







一、B-Tree 索引
B-Tree index 也是我们传统上常见所理解的索引。B-tree (balance tree)即平衡树,左右两个分支相对平衡。
B-Tree index

Root 为根节点,branch 为分支节点,leaf 到最下面一层称为叶子节点。每个节点表示一层,当查找某一数据时先读根节点,再读支节点,最后找到叶子节点。叶子节点会存放 index entry (索引入口),每个索引入口对应一条记录。
Index entry 的组成部分:
Indexentry entry header 存放一些控制信息。
Key column length 某一 key 的长度
Key column value 某一个 key 的值
ROWID 指针,具体指向于某一个数据

上面这张图能更加清晰的描述索引的结构。
根节点记录 0 至 50 条数据的位置,分支节点进行拆分记录 0 至 10…42 至 50,叶子节点记录每个数据的长度和值,并由指针指向具体的数据。
最后一层的叶子节是双向链接,它们是被有序的链接起来,这样才能快速锁定一个数据范围。
二、位图索引
位图索引主要针对大量相同值的列而创建。拿全国居民登录一第表来说,假设有四个字段:姓名、性别、年龄、和身份证号,年龄和性别两个字段会产生许多相同的值,性别只有男女两种值,年龄,1 到 120(假设最大年龄 120 岁)个值。那么不管一张表有几亿条记录,但根据性别字段来区分的话,只有两种取值(男、女)。那么位图索引就是根据字段的这个特性所建立的一种索引。
Bitmap Index

从上图,我们可以看出,一个叶子节点(用不同颜色标识)代表一个 key , start rowid 和 end rowid规定这种类型的检索范围,一个叶子节点标记一个唯一的 bitmap 值。因为一个数值类型对应一个节点,当是行查询时,位图索引通过不同位图取值直接的位运算(与或),来获取到结果集合向量(计算出的结果)。
举例讲解:
假设存在数据表 T,有两个数据列 A 和 B,取值如下,我们看到 A 和 B 列中存在相同的数据。
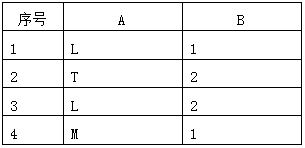
对两个数据列 A、B 分别建立位图索引:idx_t_bita 和 idx_t_bitb。两个索引对应的存储逻辑结构
如下:
Idx_t_bita 索引结构,对应的是叶子节点:
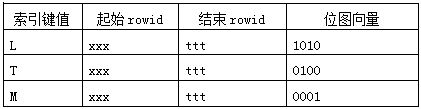
Idx_t_bitb 索引结构,对应的是叶子节点:
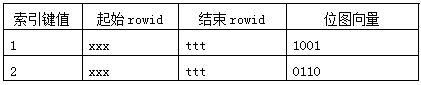
select * from t where b=1 and (a=’L’ or a=’M’)
分析:位图索引使用方面,和 B树索引有很大的不同。B树索引的使用,通常是从根节点开始,经过不断的分支节点比较到最近的符合条件叶子节点。通过叶子节点上的不断 Scan 操作,“扫描”出结果集合 rowid。
而位图索引的工作方式截然不同。通过不同位图取值直接的位运算(与或),来获取到结果集合向量(计算出的结果)。
针对实例 SQL,可以拆分成如下的操作:
1、a=’L’ or a=’M’
a=L:向量:1010
a=M:向量:0001
or 操作的结果,就是两个向量的或操作:结果为 1011。
2、结合 b=1 的向量
中间结果向量:1011
B=1:向量:1001
and 操作的结果,1001。翻译过来就是第一和第四行是查询结果。
3、获取到结果 rowid
目前知道了起始 rowid 和终止 rowid,以及第一行和第四行为操作结果。可以通过试算的方法获
取到结果集合 rowid。
位图索引的特点:
1.Bitmap 索引的存储空间节省
2.Bitmap 索引创建的速度快
3.Bitmap 索引允许键值为空
4.Bitmap 索引对表记录的高效访问















 2144
2144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









