







思维导图
我们知道只有运用好设计原则和设计模式,才能让我们写出更加优秀的代码或者设计更好软件架构,在实际开发中,由于许多不遵守设计原则和设计模式的硬编码,导致项目代码及其晦涩难懂的例子比比皆是,作为一个软件开发人员,写出高质量、易懂、已维护的代码应该是我们每个人应该做到的
1. 六大设计原则
我们知道设计模式一共有23种,虽然模式很多,但是都是为了遵守和实现六大设计原则而诞生的,如果我们能够理解六大设计原则,相信我们也能像令狐冲修炼独孤九剑一样无招胜有招,毕竟功夫的最高境界就是忘记招式,下意识使用的就是最合理的招式
其中我们要注意的是,其实六大设计模式主要是为了满足变,这个字,可能是需求变更、可能是场景变更,但是运用好六大设计模式后我们写出的代码就能很好的应对不断变化的场景,做到任他东南西北风我自岿然不动的境界
1.1 单一职责
单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
简单的来讲:就是小到一个方法、一个类,大到一个框架,都只负责一件事情
例如:
- Math.round(),只负责完成四舍五入的功能,其他的不负责
- Reader类,只负责读取字符(文本文件)
- SpringMVC,只负责简化MVC的开发(框架)
举个栗子,我们知道,中国有四大发明,分别是造纸术、指南针、火药、活字印刷术,这里要注意的是活字印刷术,而不是印刷术,我们思考一下为什么印刷术出现的比活字印刷术早,但是并没有被列入四大发明呢?活字印刷术看起来不应该只是印刷术的改良版本吗?
我们来设想一个场景,在没有活字印刷术之前如果现在需要批量印刷一篇文章,我们需要怎么做?找人抄吗?高效的方法是拿块木板,用篆刀雕刻出一篇文章,然后搞点墨水,一下就能印出一篇文章,这样的速度非常快!

但是现在变化来了,前面提到,设计原则主要就是为了应对变化的。现在有个师傅发现好不容易雕刻的木板上有个字写错了!那现在怎么办呢?只能重新篆刻。那如果下次又发现需要更换句子怎么办呢?我们发现雕版印刷术并不能很好的应对变化
再让我们看看活字印刷术是如何处理的?首先我们现在不再直接篆刻一块大大的木板了,我们将原本很大的职责拆分成一个一个的汉字,再通过组合的方式将我们需要的文章拼起来,这样下次字写错了只需要修改一个字即可

这就是单一职责的核心:
通过高内聚、低耦合的设计方案,刚庞大的系统拆成单一职责的小功能,再通过灵活组合的方式完成功能,这样做最大的好处就是可以通过不断的组合,应对不断变化的场景
举个我们在编码中最容易遇到的情况,我们有的时候看别人的函数实现,有的恶心的代码可能一个函数中就有大几百行,然后你们全部都是业务逻辑,比如支付功能的函数中有查询商品库存 -> 查询用户余额 -> 确认订单 -> 调用支付接口这五个步骤,有的同学写代码上去就是搜哈,一股脑全写完,下次遇到个退货的功能需要用到查询商品库存、查询用户余额的代码,直接copy过去,造成代码臃肿,可读性差,正确的方式应该是将其封装成一个个的方法或函数,这样可以做到减少重复代码的效果
关于单一职责,这里就不用代码举例了,大家记住在平时编码中记住单一职责、不断组合就行
1.2 开闭原则
开闭原则(Open Close Principle)
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类
举个栗子,我现在有一个刮胡刀,刮胡刀的功能应该就是刮胡子,但是我现在想要它拥有吹风机的能力
- 违法开闭原则的做法是,把吹风机的功能加上了,可能就不能刮胡子了
- 符合开闭原则的做法是,把吹风功能加上,且没有影响之前刮胡子的功能
例如我现在有一个商品类Goods,这个类之前有一个方法是获取它的价格,例如:
public class Goods {
private BigDecimal price;
public void setPrice(BigDecimal price) {
this.price = price;
}
public BigDecimal getPrice() {
return this.price;
}
}
现在变化来了,当前商品需要打8折进行销售,不符合开闭原则的做法就是直接进原来的代码中进行修改,例如直接在getter方法中修改
public BigDecimal getPrice() {
// BigDecimal.multiply就是乘法,BigDecimal可以防止精度丢失
return this.price.multiply(new BigDecimal("0.8"));
}
这样显然就是不满足开闭原则的,因为我们对源代码进行了修改,如果下次是打七折,那是不是又要去改源代码呢
正确的做法应该是写一个子类DiscountGoods来拓展父类的功能,再在子类上进行修改,这样就不会破坏父类的功能,又能满足需求
public class DiscountGoods extends Goods{
@Override
public BigDecimal getPrice() {
return super.getPrice().multiply(new BigDecimal("0.8"));
}
}
这就叫对扩展开发,对修改关闭。我们在用设计模式编码时应该时刻注意的是,改源码是一件非常危险的事情,因为一个功能并不是只有你在使用,很容易造成牵一发而动全身的效果
但是如果我们因为要遵守开闭原则,每次对功能进行修改的时候,都去新写一个类,这样的会很繁琐,所以我们的准则是:
- 如果一个类是自己写的,自己修改不会影响该类在其他地方的效果(不会
牵一发而动全身),那你就可以随意修改 - 如果不是自己写的,自己不清楚修改后会带来什么样的影响,那就不要修改,而要符合开闭原则
1.3 接口隔离原则
接口隔离原则(Interface Segregation Principle)
使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口
接口隔离原则在我们设计接口的时候也是非常容易忽略从而造成问题的的一个原则,例如我现在要要设计一个动物的接口,统一动物的行为,我们可能会这样写:
public interface Animal{
void eat();
void swim();
void fly();
}
我们看这三个行为,分别是吃、游泳和飞,我们定义的是动物的接口,这样好像并没有什么问题,动物确实拥有这三个行为,但是问题就在于动物这个接口范围太大了,并不是所以的动物都同时拥有这三个行为
例如下面的小狗类中,狗由于不会非,所以不应该有方法fly() 的实现!
public class Dog implements Animal {
@Override
public void eat() {
System.out.println("小狗在吃东西");
}
@Override
public void swim() {
System.out.println("小狗会狗刨");
}
@Override
public void fly() {
throw new UnsupportedOperationException("小狗不会飞");
}
}
我们现在将这个大接口拆分一下:
interface Eatable{
void eat();
}
interface Swimable{
void swim();
}
interface Flyable{
void fly();
}
再不断的组合,实现不同的接口,其实核心思想还是高内聚,低耦合,通过不断组合不可分割的功能完成最终需要的功能
是不是现在有一点点无招胜有招的感觉了,感觉习惯之后自然而然就好感觉这块设计有问题,然后设计更好能应对变化的方案
public class Dog implements Eatable, Swimable {
@Override
public void eat() {
System.out.println("小狗在吃东西");
}
@Override
public void swim() {
System.out.println("小狗会狗刨");
}
}
1.4 依赖倒置原则
依赖倒置原则(Dependence Inversion Principle)
这个是开闭原则的基础,具体内容:针对接口编程,依赖于抽象而不依赖于具体。实际中开发的实践就是,
面向接口编程
- 上层不应该依赖于下层
- 它们都应该依赖于抽象
依赖倒置在实际编码中通常采取的是:上层不能依赖于下层,他们都应该依赖于抽象
这里区分上下层的方法为:调用别的方法的就是上层,被调用的就是下层
举个栗子:我们现在有三个类,互相有依赖关系
class Person {
public void feed(Dog dog) {
System.out.println("开始喂dog...");
}
}
class Dog {
public void eat() {
System.out.println("狗啃骨头");
}
}
// ================================================================
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
person.feed(dog);
}
}
首先我们在依赖倒置原则里面非常重要的一点是,要区分依赖中的上层和下层,我们时刻要注意调用别的方法的就是上层,被调用的就是下层,所以这里的层级关系为:AppTest是Person的上层,Person是Dog的上层
我们来仔细思考一下上面的代码,这里好像没什么问题,但是我一直强调的是设计模式是为了应对变化,现在变化来了,现在客户端Person不仅需要喂狗,还需要喂猫,我们很容易直接添加一个Cat类
class Cat {
public void eat() {
System.out.println("小猫吃鱼");
}
}
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
Cat cat = new Cat();
// 喂狗
person.feed(dog);
// 喂猫
person.feed(cat);
}
}
这样明显会报错,因为之前的代码中只能喂狗,不能喂猫!
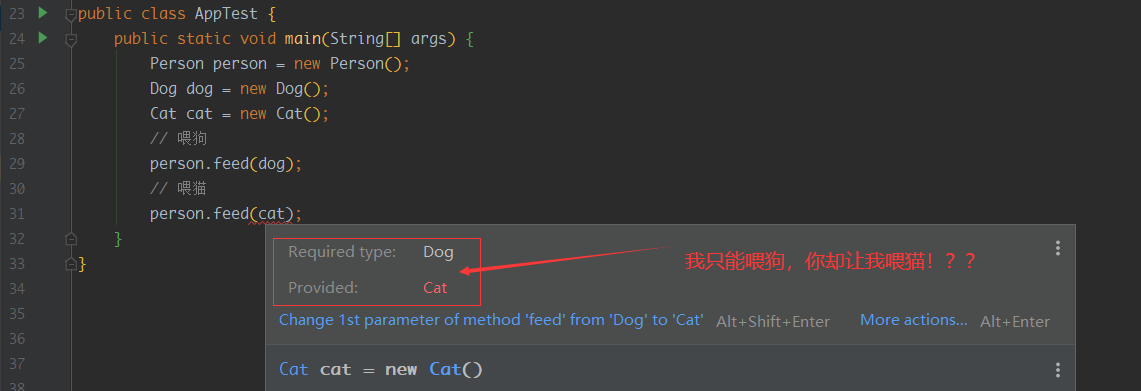
那怎么办呢?我直接重载一个方法,让Person类可以喂猫不就好了吗?
class Person {
public void feed(Dog dog) {
System.out.println("开始喂dog...");
}
public void feed(Cat dog) {
System.out.println("开始喂Cat...");
}
}
好家伙,这是不是为了应对变化直接改源码了?首当其冲的就是破坏了开闭原则,其次如果每次要多喂养一种动物就要去重载一个方法,这显然也不合理叭,这就是因为上层依赖于下层
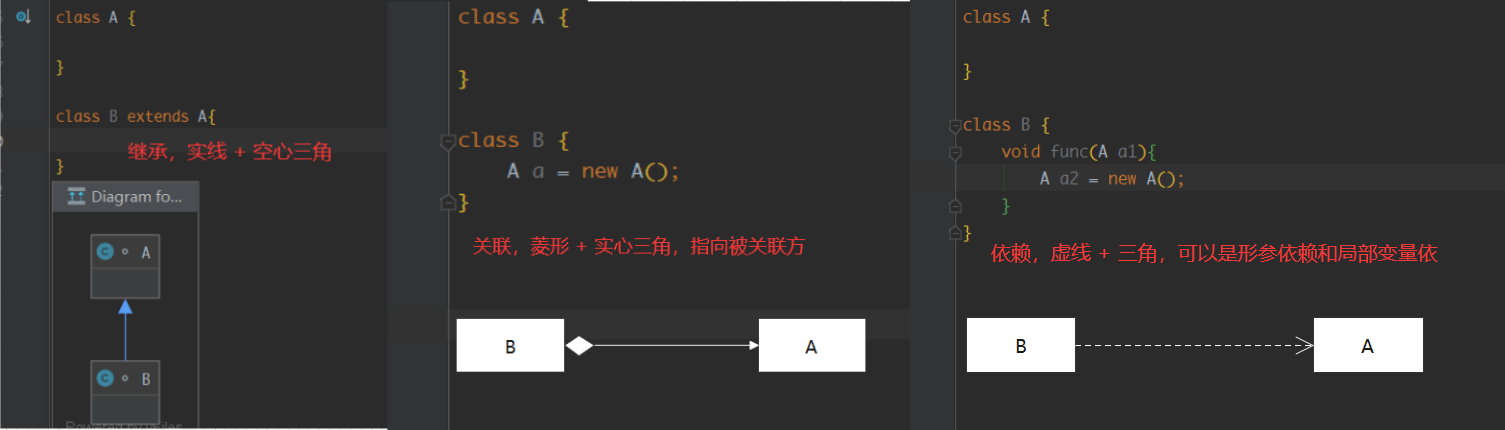
读者可以先自己试着将这几个类的UML类图画出来,可能有的读者不太会画,这里补充一下UML类图的画法
我们知道类和类之间的关系有:关联、依赖、泛化、实现(空心三角箭头的虚线表示实现,实现接口)
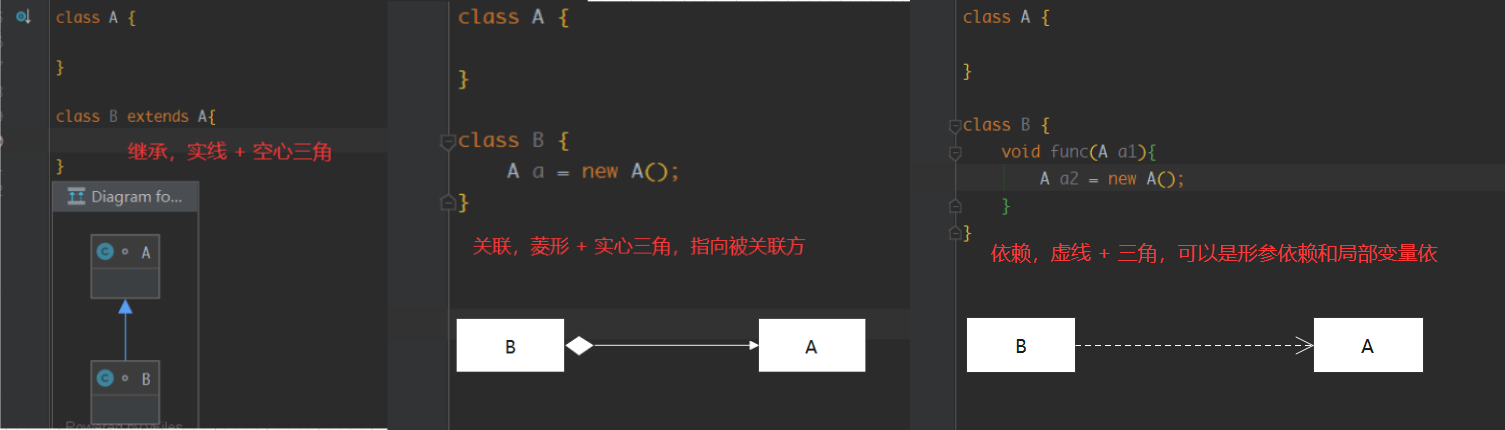
其中关联又可以分为组合 + 聚和,如果没有细分,可以画成实线 + 箭头,不用画菱形
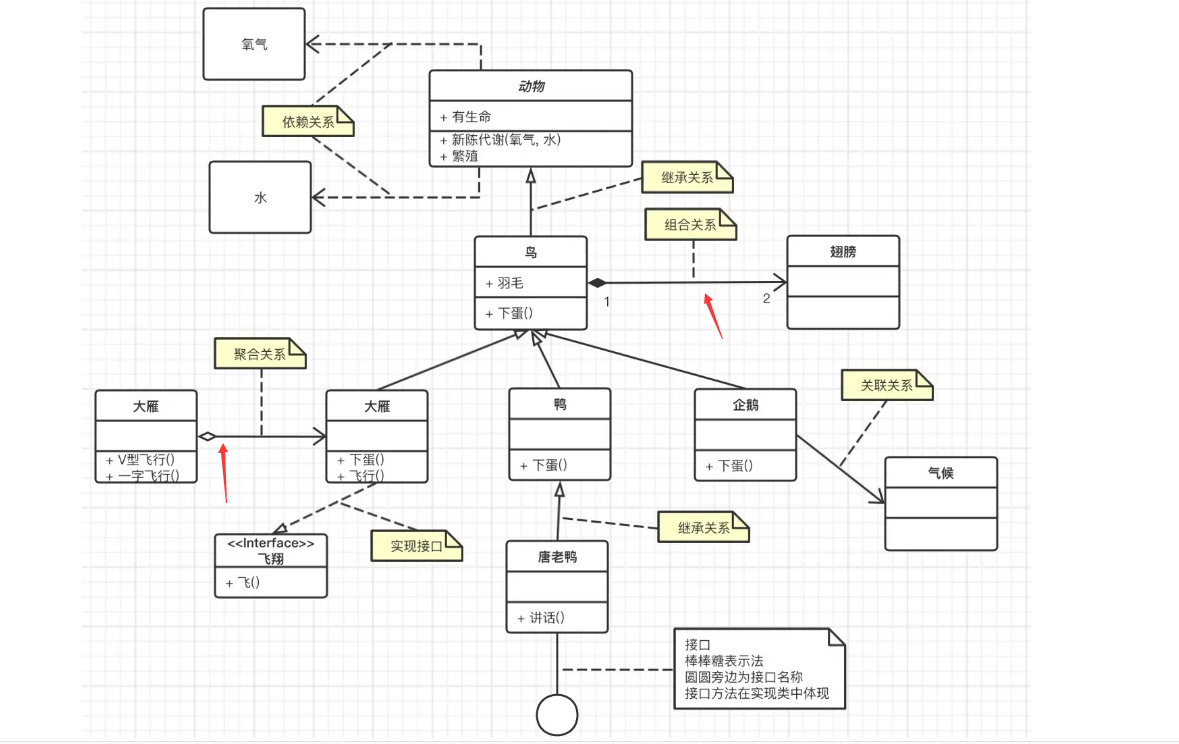
- 组合关系是强关联,失去关联方,两者都不完整,例如大雁和翅膀,就是强关联,大雁不能失去翅膀
- 聚和是弱关联,失去关联方,被关联方依旧完整,例如雁群和大雁,失去一只大雁,不影响雁群整体
现在我们来画一下上面人喂动物的UML类图,由于动物作为形参传入人类中,所以明显这是依赖关系,我们用虚线三角画即可
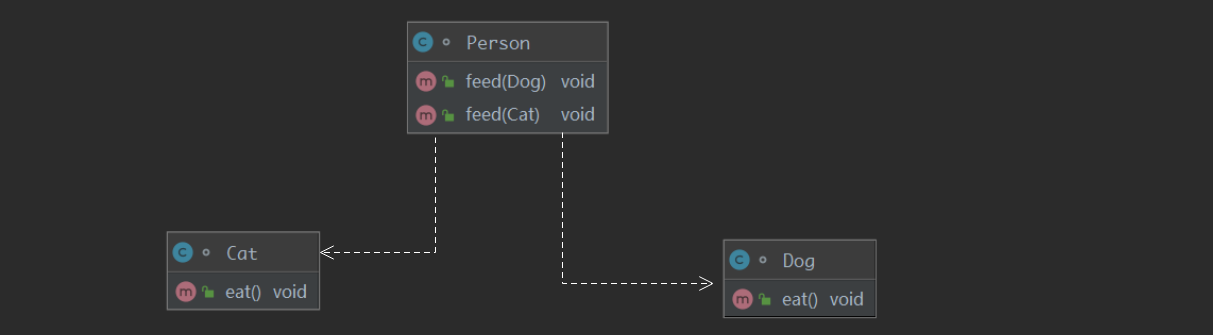
我们看出上面代码的问题,就是每当一个新的类需要依赖时,就要重载一个方法,这里就违反了依赖倒置原则,每当下层发生改变时,上层都要一起改变,这样的设计没有拓展性,我们不应该依赖于具体的类,而应该依赖于抽象的接口!
我们想要的结果是下层代码发生变化,对于上层来说是无感知的!代码也不需要改动,这就是依赖倒置的核心!
我们回过头来分析问题,我们人类的动作是什么?是喂养动物!不是喂狗、喂猫,狗和猫只是动物的实现!所以我们应该进行依赖倒置,依赖抽象不依赖实现,这里我们只需要依赖一个抽象的动物类或者接口即可
class Person {
public void feed(Animal animal) {
System.out.println("开始喂dog...");
}
}
interface Animal {
void eat();
}
class Dog implements Animal{
@Override
public void eat() {
System.out.println("狗啃骨头");
}
}
class Cat implements Animal{
@Override
public void eat() {
System.out.println("小猫吃鱼");
}
}
// ================================================================
public class AppTest {
public static void main(String[] args) {
Person person = new Person();
Dog dog = new Dog();
Cat cat = new Cat();
// 喂狗
person.feed(dog);
// 喂猫
person.feed(cat);
}
}
我们来看一下类图的变化:
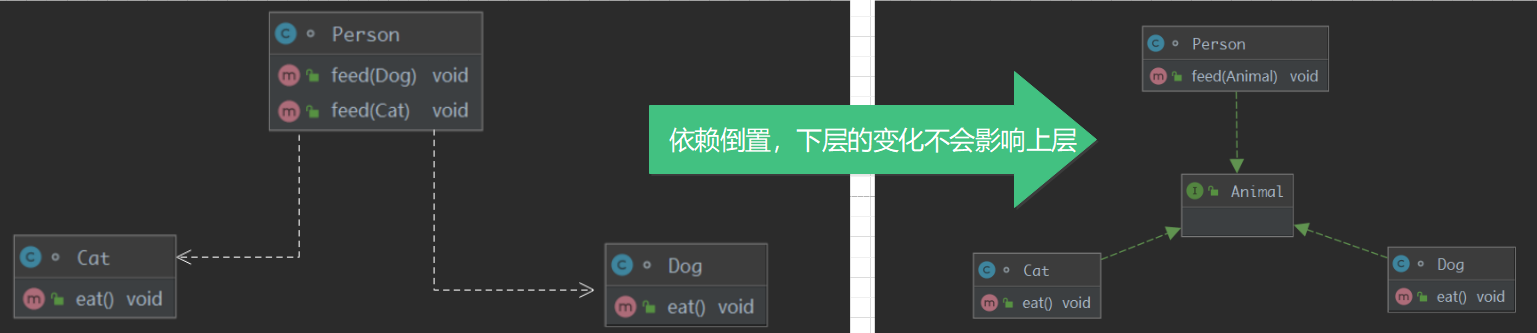
这里可能有的读者会有疑问,为什么下层变了,上层不知道要叫依赖倒置,就叫下层变了,上层不知道不行吗?
看上面的图!之前的箭头是向下指的,是依赖具体的实现,现在箭头倒置过来了,大家都依赖于抽象!这就叫依赖倒置,如果看不明白翻到上面再看一遍下来,好好体会这个倒置的作用。这样以来,不论怎么改变,只需要不断添加新的依赖关系依赖抽象即可,以不变应万变。这里读者再三强调,所以的设计原则核心思想都是一个字,变,都是为了以不变应万变
对上层来说,就是分层,解耦,就是一个分字
编码中我们时刻要注意的就是:
- 上层不应该依赖于下层
- 它们都应该依赖于抽象
其中这种思想在工作中生活中也有很多栗子,很多时候问题都是出现在太依赖某些东西了,当依赖的东西变化,自己就乱了
举几个栗子:
-
在软件开发公司,老板不能具体依赖一些人或者某些语言开发系统,例如java、go、csharp等等,如果产生依赖了就会导致如果现在会Java的跑了,公司没有会Java的了,只能更换架构体系,但是如果领导只管最终的结果,不管具体实现过程,那么矛盾就转移到下层了
-
例如在用人体系,老板不应该直接管理众多的员工,如果过度依赖某些员工,势必会造成问题,一个好的公司不是靠人,而是靠制度、靠规范,应该让所有人依赖制度,老板只需要管理好制度,就能管理好所有人!这就是依赖倒置,在生活中这就叫
画饼!一个大企业不可能去管理每个员工,但是只要管理好抽象的规则制度,让员工都遵守,就可能以不变应万变!!!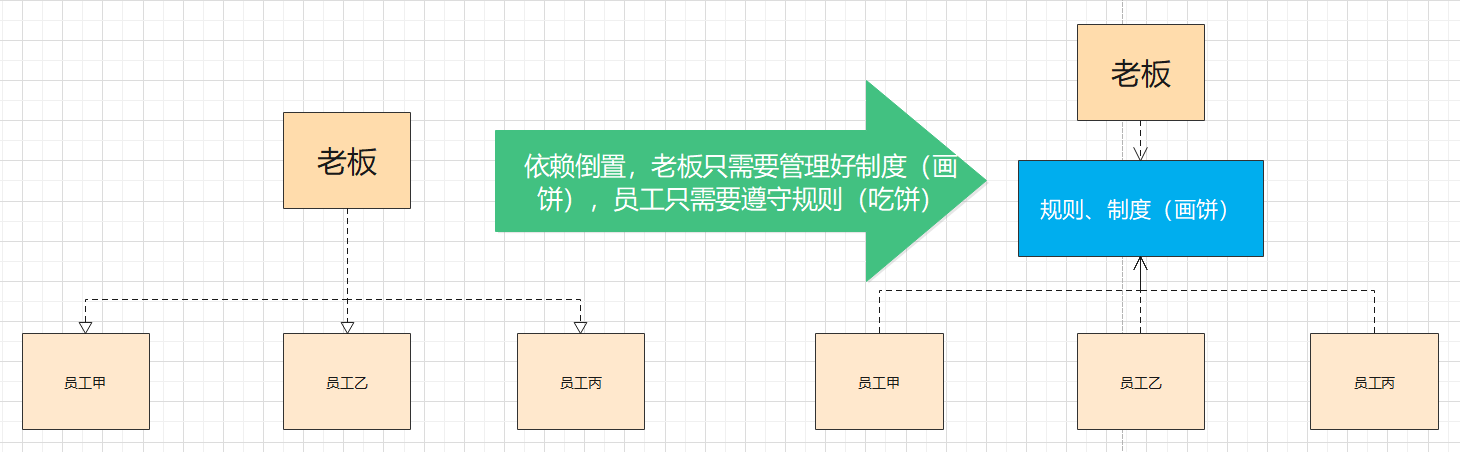
-
例如在教育孩子的时候不应该过分管控孩子的行为,不如给孩子设立目标或者崇高的理想,由外驱力转化为孩子的内驱力,这样才能达到更好的效果。当然这样的例子还有很多,这里就不举例了,再举例下去就变成哲学了
1.5 迪米特法则
迪米特法则(最少知道原则)(Demeter Principle)
为什么叫最少知道原则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立
- 一个类,对于其他类,要知道的越少越好,其实就是封装的思想,封装内部细节,向外暴露提供功能的接口
- 只和朋友通讯,朋友是指:
- 类中的字段
- 方法的参数
- 方法的返回值
- 方法中实例化出来的对象
- 对象本身
- 集合中的泛型
我们来看对于类的例子,现在我们有一个电脑类,里面有一些电脑关机时的操作,然后还有一个人类,里面有一个方法为关闭电脑,需要组合电脑类,并执行电脑类里面的方法
class Compute {
public void saveData() {
System.out.println("正在保存数据");
}
public void killProcess() {
System.out.println("正在关闭程序");
}
public void closeScreen() {
System.out.println("正在关闭屏幕");
}
public void powerOff() {
System.out.println("正在断电");
}
}
class Person {
Compute compute = new Compute();
public void shutDownCompute() {
compute.saveData();
compute.killProcess();
compute.closeScreen();
compute.powerOff();
}
}
这样看上去好像也没什么问题,但是现在变化来了,如果现在关机操作的步骤有几十上百项呢?难道我们要在shutDownCompute方法中去调用上百个方法吗?这里的问题就是:
- 对于
Person类而言,知道Compute中细节太多了 - 其实不需要知道这么多细节,只要知道关机按钮在哪里就行,不需要知道具体的关机流程
- 如果使用者在调用方法时的顺序出错,例如把关电和保存数据的顺序弄错,就容易导致问题
所以正确的方法就是尽量高内聚设计,隐藏实现细节,只暴露出单独的接口实现单一的功能
class Compute {
private void saveData() {
System.out.println("正在保存数据");
}
private void killProcess() {
System.out.println("正在关闭程序");
}
private void closeScreen() {
System.out.println("正在关闭屏幕");
}
private void powerOff() {
System.out.println("正在断电");
}
public void shutDownCompute() {
this.saveData();
this.killProcess();
this.closeScreen();
this.powerOff();
}
}
class Person {
Compute compute = new Compute();
public void shutDown() {
compute.shutDownCompute();
}
}
那么这个封装和暴露的火候该怎么掌握呢?我们接下来看看对于朋友而言的最少知道原则
-
如果对于作为
返回类型、方法参数、成员属性、局部变量的类,不需要过多的封装,应该提供应有的细节,由调用者自己弄清楚细节并承担异常的后果,这样由我们直接创造的对象,我们就能把它称为我们的朋友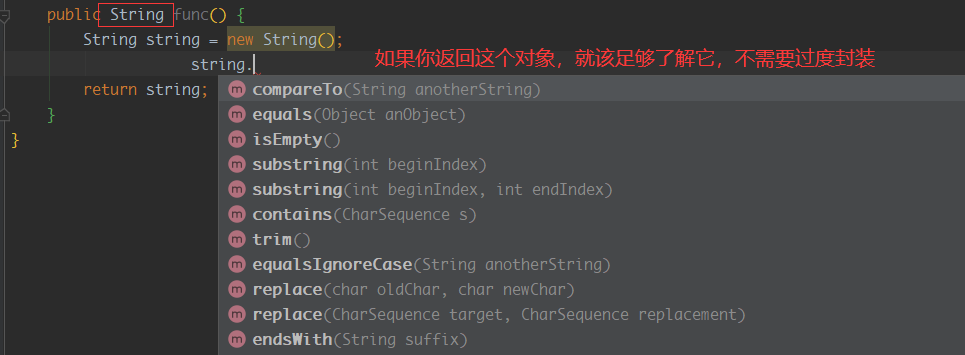
-
但是如果这个对象不是我们自己获得的,而是由被人提供的,就不是朋友,
即朋友的朋友并不是自己的朋友public class AppTest { public void func() { AppBean appBean = BeanFactory.getAppBean(); // 朋友的朋友就不是朋友了 appBean.getStr(); } } class BeanFactory { public static AppBean getAppBean() { return new AppBean(); } } class AppBean { public String getStr() { return ""; } }那么想要和这个
AppBean做朋友该怎么办呢?需要在系统里面造出许多小方法,将朋友的朋友变成自己的朋友,例如:public class AppTest { public void func() { AppBean appBean = BeanFactory.getAppBean(); // 朋友的朋友就不是朋友了 this.getStr(appBean); } /* 将朋友的朋友的细节转换为自己熟悉的方法 */ public String getStr(AppBean appBean){ return appBean.getStr(); } }有的同学可能觉得有点鸡肋这样,确实迪米特法则的缺点就是会制造出很多小方法,让代码结构混乱,所以有的时候适当违反一下也是可以的,但是
封装和暴露的思想我们一定要有,后面我们的门面模式和中介者模式其实也是基于迪米特法则的,读者先不要急,看到后面再回顾这一段,相信会有跟好的理解
1.6 里式替换原则
里氏代换原则(Liskov Substitution Principle)
里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一,里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。
- 简单的来讲,任何能够用父类实现的地方,都应该可以使用其子类进行
透明的替换。替换就是子类对象替换父类对象- 子类对象替换父类后,不会有任何影响
- 是否有is-a的关系
- 有is-a关系后,要考虑子类替换父类后会不会出现逻辑变化
这里我们来看一下方法重写的定义:
- 方法重写是指:在子类和父类中,出现了返回类型相同、方法名相同、方法参数相同的方法时,构成方法重写
- 子类重写父类时,子类的访问修饰符不能比父类更加严格
- 子类重写父类时,不能比父类抛出更多的异常
如果我们故意在子类中抛出比父类更多的异常会怎么样呢?
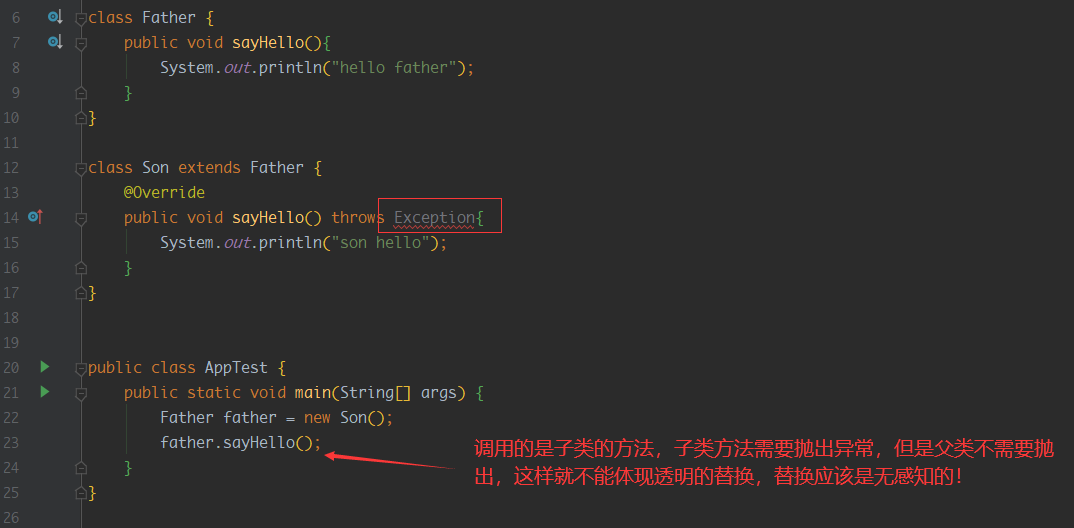
如果没有比父类更多的异常,父类现在在执行方法时就会进行catch,并且能够捕获子类中更少的异常,所以这样进行替换时,就不会影响代码的结构,做到透明、无感知
有很多的例子都可以用里式替换进行解释,著名的例子有:
- 鸵鸟非鸟问题
- 长方形正方形问题
1.7 组合优于继承原则
组合优于继承原则(Composite Reuse Principle)
组合优于继承原则强调的是在复用时要尽量使用关联关系,少用继承
- 组合,是一种强关联关系,整体对象和局部对象的生命周期是一样的,类似于大雁和翅膀的关系
- 整体对象负责局部对象的生命周期;
- 局部对象不能被其他对象共享;
- 如果整体对象被销毁或破坏,那么局部对象也一定会被销毁或破坏
- 聚和,它是一种弱关联,是 【整体和局部】之间的关系,且局部可以脱离整体独立存在,类似于雁群和其中一只大雁的关系
- 代表局部的对象有可能会被多个代表整体的对象所共享,而且不一定会随着某个代表整体的对象被销毁或破坏而被销毁或破坏,甚至代表局部的对象的生命周期可以超越整体
- 总而言之,组合是值的关联(Aggregation by Value),而聚合是引用的关联(Aggregation by Reference)
我们在之前又讲过,关联关系有两种,实心菱形的是组合、空心菱形的是聚和,如果不区分就用虚线指向,组合是作为成员变量作为另一个类的引用,聚和是作为形参或者局部变量作为另一个类的引用
组合大家在平时编码的时候一定经常使用,举一个简单的例子,如果我们现在要有链表实现队列应该怎么做呢?队列的特点就是先进先出,完全可以用链表实现,我们可以用继承关系来做:
public class Queue <E> extends LinkedList<E> {
/**
* 入队
*/
public void enQueue(E element){
this.add(element);
}
/**
* 出队
*/
public E deQueue(){
return this.remove(0);
}
}
我们发现这样并没有什么问题,队列类继承自链表类,并暴露自己提供给外界的方法,但是当我们调用这个Queue时就会发现问题:

好家伙,我的Queue本来只需要入队和出队两个方法,但是居然有这么多细节的方法供我使用,这就违背了迪米特法则,一个类的内部实现应该不要提供给外界,只暴露该提供的方法,这就是继承的问题,继承复用破坏包装,因为继承将基类的实现都暴露给派生类
如果我们换成组合该怎么做呢?
public class Queue<E> {
// 成员变量 -> 组合关系
LinkedList<E> list = new LinkedList<>();
/**
* 入队
*/
public void enQueue(E element) {
list.add(element);
}
/**
* 出队
*/
public E deQueue() {
return list.remove(0);
}
}
所以如果我们仅仅只是为了复用代码,可以优先考虑组合,如果是为了实现多态,可以优先继承
我们也来看一个反例叭,其实在Java中有很多不合理的设计,例如Serializable接口,Date类等等,这里就讲一个java.util.Stack的糟糕设计
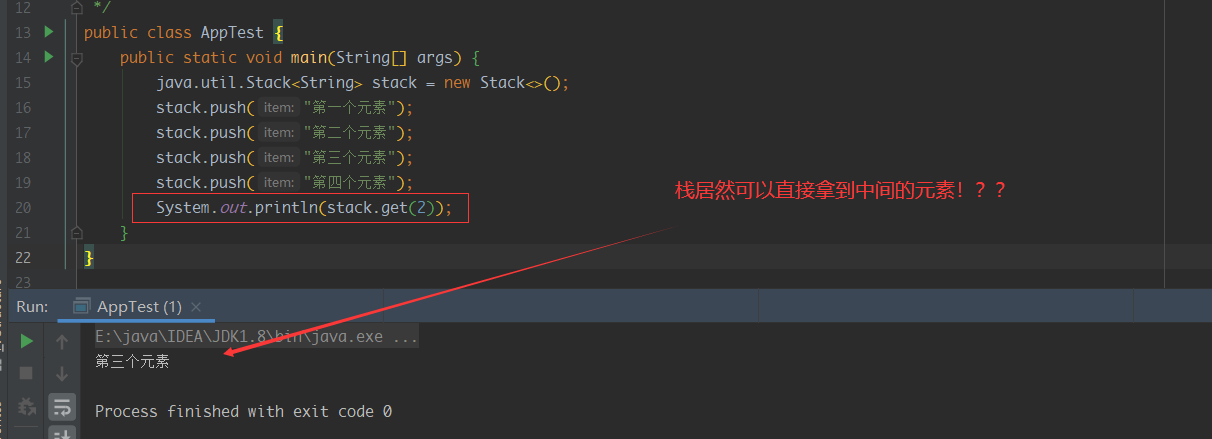
点进源码中看我们发现,原来是继承了Vector类,让其拥有了链表的能力,看着这个兄弟设计模式也没学好
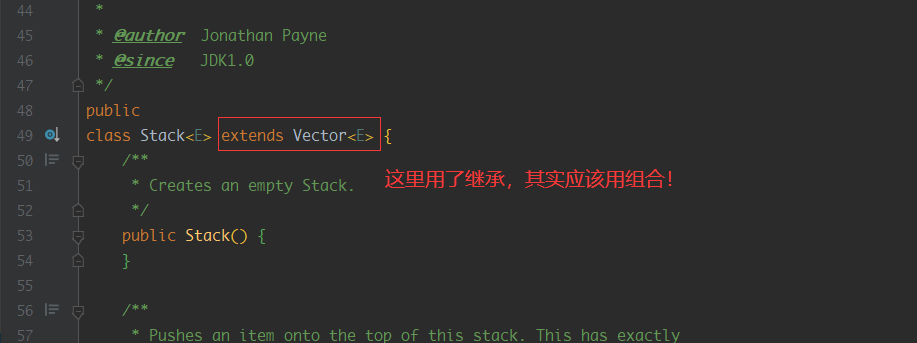
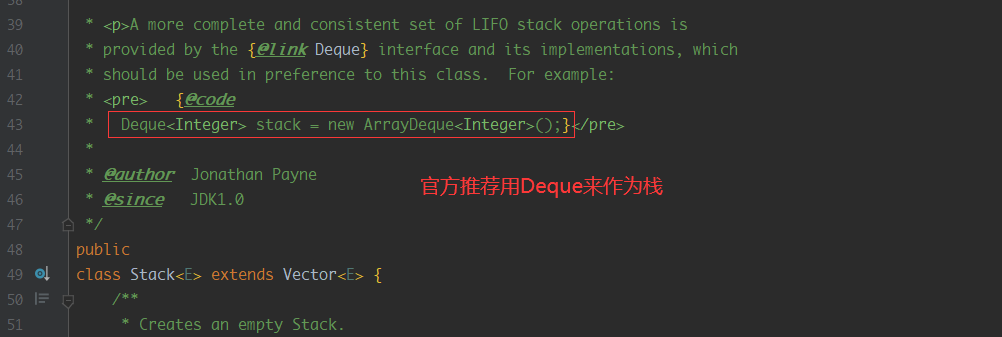
官方也意思到了这个设计不合理的地方,推荐我们使用Deque来实现栈
1.8 设计原则总结
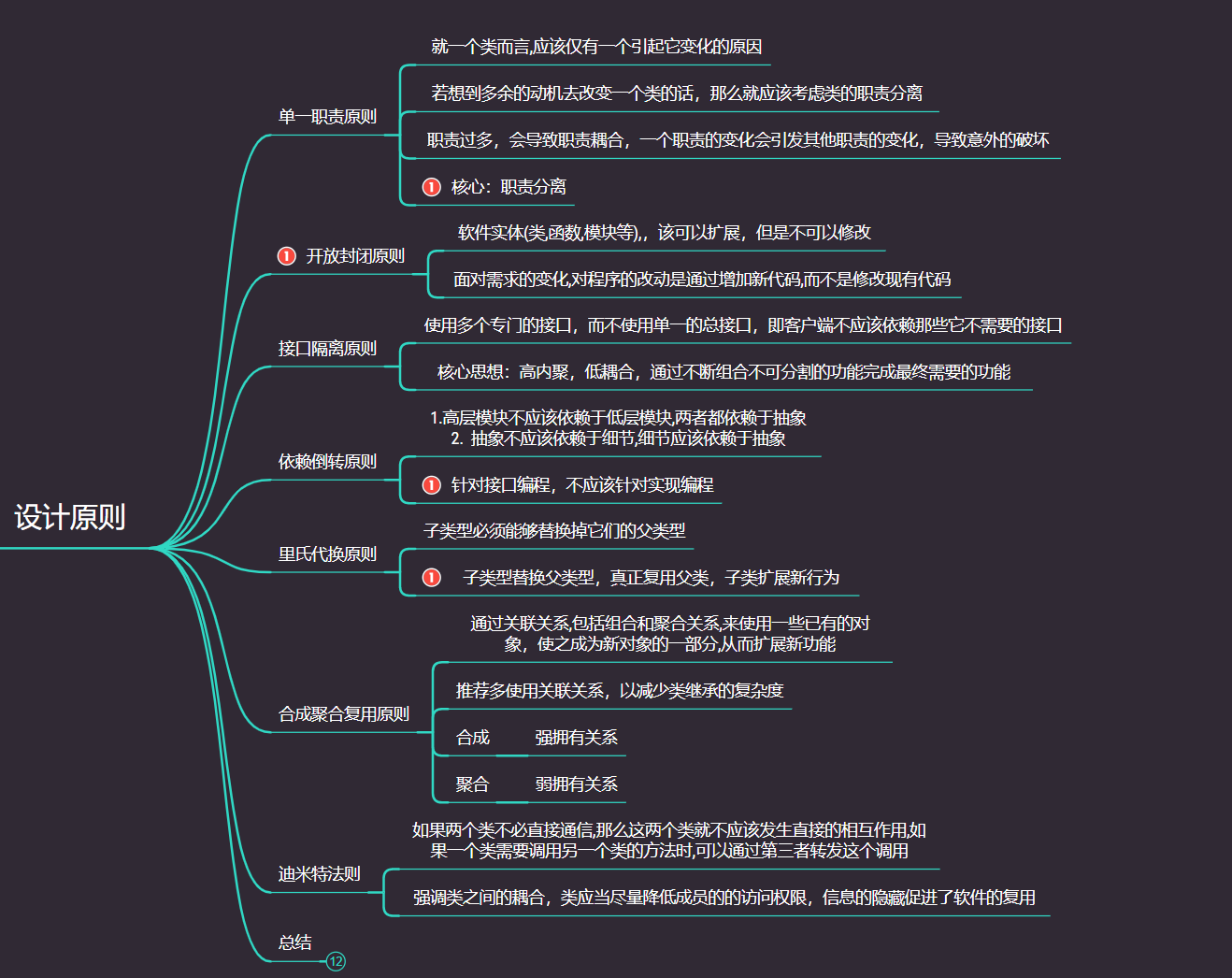
其实我们看完了这些设计原则,就会发现其实都是为了应对不断变化的,在看一些源码中,例如Spring的源码、dubbo的源码、netty的源码中也是非常严谨的遵守这些开发规范的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









