









爬虫知识星球
我们都知道现在知识星球里面的内容有很多的沉淀,但是我们并不能每次打开从头开始阅读到最后,虽然星主也会每隔一段时间对知识星球内容进行汇总,但还是有一定的遗留内容。
为了让自己对知识有个很好的把握,方便自己后期查询整理,今天先使用Java简单的使用爬虫,进行读取数据。
环境准备
我们使用的语言是Java8,开发工具是Idea,仓库管理使用ggithub,代码会存放到github上。
爬虫代码链接:https://github.com/menhuan/notes/tree/master/code/codebase-master/onirigi-repile
如果需要直接使用的,需要自己把里面cookie改成自己的,并且处理下浏览头部信息。
星球准备
进行爬虫首先需要找到星球是按照什么登陆,是按照token还是按照cookie,还是按照session的方式来进行数据交互的。
关于以上三者的内容区别,可以参考我上一篇文章的链接。
找出来http设置的header
这次爬虫并没有设置模拟登陆的操作,只是根据访问具体链接来操作。
登陆星球后,找到链接,查看请求头里面的内容。
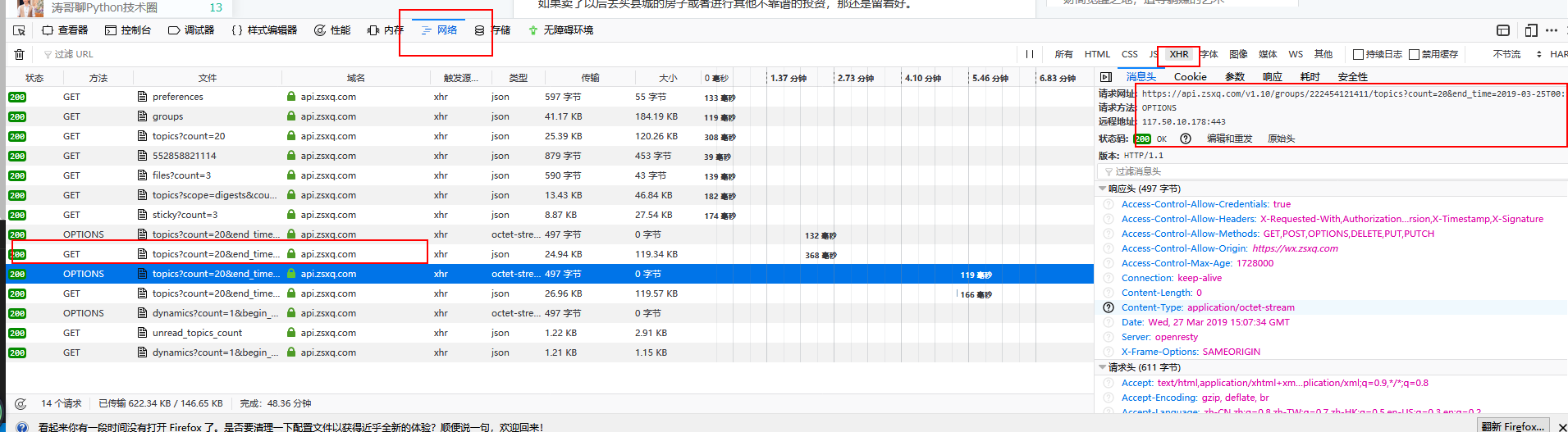
这样我们就能找到后台访问链接地址,如果在查找的时候,并不知道怎么查看,就自己使用F12查看下。
内容显示如图上所示。
不同的链接内容,可能并没有找到cookie信息,这时候需要我们耐心下,对于前后端产品都是需要鉴权验证的。
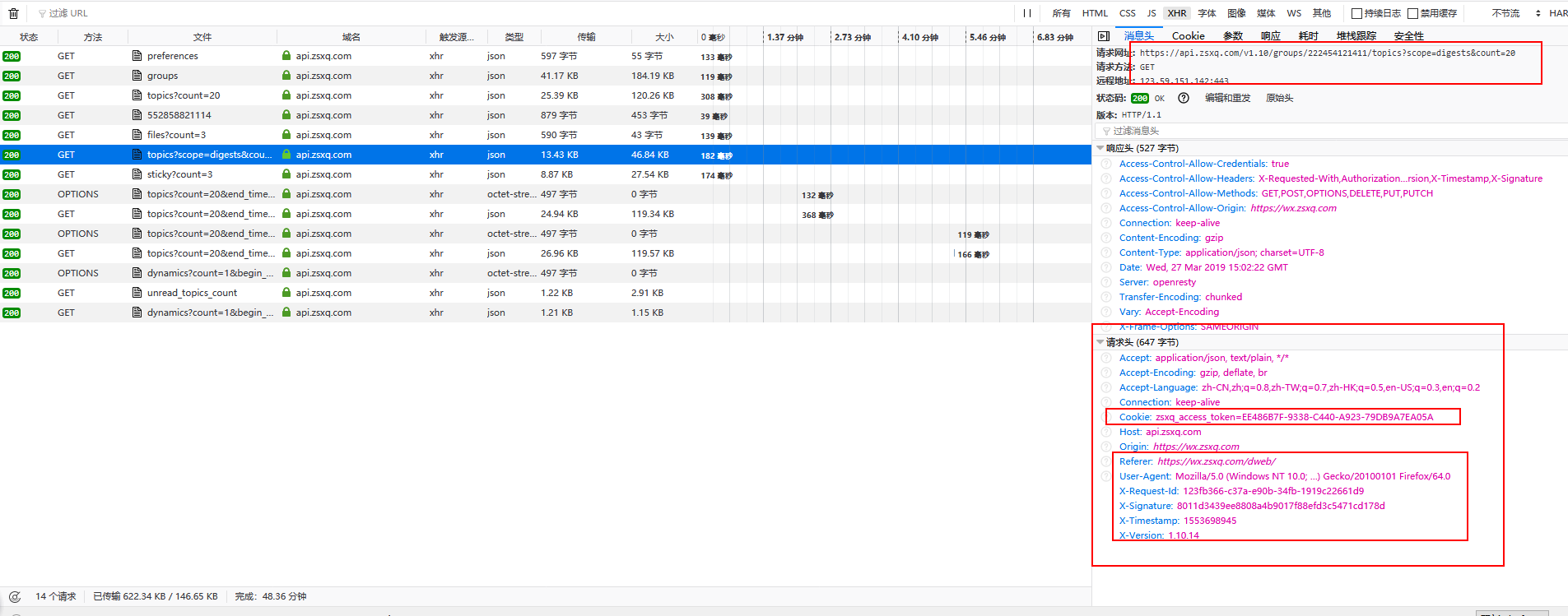
从图上显示可知,知识星球是将token内容放到在cookie当中,那么我们在模拟访问的时候需要在http header上设置 cookie。
从上面图中我们可以找到在访问需要设置的header,还有需要访问的链接url:
https://api.zsxq.com/v1.10/groups/222454121411/topics?scope=digests&count=20
当然,在图上内容显示,还有更多的接口让我们去访问数据,先将整体的流程数据获取到,我们再进行更多的数据访问整合。
需要设置的header内容包含如下:
- cookie: zsxq_access_token=CD063C9D-9A81-B150-C996-sdasa 需要替换成自己的
- Referer:https://wx.zsxq.com/dweb 需要跳转的网站
- User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36 设置浏览器
这三个内容设置在http 访问中即可
写程序
程序是建立在Spring boot 1.5.10版本上。构建程序使用的gradle 4.9+.
/** http 访问知识星球设计的请求
* @return java.lang.String
* @Author fruiqi
* @Description 爬虫设置header, 访问的url
* @Date 22:53 2019/3/27
* @Param [headMap, url]
**/
public String restStar(Map<String, String> headMap, String url) {
RestTemplate restTemplate = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
headMap.forEach((k, v) -> {
headers.set(k, v);
});
HttpEntity entity = new HttpEntity(headers);
ResponseEntity<String> exchange = restTemplate.exchange(url,
HttpMethod.GET, entity, String.class);
String result = exchange.getBody();
return result;
}
请求统一设置好之后,写访问service
Map<String,String> headMap = new HashMap<>(10);
headMap.put("User-Agent",USER_AGENT_ARRAP);
headMap.put("Referer","https://wx.zsxq.com/dweb/");
headMap.put("cookie","zsxq_access_token=CD063C9D-9A81-B150-C996-35B20D2E1ABD");
RequestUtil requestUtil = new RequestUtil();
String res = requestUtil.restStar(headMap, url);
JSONObject jsonObject = JSON.parseObject(res);
logger.info("[info] JSON content :{}",res);
通过上面链接我们就可以获得到知识星球数据。
当然这个具体还是在搭架子,后期需要完善的内容如下:
- 获取所有星球分组信息。
- 根据不同的组获取星球星主的问答,进行摘取。
- 设置定期策略,采集数据,并整理成册
- 数据整理与分析。
以上暂时是星球爬取内容的规划,预计在3个月内完成,欢迎大家一起围观。
源代码地址如下:
https://github.com/menhuan/notes/tree/master/code/codebase-master/onirigi-repile

总结
·END·
路虽远,行则必至
本文原发于 同名微信公众号「胖琪的升级之路」,回复「1024」你懂得,给个赞呗。
微信ID:YoungRUIQ


















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









