






前言
Transformer是许多大模型的基础模型,理解Transformer是学习大模型原理一个很好的开始。目前的资料分散且不容易理解,本文通过简单通俗的方式描写,希望即使是算法小白也能够了解。本文分为三部分,包括零模型理解、算法演算、微调应用。
文字接龙
简单来说Transformer模型就像一个文字接龙游戏,输入前边的文字机器会给你接上后边的文字。在这个过程中,机器通过训练好的模型计算找到最有可能的输出,再将输出在作为输入计算下一个输出,如此反复直到结束。
Transformer模型是一个seq2seq(序列转序列)模型,任何能够把输入和输出转化为序列的模型都能够使用。文字可以,语音可以、图片视频也可以。
什么是模型
机器学习为什么称之为学习是因为模拟了人类学习的过程。人类学习的过程就是学习、做题、纠错,再做题,直到最终达到满意分数,通过大脑掌握知识。机器学习的过程类似,只不过我们最终得到的是复合函数,以及相关的最优的参数集合。所以说机器学习的过程就是通过训练寻找最优复合函数及其参数的过程。
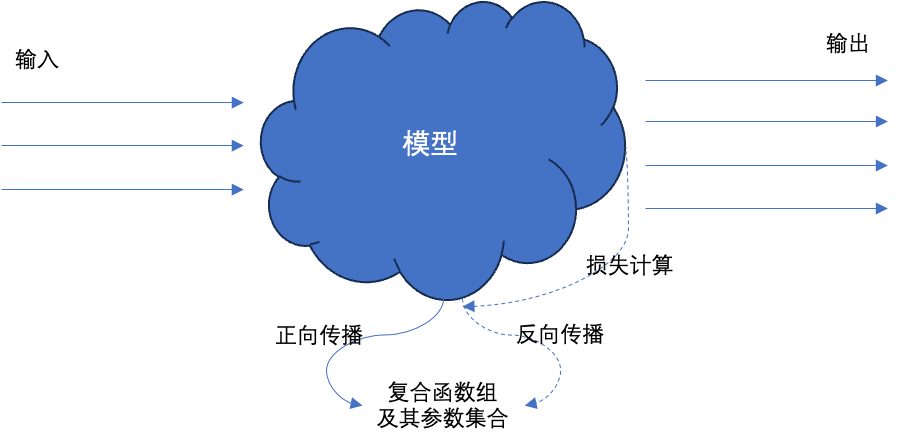
- 正向传播就是做题的过程,
- 损失计算、反向传播就是根据分数巩固知识,纠错的过程。
模型架构
让我们看下transformer模型架构全貌。下面会按照各个组件来说明其功能。
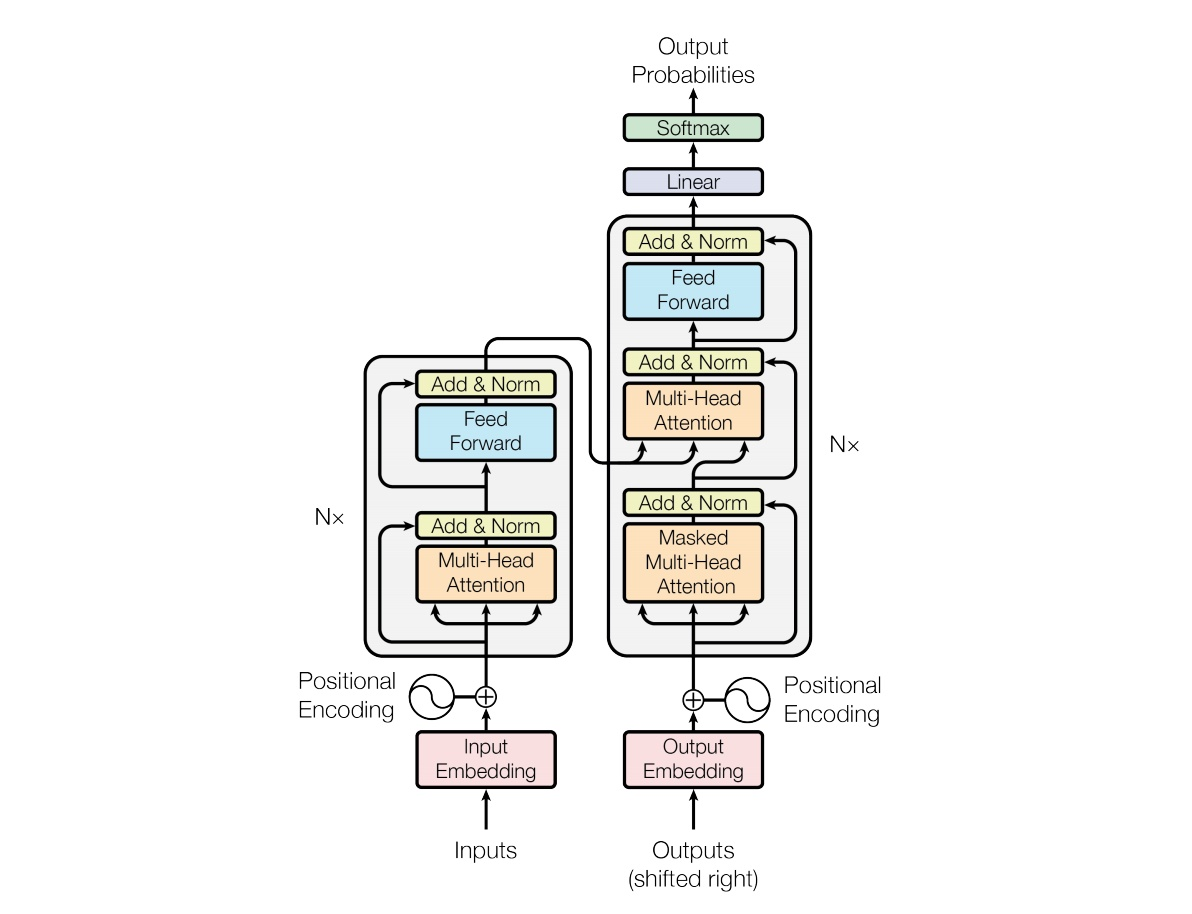
源自论文
模型组件
以NLP为例,模型主要分成两个部分,即编码器(上图的左侧部分)和解码器(上图的右侧部分)。编码器,是把文本转化成能够被解码器使用的、具有位置信息、词含义、语境等信息的数学表达(词向量集合)。而解码器,是使用这些向量集合通过模型计算出最大概率的输出,确定最优的输出。
为什么是词向量?以经纬度为例,当我们把城市用经纬度表示,我们就可以轻松计算出城市之间的距离,是不是都在同一个半球,是不是有相似的气候,如果加上海拔我们就可以关联城市之间的海拔、地势关系。同样多维度的词向量可以表达更丰富的词的意义,语意关联度等。
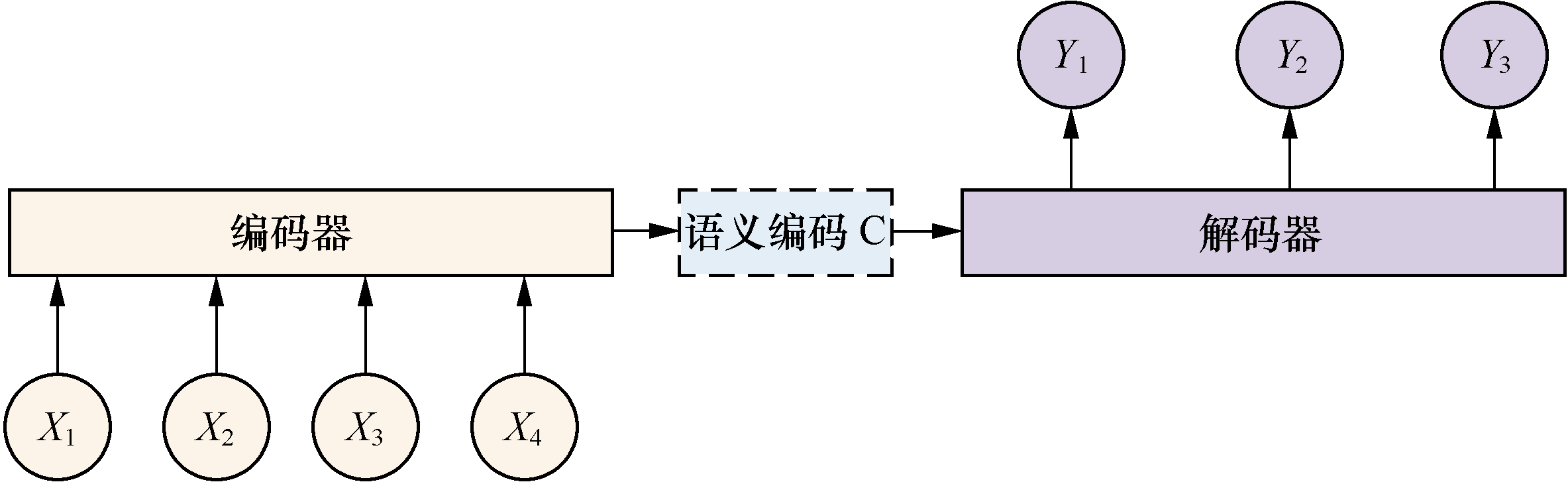
源自网络
输入编码
词嵌入(Input Embedding/Output Embedding)
词嵌入(Word Embedding)简单来说,就是把每个词语转换成一个向量,这个向量能够捕捉到词语的意义和上下文信息。这样,机器就可以通过比较这些向量来理解词与词之间的相似性,比如“猫”和“狗”的向量会比较接近,而“猫”和“汽车”的向量则相差较远。
想象一下,每个词都代表空间中的一个点,相似的词在空间中距离近,不相似的词距离远。词嵌入就是找到一个合适的方式来摆放这些点,使得点与点之间的相对位置能反映出词语之间的语义关系。这种方法极大地帮助了自然语言处理任务,比如情感分析、机器翻译或者文本分类等。
位置编码(Positional Encoding)
输入信息经过词嵌入处理后,输出向量并不具备位置信息,而位置信息对于模型推理至关重要。位置编码技术就是让数据具备位置信息的技术手段。在Transformer中分为“固定位置编码”与“可学习的位置编码”,其一般采用固定位置编码中的正余弦位置编码方式。
编码器(Encoder)
编码器由多个相同的层堆叠而成,每一堆叠包括多头注意力子层和前馈神经网络子层。自注意力机制让模型能够理解输入句子中不同部分的重要性。而全连接网络则进一步提炼和丰富这些信息。有研究发现,注意力头和前馈网络有一种普遍的分工,注意力头从提示单词中检索信息,而前馈层使语言模型能够“记住”提示中没有的信息,即训练资料中的信息。
想象下“菜”的烹饪过程,基础材料就像输入的原始数据。“自注意力和前馈网络”,就像处理信息的调料,让数据更加丰富有层次。"Add"操作融合新旧信息,保留并增强了数据中有用特性。最后,"Norm"规范化就像调味,确保所有成分平衡和谐,使得网络学习过程更加高效和稳定。这样一来,模型就能更好地理解和生成复杂的内容。
多头注意力子层(Multi-Head Attention)
通过多头并行工作,可以达到从不同的角度理解输入信息的效果,然后再把这些多角度理解结合起来,帮助模型更全面、更细致地把握输入句子中的重要信息。
同样的以做菜为例,多注意力头就像是多个分工厨师,有的关注色泽,有的关注味道,有的关注口感,最后把大家关注的内容综合起来,让菜品更加出色。
前馈神经网络子层(Feed Forward)
注意力层已经帮模型搞清楚了哪些信息是重要的。前馈神经网络子层在注意力机制提取关键信息之后,通过一些复杂的数学运算,为模型提供更深一层的理解力和决策基础。
残差链接&归一化(Add&Norm)
残差链接,将输入数据与该层输出输出数据相加,通过融合新旧信息,保留并增强了数据的原有用特性,防止数据失真。
归一化,将输出数据处理,落入一个特定的范围或者符合某种分布特性,起到稳定训练过程、加速收敛、提高泛化能力的作用。规范化就像调味,确保所有成分平衡和谐,使得网络学习过程更加高效和稳定。
解码器(Decoder)
解码器也是由多个相同的层堆叠而成,结构上与编码器类似,每一堆叠包括掩码多头注意力子层、编码器-解码器多头注意力子层以及前馈神经网络子层。
它的作用是在处理过程中,同时关注“编码器产生数据”和“解码器产生数据”,经过多个层次步骤处理,最终得到预测结果。无论是在推理和训练过程中,起着至关重要的作用。
掩码多头注意力子层(Masked Multi-Head Attention)
起到的作用同解码器的多头注意力子层,可以达到从不同的角度理解输入信息的效果,不过它接收数据有所不同。在推理阶段输入的是预测数据;在训练阶段,输入的是训练结果的真实数据。
当然他还有一个更重要的作用,就是在训练阶段,通过“掩码”方式让模型不会看到要预测的真实信息,避免造成因果不一致现象出现。
编码器-解码器多头注意力子层(Multi-Head Attention)
该子层负责将编码器产生的内容与解码器推理的输出内容做注意力的计算,让模型即可以关注输入也可以兼顾输出,确保未来生成的内容一致连贯。
前馈神经网络子层(Feed Forward)
同编码器。
残差链接&归一化(Add&Norm)
同编码器。
输出组件
负责将“解码器得到的结果”转化为“词汇预测概率表”。线性层,通过将“解码器得到的输出”一系列计算处理,得到“目标词汇预测分数表”。分类概率函数(Softmax),将“目标词汇预测分数表”转变为“目标词汇预测概率”。通常预测中会选择概率最高的作为本次预测内容,预测内容再作为解码器的输入,如此反复,直到遇到结束标记。
线性层(Linear)
线性层,通过将数据升维、非线性激活、再降维的方式,将“解码器得到的输出”经过处理,得到“目标词汇预测分数表”。
分类概率函数处理(SoftMax)
Softmax层通常用在多分类任务的输出层,它将线性层产生的原始分数转换为概率分布,产生最终的词汇概率列表。通过比较Softmax输出的概率分布,可以选择概率最高的类别作为模型的预测结果。
引用
1、Large language models, explained with a minimum of math and jargon


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









