







梯度下降法
梯度下降法(Gradient Descent, GD)常用于求解无约束情况下凸函数(Convex Function)的极小值,是一种迭代类型的算法,因为凸函数只有一个极值点,故求解出来的极小值点就是函数的最小值点
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以梯度下降法也被称为“最速下降法”。梯度下降法中越接近目标值,变量变化越小。计算公式如下
梯度下降法(数值解)过程
- Step1:初始化θ(随机初始化)
- Step2:沿着负梯度方向迭代,新的θ 能够使得J(θ) 更小
α:学习率、步长
- Step3:如果J(θ) 能够继续减小,返回Step2,直到迭代完成。
收敛条件:当目标函数的函数值变化非常小的时候或者达到最大迭代次数的时候,就结束循环。
注:仅考虑单个样本的单个 θ 参数的梯度值
4.2批量梯度下降法(BGD)
使用所有样本的梯度值作为当前模型参数θ 的更新
4.3随机梯度下降法(SGD)
使用单个样本的梯度值作为当前模型参数θ的更新
for i= 1 to m,{
}
BGD和SDB的区别
- SGD速度比BGD快(整个数据集从头到尾执行的迭代次数少)
- SGD在某些情况下(全局存在多个相对最优解,J(θ)不是一个二次函数),SGD有可能会跳出某些小的局部最优解,所以一般情况下不会比BGD差;SGD在收敛的位置会存在J(θ)函数波动的情况,抗噪声很差。
- BGD一定能够得到一个局部最优解(在线性回归模型中一定是得到一个全局最优解),SGD由于随机性的存在可能导致最终结果比BGD差
- 注意:优先选择SGD
小批量梯度下降法(MBGD)
- 如果要满足算法训练过程较快,又需要保证最终参数训练的准确率较高,提出小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)。
- MBGD中是把样本划分为b个样本(b一般为10),然后以这b个样本的平均梯度为更新方向:
for i = 1 to m/10,{
}
学习率选择和参数初始化
由于梯度下降法中负梯度方向作为变量的变化方向,所以有可能导致最终求解的值是局部最优解,所以在使用梯度下降的时候,一般需要进行一些调优策略
- 学习率的选择:学习率过大,表示每次迭代更新的时候变化比较大,有可能会跳过最优解;学习率过小,表示每次迭代更新的时候变化比较小,就会导致迭代速度过慢,很长时间都不能结束;
- 算法初始参数数值的选择:初始值不同,最终获得的最小值也有可能不同,因为梯度下降法求解的是局部最优解,所以一般情况下,选择多次不同初始值运行算法,并最终返回损失函数最小情况下的结果值;
- 标准化:由于样本不同特征值的取值范围不同,可能会导致在各个不同参数上迭代速度不同,为了减少特征取值的影响,可以将特征进行标准化操作。
BGD、SGD、MBGD的区别
当样本量为m的时候,每次迭代BGD算法中对于参数值更新一次,SGD算法中对于参数值更新m次,MBGD算法中对参数值更新m/n次,相对来讲SGD的更新速度最快;
SGD算法中对于每个样本都需要更新参数值,当样本值不太正常的时候,就有可能会导致本次的参数更新会产生相反的影响,也就是说SGD算法的结果并不完全收敛,而是在收敛结果处波动;
SGD算法是每个样本都更新一次参数值,所以SGD算法特别适合样本数据量特别大的情况以及在线机器学习(Online ML)
梯度下降法案例代码
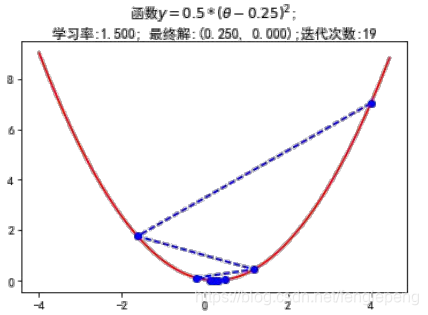
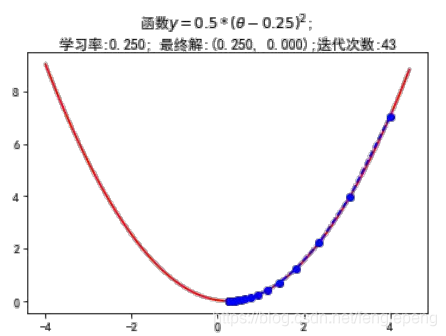
坐标轴下降法
坐标轴下降法(Coordinate Descent,CD)是一种迭代法,通过启发式的方法一步步的迭代求解函数的最小值,和梯度下降法(GD)不同的时候,坐标轴下降法是沿着坐标轴的方向去下降,而不是采用梯度的负方向下降。

坐标轴下降法利用EM算法的思想,在参数更新过程中,每次均先固定m-1个参数值,求解剩下的一个参数的局部最优解;然后进行迭代式的更新操作。
坐标轴下降法的核心思想是多变量函数F(X)可以通过每次沿着一个方向优化来获取最小值。
其数学依据是:对于一个可微凸函数f(θ),其中θ 为 n*1 的向量,如果对于一个解 ,使得f(θ) 在某个坐标轴
上都能达到最小值,则
就是 f(θ) 的全局的最小值点。
在坐标轴下降法中,优化方向从算法的一开始就固定了,即沿着坐标的方向进行变化。在算法中,循环最小化各个坐标方向的目标函数。即:如果 给定,那么
的第i维度为:
因此,从一个初始的 求得函数F(x)的局部最优解,可以迭代获取
的序列,从而可以得到:
坐标轴下降法算法过程:
- 给θ 向量随机选取一个初值,记做
- 对于第k轮的迭代,从
开始计算,
到为止,计算公式如下:
- 检查
和
向量在各个维度上的变化情况,如果所有维度的变化情况都比较小的话,那么认为结束迭代,否则继续k+1轮的迭代
- 在求解每个参数局部最优解的时候可以求导的方式来求解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









