家了解一下国外同行在zero copy上的一些技术性研究及其成果。OK,开篇~
Zero copy View
下面,我们以数据传输为例,来重点分析一下传统与零拷贝传输方式:
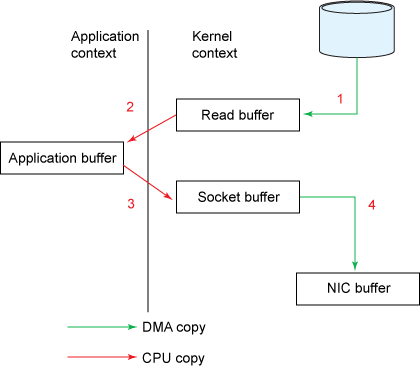
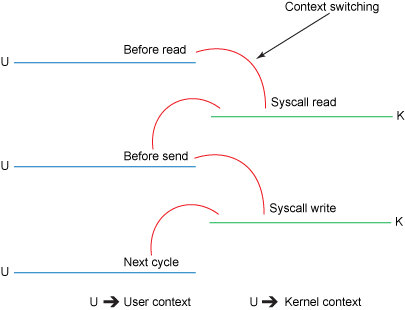
The read() call causes a context switch (see Figure 2) from user mode to kernel mode. Internally a sys_read() (or equivalent) is issued to read the data from the file. The first copy (see Figure 1) is performed by the direct memory access (DMA) engine, which reads file contents from the disk and stores them into a kernel address space buffer.
The requested amount of data is copied from the read buffer into the user buffer, and the read() call returns. The return from the call causes another context switch from kernel back to user mode. Now the data is stored in the user address space buffer.
The send() socket call causes a context switch from user mode to kernel mode. A third copy is performed to put the data into a kernel address space buffer again. This time, though, the data is put into a different buffer, one that is associated with the destination socket.
The send() system call returns, creating the fourth context switch. Independently and asynchronously, a fourth copy happens as the DMA engine passes the data from the kernel buffer to the protocol engine.
Use of the intermediate kernel buffer (rather than a direct transfer of the data into the user buffer) might seem inefficient. But intermediate kernel buffers were introduced into the process to improve performance. Using the intermediate buffer on the read side allows the kernel buffer to act as a "readahead cache" when the application hasn't asked for as much data as the kernel buffer holds. This significantly improves performance when the requested data amount is less than the kernel buffer size. The intermediate buffer on the write side allows the write to complete asynchronously.
Unfortunately, this approach itself can become a performance bottleneck if the size of the data requested is considerably larger than the kernel buffer size. The data gets copied multiple times among the disk, kernel buffer, and user buffer before it is finally delivered to the application.
Zero copy improves performance by eliminating these redundant data copies.
zero copy approach
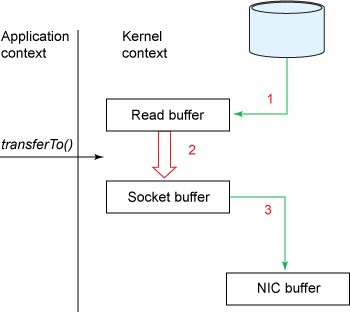
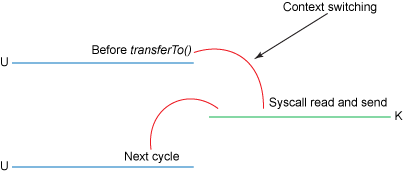
The transferTo() method causes the file contents to be copied into a read buffer by the DMA engine. Then the data is copied by the kernel into the kernel buffer associated with the output socket.
The third copy happens as the DMA engine passes the data from the kernel socket buffers to the protocol engine.
This is an improvement: we've reduced the number of context switches from four to two and reduced the number of data copies from four to three (only one of which involves the CPU). But this does not yet get us to our goal of zero copy. We can further reduce the data duplication done by the kernel if the underlying network interface card supports gather operations. In Linux kernels 2.4 and later, the socket buffer descriptor was modified to accommodate this requirement. This approach not only reduces multiple context switches but also eliminates the duplicated data copies that require CPU involvement. The user-side usage still remains the same, but the intrinsics have changed:
The transferTo() method causes the file contents to be copied into a kernel buffer by the DMA engine.
No data is copied into the socket buffer. Instead, only descriptors with information about the location and length of the data are appended to the socket buffer. The DMA engine passes data directly from the kernel buffer to the protocol engine, thus eliminating the remaining final CPU copy.
Zero copy In java
Zero copy readings
1.http://zeromq.org/blog:zero-copy
2.http://www.mellanox.com/pdf/whitepapers/SDP_Whitepaper.pdf
3.http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.58.8050&rep=rep1&type=pdf
4.http://www.cse.ohio-state.edu/~subramon/Tech-Reports/ftp08-tr.pdf
5.http://cscjournals.org/csc/manuscript/Journals/IJCSS/volume6/Issue4/IJCSS-756.pdf
6.http://www.info.kochi-tech.ac.jp/yama/papers/ispdc05_active.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









