







从这篇总结文档开始将着眼于我们使用的技术的详细分析。
2.4 搜索的概念
评分因子
本篇总结的目的不在于对
Lucene
的概念和设计进行详细介绍,重点是介绍怎么样去使用
Lucene
来达到针对自己业务需求的全文检索,如果想要深入了解
Lucene
的话本文可能不太适合。但是对于那些以前从来没有在项目中使用过
Lucene
索引引擎的人来说,读完本文后,我想应该可以将
Lucene
集成 到你的项目中去了。
说明:本项目的搜索模块是我们团队的赵宁同学负责实现细节,感谢他的辛苦研究。
下面的技术总结是我跟赵宁同学一起完成的。
网上有关Lucene 介绍的技术文章跟资料很多,大家都很容易找到,所以本文主要的重点是放在结合我们的项目如何使用上来说的。
1 Lucene 简介
Lucene 是一个高性能的、可扩展的信息检索工具库。 Lucene 用简单易用的 API 隐藏了复杂的索引和搜索操作的实现过程,因此可以使应用程序专注于自身的业务领域。所以你可以将 Lucene 视为应用程序之下的一个接口层。
说明:本项目的搜索模块是我们团队的赵宁同学负责实现细节,感谢他的辛苦研究。
下面的技术总结是我跟赵宁同学一起完成的。
网上有关Lucene 介绍的技术文章跟资料很多,大家都很容易找到,所以本文主要的重点是放在结合我们的项目如何使用上来说的。
1 Lucene 简介
Lucene 是一个高性能的、可扩展的信息检索工具库。 Lucene 用简单易用的 API 隐藏了复杂的索引和搜索操作的实现过程,因此可以使应用程序专注于自身的业务领域。所以你可以将 Lucene 视为应用程序之下的一个接口层。
2 Lucene在Cactus项目中的应用
2.1
使用Lucene
索引引擎的原因
本项目是一个
Web
服务的搜索与执行
(
目前来说,搜索的是本地索引文件
)
,所以说存在有大量地基于关键字的搜索,还有一个原因是项目还加进去了类似百度,
Google
那样的高级搜索如,包含以下全部的关键词,包含以下的完整关键词等,我想这方面如果说使用传统的关系型数据库的话,就必须得用上复杂的算法来实现了。总的来说就是本项目的其中一个典型需求所决定的:搜索。记得以前在做数据库的课程设计 时其中有一个就是有关数据库索引的,使用关系数据库时,通过编程做有关索引工作相对来说会复杂,但是我们知道索引确实能使查询大大优化,最大的一个是使查询优化了
99.76%
。
2.2
基本概念以及工作流程
为了更加容易理解接下来将要介绍的内容,在这里先介绍在使用 Lucene 时经常碰到的一些概念,我想使用关系数据库来类比 Lucene 中的一些概念会很好地理解。
使用 Lucene 进行全文检索的过程有点类似数据库的这个过程。
数据库表 table--- 查询相应的字段或查询条件 ---- 返回相应的记录:
(1) 通过 IndexWriter 在指定的目录建立索引表文件,相当于数据库中的 table
(2) 将需要检索的数据转换为 Document 的 Filed 对象,然后将 Document 用 IndexWriter 添加到索引表中。
在构建一个索引表时需要指定的为该索引表采用何种方式进行构建,也就是说对于其中的记录的字段以什么方式来进行格式的划分,这个在 Lucene 中称为 Analyzer , Lucene 提供了几种环境下使用的 Analyzer : SimpleAnalyzer 、 StandardAnalyzer 、 GermanAnalyzer 等,其中 StandardAnalyzer 是经常使用的,因为它提供了对于中文的支持,在索引表建好之后我们就需要往里面插 入用于索引的记录,在 Lucene 中这个称为 Document ,有点类似数据库中 table 的一行记录,记录中的字段的添加方法,在 Lucene 中称为 Field ,中文意思即域,这个和数据库中基本一样,对于域, Lucene 分为可被分析,被索引的,被存储的几种组合类型,通过这几个元素基本上就可以建立起索引了。我们项目建好后的索引如下表 1 所示。
(3) 处理索引信息,关闭 IndexWriter 流。
(4) 创建搜索的 Query 。
Lucene 提供了几种经常可以用到的 Query : TermQuery 、 MultiTermQuery 、 BooleanQuery 、 WildcardQuery 、 PhraseQuery 、 PrefixQuery 、 PhrasePrefixQuery 、 FuzzyQuery 、 RangeQuery 、 SpanQuery , Query 其实也就是指对于需要查询的字段采用什么样的方式进行查询,如模糊查询、语 义查询、短语查询、范围查询、组合查询等,还有就是 QueryParser , QueryParser 可用于创建不同的 Query ,还有一个 MultiFieldQueryParser 支持对于多个字段进行同一关键字的查询。
(5) 在程序中使用 IndexSearcher 。
IndexSearcher 概念指的是为需要对何目录下的索引文件进行何种方式的分析的查询,类似于对数据库的哪种索引表进 行查询并按一定方式进行记录中字段的分解查询的概念,通过 IndexSearcher 以及 Query 即可查询出需要的结果, Lucene 返回的为结果集是 Hits. 通过遍历 Hits 可获取返回的结果的 Document ,通过 Document 则可获取域中的相关信息了。
补 Document 的字段类型:
下面打 √ 表示可以,打 × 表示不可以。
为了更加容易理解接下来将要介绍的内容,在这里先介绍在使用 Lucene 时经常碰到的一些概念,我想使用关系数据库来类比 Lucene 中的一些概念会很好地理解。
使用 Lucene 进行全文检索的过程有点类似数据库的这个过程。
数据库表 table--- 查询相应的字段或查询条件 ---- 返回相应的记录:
(1) 通过 IndexWriter 在指定的目录建立索引表文件,相当于数据库中的 table
(2) 将需要检索的数据转换为 Document 的 Filed 对象,然后将 Document 用 IndexWriter 添加到索引表中。
在构建一个索引表时需要指定的为该索引表采用何种方式进行构建,也就是说对于其中的记录的字段以什么方式来进行格式的划分,这个在 Lucene 中称为 Analyzer , Lucene 提供了几种环境下使用的 Analyzer : SimpleAnalyzer 、 StandardAnalyzer 、 GermanAnalyzer 等,其中 StandardAnalyzer 是经常使用的,因为它提供了对于中文的支持,在索引表建好之后我们就需要往里面插 入用于索引的记录,在 Lucene 中这个称为 Document ,有点类似数据库中 table 的一行记录,记录中的字段的添加方法,在 Lucene 中称为 Field ,中文意思即域,这个和数据库中基本一样,对于域, Lucene 分为可被分析,被索引的,被存储的几种组合类型,通过这几个元素基本上就可以建立起索引了。我们项目建好后的索引如下表 1 所示。
(3) 处理索引信息,关闭 IndexWriter 流。
(4) 创建搜索的 Query 。
Lucene 提供了几种经常可以用到的 Query : TermQuery 、 MultiTermQuery 、 BooleanQuery 、 WildcardQuery 、 PhraseQuery 、 PrefixQuery 、 PhrasePrefixQuery 、 FuzzyQuery 、 RangeQuery 、 SpanQuery , Query 其实也就是指对于需要查询的字段采用什么样的方式进行查询,如模糊查询、语 义查询、短语查询、范围查询、组合查询等,还有就是 QueryParser , QueryParser 可用于创建不同的 Query ,还有一个 MultiFieldQueryParser 支持对于多个字段进行同一关键字的查询。
(5) 在程序中使用 IndexSearcher 。
IndexSearcher 概念指的是为需要对何目录下的索引文件进行何种方式的分析的查询,类似于对数据库的哪种索引表进 行查询并按一定方式进行记录中字段的分解查询的概念,通过 IndexSearcher 以及 Query 即可查询出需要的结果, Lucene 返回的为结果集是 Hits. 通过遍历 Hits 可获取返回的结果的 Document ,通过 Document 则可获取域中的相关信息了。
补 Document 的字段类型:
下面打 √ 表示可以,打 × 表示不可以。
被分析: 就好像我们在使用百度
,Google
时一样,输入的关键字是在名称跟描述里匹配的,在我们项目里也就是只匹配
Web
服务的名称跟
Web
服务的详细描述就行了,这就是可被分析的。
被索引:指不需要分析器解析但需要被编入索引并保存到索引中的部分。
JavaSourceCodeIndexer
类使用该字段来保存导入类的声明。
被存储:如果说一个域可被存储,那么其值将会被保存到索引表中。
|
域
|
描述
|
被分析
|
被索引
|
被存储
|
|
servicename
|
该Web
服务的名称
|
√
|
√
|
√
|
|
servicedescription
|
该Web
服务的详细描述
|
√
|
√
|
√
|
|
wsdllocation
|
该Web
服务的WSDL
|
×
|
√
|
√
|
|
providerid
|
该Web
服务的提供者ID
|
×
|
√
|
√
|
|
date
|
该Web
服务的最新提交日期
|
×
|
√
|
√
|
|
serviceid
|
该Web
服务的ID
|
×
|
√
|
√
|
|
clicktimes
|
该Web
服务被点击的次数(排序)
|
×
|
√
|
√
|
|
executetimes
|
该Web
服务被执行的次数
|
×
|
√
|
√
|
|
executeoktimes
|
该Web
服务被执行成功的次数
|
×
|
√
|
√
|
|
percent
|
该Web
服务执行的成功率(排序)
|
×
|
√
|
√
|
表
1
建立索引
跟传统关系数据库的一些概念比较,用表格画出来如表 2 所示。
跟传统关系数据库的一些概念比较,用表格画出来如表 2 所示。
|
Lucene
|
传统表
|
说明
|
|
IndexWriter
|
table
|
|
|
Document
|
一条记录
|
|
|
Field
|
每个字段
|
分为可被索引的,可切分的,不可被切分的,不可被索引的几种组合类型
|
|
Hits
|
RecoreSet
|
结果集
|
表
2
与传统关系数据库的比较
通过对于上面在建立索引和全文检索的基本概念的介绍,我想对
Lucene
,我们已经建立一定的了解了。
接下来介绍如何处理索引文件。
2.3 分析器
接下来介绍如何处理索引文件。
2.3 分析器
Lucene
使用分析器来处理被索引的文本。在将其存入索引之前,分析器用于将文本标记化、摘录有关的单词、丢弃共有的单词、处理派生词(把派生词还原到词根形式,意思是把
smiling
、
smiled
和
smiles
还原为
smile
)和完成其它要做的处理。
我们都知道汉语、日语以及韩语(统称为 CJK )等亚洲语种,一般使用表意文字,而不是使用由字母组成的单词。这些象形字符不一定通过空格来分隔的,所以我们需要使用一种完全不同的分析方法来识别和分隔语汇单元。 Lucene 提供的通用分析器是:
SimpleAnalyzer :用字符串标记一组单词并且转化为小写字母。
StandardAnalyzer :用字符串标记一组单词,可识别缩写词、 email 地址、主机名称等等。并丢弃基于英语的 stop words (a, an, the, to) 等、处理派生词。 StanderAnalyzer 是 Lucene 内置的唯一能够处理亚洲语言的分析器,该分析器可以将一定范围内的 Unicode 编码识别为 CJK 字符并将它们切分为独立的语汇单元。
我们都知道汉语、日语以及韩语(统称为 CJK )等亚洲语种,一般使用表意文字,而不是使用由字母组成的单词。这些象形字符不一定通过空格来分隔的,所以我们需要使用一种完全不同的分析方法来识别和分隔语汇单元。 Lucene 提供的通用分析器是:
SimpleAnalyzer :用字符串标记一组单词并且转化为小写字母。
StandardAnalyzer :用字符串标记一组单词,可识别缩写词、 email 地址、主机名称等等。并丢弃基于英语的 stop words (a, an, the, to) 等、处理派生词。 StanderAnalyzer 是 Lucene 内置的唯一能够处理亚洲语言的分析器,该分析器可以将一定范围内的 Unicode 编码识别为 CJK 字符并将它们切分为独立的语汇单元。
ChineseAnalyzer
,它是一个单字分析法,它把句子中的词全部分成一个一个的字符,以单个字为单位存储。
CJKAnalyzer
,它是双字分析法,它把中文以双字为单位拆分得到结果,从而建立词条。当然这些得到的双字词中会有很多不符合中文语义单位的双字被送进索引。
CJKAnalyzer 和 ChineseAnalyzer 可以在 Lucene 的 Sandbox 工具包中找到,不过在已发布的 Lucene 核心版本中还没有 包含这些类。 CJKAnalyzer 类将每两个前后相连的字符组合在一起。这是因为很多的 CJK 单词都是由两个字符所组成。通过这种方式对字符进行组合 后,这些新组成的词语就被可以保存在一起了(不过不能组成词语的两个字也被组合在一起,这将增大索引文件的规模)。在我们的项目中 ChineseAnalyzer 使用了一个更为简单的方法它使用 Lucene 中内置 StandardAnalyzer 类将中文句子切分成单个汉字从而得到 结果。由多个汉字组成的词语按照构成词语的每个汉字被切分为各个单独的项。
CJKAnalyzer 和 ChineseAnalyzer 可以在 Lucene 的 Sandbox 工具包中找到,不过在已发布的 Lucene 核心版本中还没有 包含这些类。 CJKAnalyzer 类将每两个前后相连的字符组合在一起。这是因为很多的 CJK 单词都是由两个字符所组成。通过这种方式对字符进行组合 后,这些新组成的词语就被可以保存在一起了(不过不能组成词语的两个字也被组合在一起,这将增大索引文件的规模)。在我们的项目中 ChineseAnalyzer 使用了一个更为简单的方法它使用 Lucene 中内置 StandardAnalyzer 类将中文句子切分成单个汉字从而得到 结果。由多个汉字组成的词语按照构成词语的每个汉字被切分为各个单独的项。
2.4 搜索的概念
搜索是一个在索引中查找关键字的过程,这个过程的目的是为了找到这些关键字在哪些地方出现过。搜索的质量通常由查确率 (
precise
)和查全率(
recall
)来衡量。查全率可以衡量这个搜索系统查找到相关文档的能力,而查确率则用来衡量搜索系统过滤非相关该当的能 力。当然,也需要考虑很多其他的因素。我们已经得到过快速查找大量文本文件的速度和能力问题。例如:对单一项的查询、多个项的查询、短语查询、通配符、结 果评分、排序等功能的支持以及友好的查询输入语法,对于一个搜索系统而言都是很重要的。
Lucene
强大的软件库提供了大量的搜索特性。
2.5 本项目中搜索的设计
我们的项目主要通过对 servicename 和 servicedescription 两个域中的内容进行关键字匹配来搜索相关的内容。对搜索结果采用以下四种方式进行排序。
相关度
我们的项目默认是以相关度进行排序的。 Lucene 提供了一个相关度评分公式。 Lucene 会为由某一指定查询匹配到的每个文档 d 使用这个公式计算其相应的得分
2.5 本项目中搜索的设计
我们的项目主要通过对 servicename 和 servicedescription 两个域中的内容进行关键字匹配来搜索相关的内容。对搜索结果采用以下四种方式进行排序。
相关度
我们的项目默认是以相关度进行排序的。 Lucene 提供了一个相关度评分公式。 Lucene 会为由某一指定查询匹配到的每个文档 d 使用这个公式计算其相应的得分
表
3
列出了评分公式中的各个因子。
我们没有设置参数,使用的是其默认的值,搜索结果会根据关键字与 servicename 和 servicedescription 两个域中内容的匹配程序按照相似度的值从大到小进行排序。
我们没有设置参数,使用的是其默认的值,搜索结果会根据关键字与 servicename 和 servicedescription 两个域中内容的匹配程序按照相似度的值从大到小进行排序。
-
发布时间
按照项目最新提交的时间进行排序,越新发布的服务排名就越靠前。
-
点击次数
按照
clicktimes
域进行排序,将访问次数高的服务排在前面。
-
成功率
按照
percent
值进行倒序排序,其中
percent=executeoktimes/executetimes100%
评分因子
|
评分因子
|
描述
|
|
tf(t in d)
|
文档d
中出现搜索项t
的频率
|
|
idf(t)
|
搜索项t
在倒排文档中出现的频率
|
|
boost(t.field in d)
|
域的加权因子(boost
),它的值在索引过程中进行设置
|
|
lengthNorm(t.field in d)
|
域的标准化值(normalization value
),即在某一域中所有项的个数。通常在索引时计算该值并将其存储到索引中
|
|
coord(q,d)
|
协调因子(Coordination factor
),该因子的值基于文档中包含查询的项的个数
|
|
queryNorm(q)
|
每个查询的标准化值,指每个查询项权重的平方和
|
表 3
相关度评分公式
2.6
高亮显示查询项
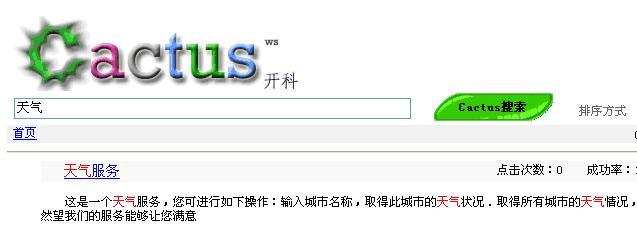
有一个能使搜索引擎变得更友好的办法,那就是向你的用户提供一些搜索命中结果的上下文,而且更为重要的是这样做是非常有用 的。最好的例子就是本系统用户在查找天气
Web
服务时的搜索结果。如下图
1
所示,每个命中结果包括了匹配文档的三行左右的内容,并且将查询项高亮显示出 来。通常,我们只需要对搜索项 上下文内容浏览一眼就足以 了解该结果是否值得我们深入地进行研究。
图4.1
高亮显示查询项
Highlighter 最近已经充分升级为一个复杂而灵活的工具。 Highlighter 包括了三个主要部分:段划分器( Fragmenter )、计分器( Scorer )和格式 化器( Formatter )。这几个部分对应于 Java 的同名接口,并且每部分都有一个内置的实现以便我们使用。最简单的 Highlighter 将返回在 匹配项周围的最佳段落,并使用 HTML 的 <B> 将这些项标记出来:
Highlighter 最近已经充分升级为一个复杂而灵活的工具。 Highlighter 包括了三个主要部分:段划分器( Fragmenter )、计分器( Scorer )和格式 化器( Formatter )。这几个部分对应于 Java 的同名接口,并且每部分都有一个内置的实现以便我们使用。最简单的 Highlighter 将返回在 匹配项周围的最佳段落,并使用 HTML 的 <B> 将这些项标记出来:
String text = “The quick brown fox jumps over the lazy dog”;
TermQuery query = new TermQuery(new Term(“field”, “fox”));
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(scorer);
TokenStream tokenStream =
new SimpleAnalyzer().tokenStream(“field”,
new StringReader(text));
System.out.println(highlighter.getBestFragment(tokenStream,text));
前述代码将产生如下输出
TermQuery query = new TermQuery(new Term(“field”, “fox”));
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(scorer);
TokenStream tokenStream =
new SimpleAnalyzer().tokenStream(“field”,
new StringReader(text));
System.out.println(highlighter.getBestFragment(tokenStream,text));
前述代码将产生如下输出
The quick brown <B>fox</B> jumps over the lazy dog
Highlighter
不仅需要你提供记分器和需要高亮显示的文本,还需要一个
TokenStream
实例。这个
TokenStream
实例是由分析器生成的。为了成功地对项进行高亮显示,
Query
中的这些项需要匹配
TokenStream
产生的
Token
实例。我们提供的文本则被用于生成
TokenStream
,而这个
TokenStream
又被用作高亮显示的原始文本。每个由
TokenStream
生成的
Token
实例都包含语汇单元的位置信息,这些信息用来指示原始文本中高亮部分的起始和结束位置。
Highlighter
利用
Fragmenter
将原始文本分割成多个片段。内置的
SimpleFragmenter
将原始文本分割成相同大小的片段,片段默认的大小为
100
个字符。这个大小是可控制的。
QueryScorer
是内置的计分器。计分器的工作首先是将片段排序。
QueryScorer
使用的项是从用户输入的查询中得到的;它会从原始输入的单词、词组和布尔查询中提取项,并且基于相应的加权因子(
boost factor
)给它们加权。为了便于
QueryScoere
使用,还必须对查询的原始形式进行重写。比如,带通配符查询、模糊查询、前缀查询以及范围查询等,都被重写为
BoolenaQuery
中所使用的项。在将
Query
实例传递到
QueryScorer
之前,可以调用
Query.rewrite(IndexReader)
方法来重写
Query
对象(否则,你必须确保用户输入的查询文本就是
Lucene
直接可以处理最基本的项)。
最后,格式化器(
Formatter
)用于装饰项文本。如果不指定其他的格式化器,
Lucene
会默认使用内置的格式化器
SimpleHTMLFormatter
,这个格式化器将会用
HTML
的黑体开始标签(
begin bold tags <B>
)和黑体结束标签(
end bold tags </B>
)来标识出高亮显示的项文本。
Highlighter
默认地使用
SimpleHTMLFormatter
和
SimpleFragmenter
这两个格式化器。每一个由
Formatter
高亮显示的项都将会带有一个语汇单元评分。当使用
QueryScorer
时,这个评分将作为查询该项的加权因子。这个语汇单元评分能够被用来决定该项的重要性。要利用这个特性就必须实现自定义的格式化器。
注:我们项目所用到的 Lucene API
是基于最新版Lucene2.1
的,如果你用的是以前版本可能这些例子不能很好的运行。不过我觉得看了以上的东西,再结合网上大量的Lucene
资 料还有一些例子就能对Lucene
有一定的理解了,最起码就可以开始使用Lucene
着手项目了。
另外,在文章开始提到了,我们以前一起做项目时没有使用过Lucene ,这次是我们团队的赵宁同学开始接触Lucene ,然后在我们项目中使用这个工具, 我是在他指导的基础上对Lucene 有一点点的理解而已。感兴趣的可以就项目中的更细节问题跟赵宁同学联系:MSN: program-maker@hotmail.com
另外,在文章开始提到了,我们以前一起做项目时没有使用过Lucene ,这次是我们团队的赵宁同学开始接触Lucene ,然后在我们项目中使用这个工具, 我是在他指导的基础上对Lucene 有一点点的理解而已。感兴趣的可以就项目中的更细节问题跟赵宁同学联系:MSN: program-maker@hotmail.com















 4062
4062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









