







jvm大局观之内存管理篇: 理解jvm安全点,写出更高效的代码 - 知乎
前言
本篇是java内存区域管理系列教程之一 - 在得知GC Root的组成之后,如何在垃圾回收发生的时刻,找到GC Root,也就是起始垃圾. 并且能够在平常的编码中,合理的利用安全点,优化已有代码(文末)
全系列内容可在本文专栏-jvm大局观中查阅
jvm全局观?www.zhihu.com/column/c_1293612595426095104正在上传…重新上传取消
看完本篇,读者会明白jvm如何通过根节点遍历与安全区域快速定位gc root的内容,并且优化已有代码(文末)
运行如下代码
public class TestBlockingThread {
static Thread t1 = new Thread(() -> {
while (true) {
long start = System.currentTimeMillis();
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
long cost = System.currentTimeMillis() - start;
(cost > 1010L ? System.err : System.out).printf("thread: %s, costs %d ms\n", Thread.currentThread().getName(), cost);
}
});
static Thread t2 = new Thread(() -> {
while (true) {
for (int i = 1; i <= 1000000000; i++) {
boolean b = 1.0 / i == 0;
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
private static final int _50KB = 50 * 1024;
static Thread t3 = new Thread(() -> {
while (true) {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
byte[] bytes = new byte[_50KB];
}
});
public static void main(String[] args) throws InterruptedException {
t1.start();
Thread.sleep(1500L);
t2.start();
t3.start();
}
}运行上述程序输出如下
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 5684 ms
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 1001 ms
thread: Thread-0, costs 1002 ms
thread: Thread-0, costs 2414 ms
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 1002 ms
thread: Thread-0, costs 1001 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 3585 ms
thread: Thread-0, costs 1000 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 1003 ms知乎显示问题 其中三条日志的红色效果没有呈现出来,就手动加粗了一下,见谅
问题是 --- 为什么t1线程会出现停顿超过1000ms多达甚至5倍的情况?

下面是线程t1中的代码
long start = System.currentTimeMillis();
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
long cost = System.currentTimeMillis() - start;按照常理, 即便算上线程来换抢占CPU的切换时间,cost顶多只会有2000大小的样子,也就是线程t1顶多只会停顿2s左右,但是实际上t1线程每隔一段时间,停顿甚至达到了5s以上
如果直接要解决方案,请直接跳到文末,采取优化方案1或者优化方案2即可
不过笔者还是希望读者能够做一个知根求底的程序员,知其所以然
如果没有理解jvm垃圾收集机制,没有理解根节点枚举以及安全点,也就是本系列教程,可能永远也不明白导致上述问题的原因
对于jvm一知半解和一点都不懂是没什么区别的,这也是本系列教程的目的--jvm大局观
还请读者耐心读完以下正文,才能够全面理解上述程序存在的问题

码字不易,赠人玫瑰,手留余香

正文
我们知道 HotSpot 虚拟机采取的是可达性分析算法来顺着根节点向下搜寻所有可达对象。
也就是说,只要有了GC Roots,我们就能够依据可达性分析算法通过根节点来找出所有可达对象.
经典老图献上
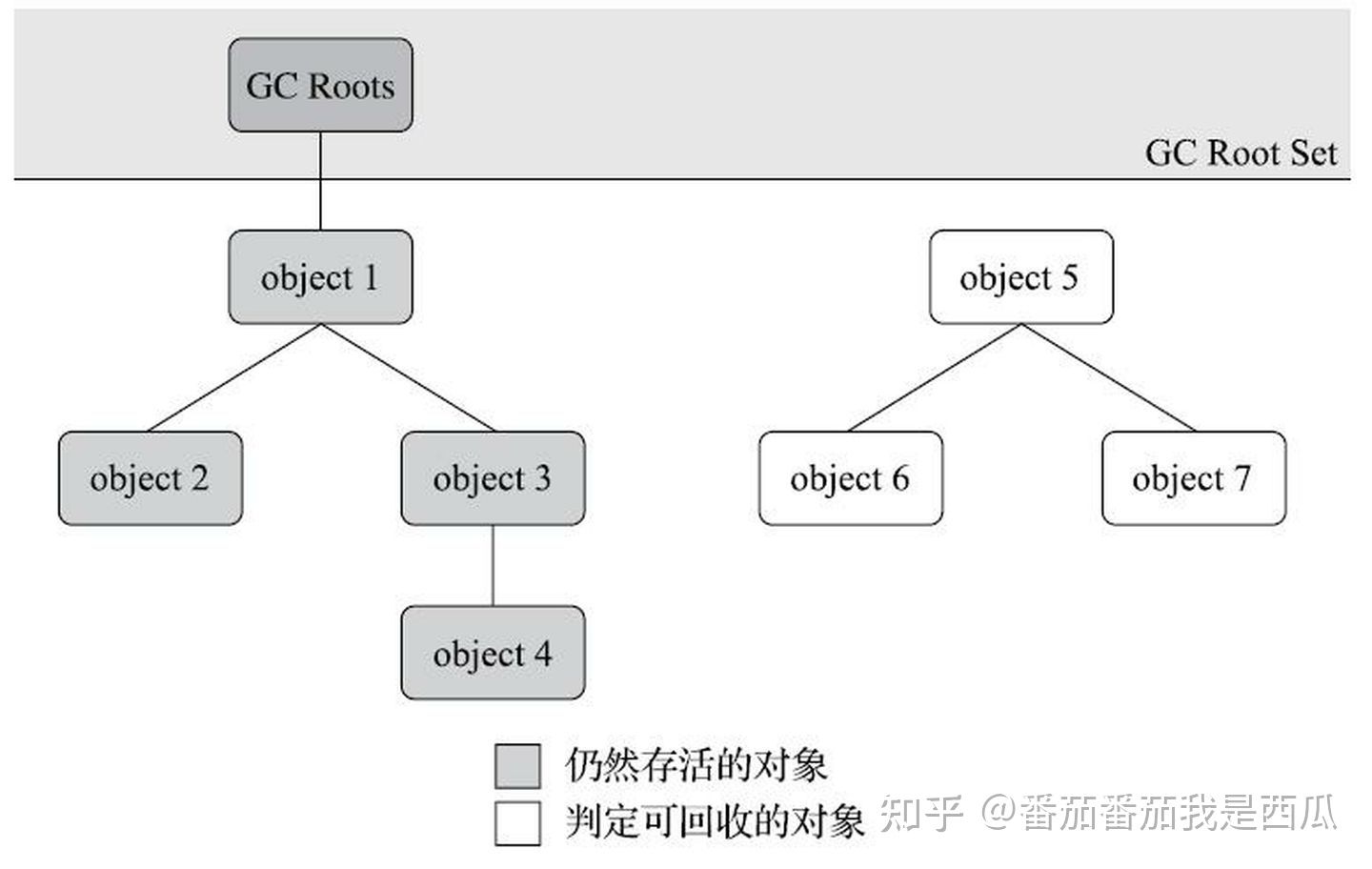
如何找到GC Roots?
有的读者可能会觉得很奇怪,我们在上一篇已经提到过, 固定可作为GC Roots的节点, 不就是 在全局性的引用(例如常量或类静态属性)与执行上下文(例如 栈帧中的本地变量表)中吗
我们不是已经知道GC Roots是哪些了吗?
实际上, 尽管目标明确,但查找过程要做到高效并非一件容易的事情, 知道它是什么,和能够精确的找到它,是两码事, 想要更快速的找到它,又是一码事,所以才有了这篇文章
现在Java应用越做越庞大,光是方法区的大小就常有数百上千兆,里面的类、常量等更是车载斗量,如果在这日渐庞大的栈区和方法区中,逐地址寻找引用,对于这个应用的性能来说,一定会是个灾难.

称之为灾难主要有两大原因
1是根节点枚举的时间会随着方法区和栈区的大小成正比
2是根节点枚举期间需要停止jvm(STW,stop the world)
提示: 原因2正是示例程序会停顿超过额定1s至5倍 5s的直接原因.
为何列出gc root期间,需要停止世界
现在可达性分析算法耗时最长的查找引用链的过程已经可以做到与用户线程一起并发(具体见java如何判断哪些对象该被回收的文末),但根节点枚举始终还是必须在一个能保障一致性的快照中才得以进行
这里“一致性”的意思是整个枚举期间执行子系统 看起来就像被冻结在某个时间点上,不会出现分析过程中,根节点集合的对象引用关系还在不断变化 的情况,若这点不能满足的话,分析结果准确性也就无法保证。
扩展: 这个"被冻结在某个时间点上"就是后面要提到的 主动式中断
这是导致垃圾收集过程必须停顿所有用户线程的其中一个重要原因,即使是号称停顿时间可控,或者(几乎)不会发生停顿的CMS、G1、 ZGC等收集器,枚举根节点时也是必须要停顿的。
由于目前主流Java虚拟机使用的都是准确式垃圾收集
保守式 GC: 遍历方法区和栈区查找 ;
准确式 GC: 通过后文提到的称之为 OopMap 的数据结构来记录 GC Roots 的位置
实际上当用户线程停顿下来之后,其实并不需要一个不漏地检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法直接得到哪些地方存放着对象引用的。
在HotSpot 的解决方案里,是使用一组称为OopMap的数据结构来达到这个目的。
一旦类加载动作完成的时候, HotSpot就会把对象内什么偏移量上是什么类型的数据计算出来。这样收集器在扫描时就可以直接得知这些信息了,并不需要真正一个不漏地从方法区等GC Roots开始查找。
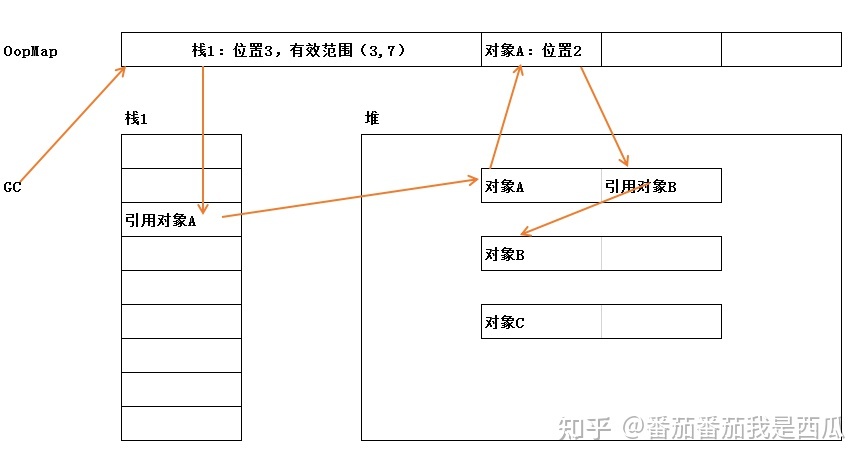
下面代码是HotSpot虚拟机客户端模式下生成的一段String::hashCode()方法的本地代码,可以看到在0x026eb7a9处的call指令有OopMap记录,它指明了EBX寄存器和栈中偏移量为16的内存区域 中各有一个普通对象指针(Ordinary Object Pointer,OOP)的引用,有效范围为从call指令开始直到 0x026eb730(指令流的起始位置)+142(OopMap记录的偏移量)=0x026eb7be,即hlt指令为止。
[Verified Entry Point]
0x026eb730: mov %eax,-0x8000(%esp)
…………
;; ImplicitNullCheckStub slow case
0x026eb7a9: call 0x026e83e0 ; OopMap{ebx=Oop [16]=Oop off=142}
; *caload
; - java.lang.String::hashCode@48 (line 1489)
; {runtime_call}
0x026eb7ae: push $0x83c5c18 ; {external_word}
0x026eb7b3: call 0x026eb7b8
0x026eb7b8: pusha
0x026eb7b9: call 0x0822bec0 ; {runtime_call}
0x026eb7be: hlt安全点
在OopMap的协助下,HotSpot可以快速准确地完成GC Roots枚举,但一个很现实的问题随之而来:可能导致引用关系变化,或者说导致OopMap内容变化的指令非常多,如果为每一条指令都生成 对应的OopMap,那将会需要大量的额外存储空间,这样垃圾收集伴随而来的空间成本就会变得无法忍受的高昂。
实际上HotSpot也的确没有为每条指令都生成OopMap,前面已经提到,只是在“特定的位置”记录 了这些信息,这些位置被称为安全点(Safepoint)。
有了安全点的设定,也就决定了用户程序执行时并非在代码指令流的任意位置都能够停顿下来开始垃圾收集,而是强制要求必须执行到达安全点后才能够暂停。
程序运行期间,很多指令都是有可能修改引用关系的,即要修改OopMap。如果碰到就修改,那代价是十分大的,故而引入了 SafePoint,只在 SafePoint 才会对 OopMap 做一个统一的跟新。这也使得,只有 SafePoint 处 OopMap 是一定准确的,因此只能在 SafePoint 处进行 GC 行为。
因此,安全点的选定既不能太少以至于让收集器等待时间过长,也不能太过频繁以至于过分增大运行时的内存负荷。
安全点位置的选取基本上是以“是否具有让程序长时间执行的特征”为标准 进行选定的
HotSpot会在所有方法的临返回之前,以及所有非counted loop的循环的回跳之前放置安全点。
“长时间执行”的最明显特征就是指令序列的复用,例如方法调用、循环跳转、异常跳转 等都属于指令序列复用,所以只有具有这些功能的指令才会产生安全点。
为什么把这些位置设置为jvm的安全点呢
主要目的就是避免程序长时间无法进入safepoint,比如JVM在做GC之前要等所有的应用线程进入到安全点后VM线程才能分派GC任务 ,如果有线程一直没有进入到安全点,就会导致GC时JVM停顿时间延长,比如文章开头提到的类似问题.
对于安全点,另外一个需要考虑的问题是
如何在垃圾收集发生时让所有线程(这里其实不包括 执行JNI调用的线程)都跑到最近的安全点,然后停顿下来。这个停顿正是根节点枚举期间,产生Stop The World 全局性停顿的原因
这里有两种方案可供选择:
主动式中断(Voluntary Suspension)和 抢先式中断 (Preemptive Suspension)
主动式中断
主动式中断的思想是当垃圾收集需要中断线程的时候,不直接对线程操作,仅仅简单地设置一 个标志位,各个线程执行过程时会不停地主动去轮询这个标志,一旦发现中断标志为真时就自己在最近的安全点上主动中断挂起。轮询标志的地方和安全点是重合的,另外还要加上所有创建对象和其他 需要在Java堆上分配内存的地方,这是为了检查是否即将要发生垃圾收集,避免没有足够内存分配新 对象。
由于轮询操作在代码中会频繁出现,这要求它必须足够高效。HotSpot使用内存保护陷阱的方式, 把轮询操作精简至只有一条汇编指令的程度。下面代码中的test指令就是HotSpot生成的轮询指 令,当需要暂停用户线程时,虚拟机把0x160100的内存页设置为不可读,那线程执行到test指令时就会 产生一个自陷异常信号,然后在预先注册的异常处理器中挂起线程实现等待,这样仅通过一条汇编指 令便完成安全点轮询和触发线程中断了。
0x01b6d627: call
0x01b2b210
0x01b6d62c: nop
0x01b6d62d: test 0x01b6d633: mov
; OopMap{[60]=Oop off=460} ; *invokeinterface size ; - Client1::main@113 (line 23) ; {virtual_call} ; OopMap{[60]=Oop off=461} ; *if_icmplt ; - Client1::main@118 (line 23) ; {poll}
%eax,0x160100 0x50(%esp),%esi
0x01b6d637: cmp %eax,%esi抢先式中断
而抢先式中断不需要线程的执行代码 主动去配合,在垃圾收集发生时,系统首先把所有用户线程全部中断,如果发现有用户线程中断的地方不在安全点上,就恢复这条线程执行,让它一会再重新中断,直到跑到安全点上。现在几乎没有虚拟机实现采用抢先式中断来暂停线程响应GC事件。
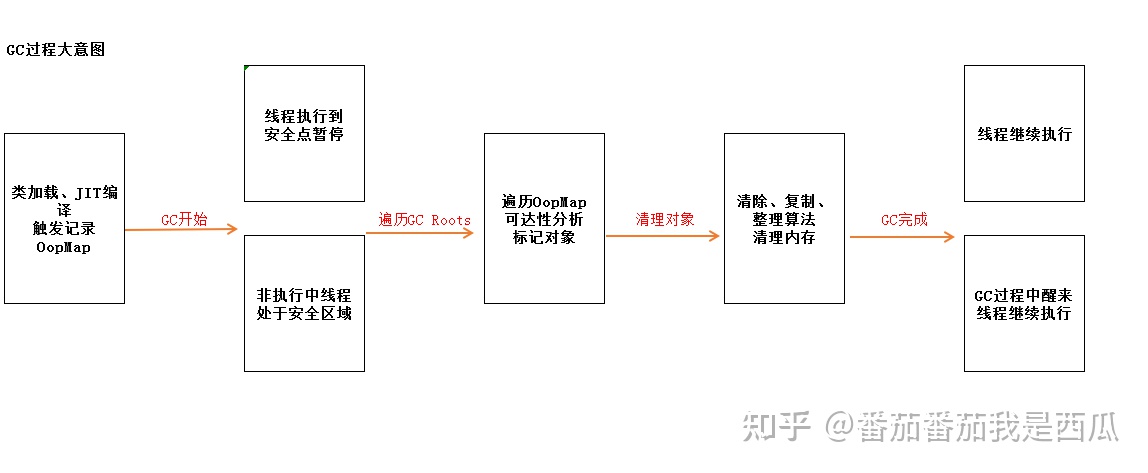
安全区域
使用安全点的设计似乎已经完美解决如何停顿用户线程,让虚拟机进入垃圾回收状态的问题了, 但实际情况却并不一定。
安全点机制保证了程序执行时,在不太长的时间内就会遇到可进入垃圾收集 过程的安全点。但是,程序“不执行”的时候呢?
所谓的程序不执行就是没有分配处理器时间,典型的 场景便是用户线程处于Sleep状态或者Blocked状态,这时候线程无法响应虚拟机的中断请求,不能再走到安全的地方去中断挂起自己,虚拟机也显然不可能持续等待线程重新被激活分配处理器时间。
对于 这种情况,就必须引入安全区域(Safe Region)来解决。
安全区域
安全区域是指能够确保在某一段代码片段之中,引用关系不会发生变化,因此,在这个区域中任意地方开始垃圾收集都是安全的。我们也可以把安全区域看作被扩展拉伸了的安全点。
当用户线程执行到安全区域里面的代码时,首先会标识自己已经进入了安全区域,那样当这段时间里虚拟机要发起垃圾收集时就不必去管这些已声明自己在安全区域内的线程了。当线程要离开安全区域时,它要检查虚拟机是否已经完成了根节点枚举(或者垃圾收集过程中其他需要暂停用户线程的 阶段),如果完成了,那线程就当作没事发生过,继续执行;否则它就必须一直等待,直到收到可以 离开安全区域的信号为止。
扩展1: 案例
先查看如下代码以及运行结果
public class TestBlockingThread {
static Thread t1 = new Thread(() -> {
while (true) {
long start = System.currentTimeMillis();
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
long cost = System.currentTimeMillis() - start;
//按照正常情况,t1线程,大致上应是每隔1000毫秒左右,会输出一句话 我们使用 cost 来记录实际等待的时间
//如果实际时间cost大于1010毫秒 我们就使用System.err输出,也就是红色字样的输出,否则则是正常输出
(cost > 1010L ? System.err : System.out).printf("thread: %s, costs %d ms\n", Thread.currentThread().getName(), cost);
}
});
static Thread t2 = new Thread(() -> {
while (true) {
//下面是一个counted loop,单次循环末尾不会被加入安全点,整个for循环期执行结束之前,都不会进入安全点
//存在这样一种情况, 如果某次for循环才刚刚开始没多久, 因为内存过多而需要进行垃圾收集
//而我们知道,垃圾收集刚开始的时候需要先获取所有根节点,而根节点的获取依赖所有线程抵达安全点
//线程t1很简单,只需要隔1s就会进入安全点,之后,线程t1需要等到其他线程(t2)也进入到安全点
//而t2此时才刚刚是for循环的刚开始,所以需要消耗大量时间走完剩下的循环次数,这也就是为什么有时候t1实际cost时间多达5s的原因
//也就是gc发生时,要获取所有根节点,而想要获取根节点,就要所有线程抵达安全点,已经抵达的线程(t1)需要等待未抵达的线程(t2)到达安全点 然后才会继续垃圾收集的剩下内容
for (int i = 1; i <= 1000000000; i++) {
boolean b = 1.0 / i == 0;
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
private static final int _50KB = 50 * 1024;
//下面的代码在创建大量的对象, 一定会导致隔一段时间会出现垃圾收集
static Thread t3 = new Thread(() -> {
while (true) {
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
byte[] bytes = new byte[_50KB];
}
});
public static void main(String[] args) throws InterruptedException {
t1.start();
Thread.sleep(1500L);
t2.start();
t3.start();
}
}运行上述程序输出如下
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 5684 ms
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 1001 ms
thread: Thread-0, costs 1002 ms
thread: Thread-0, costs 2414 ms
thread: Thread-0, costs 1003 ms
thread: Thread-0, costs 1002 ms
thread: Thread-0, costs 1001 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 3585 ms
thread: Thread-0, costs 1000 ms
thread: Thread-0, costs 1004 ms
thread: Thread-0, costs 1003 ms知乎的原因 导致 其中三条日志的红色效果没有呈现出来,我就手动加粗了一下,见谅
为什么t1线程会出现停顿超过1000ms多达甚至5倍的情况?
如果没有理解jvm垃圾收集,没有理解根节点枚举以及安全点,也就是本系列教程和本篇,可能永远也不明白
优化和解决方案
优化方案一: 使用java1.8.131或者以上的版本, 在jvm运行参数中加-XX:+UseCountedLoopSafepoints
java1.8.131以下的版本使用这个jvm参数会有 bug
这种方式一劳永逸,程序中的所有的循环以后都不会再发生同类问题
优化方案二: for循环中的int类型的i改变为long类型
如果自己的jdk版本低于java1.8.131,又不被允许升级java版本,可以采取这个优化方案二
for (long i = 1; i <= 1000000000; i++) {
boolean b = 1.0 / i == 0;
}两种优化方案都有一定的代价,就是由于多了一些安全点,所以内存会占用的比原来更大一些
原理
前面我们知道了,jvm在垃圾收集刚发生的时刻,会先进行根节点枚举,然后顺着根节点向下搜寻所有可达对象。
本篇文章中我们也知道了,根节点枚举的时候需要所有的线程先早到安全点的位置,所以如果有部分线程迟迟走不到安全点,会导致程序中的所有其他线程在等待这个线程,直到那个线程走到安全点,所以说,我们需要避免写出这样的代码,也就是线程中不应当出现执行了大量耗时操作,但是耗时操作期间没有任何安全点的问题
本篇文章我们也说到了, 安全点所在位置: “长时间执行”的最明显特征就是指令序列的复用,例如方法调用、循环跳转、异常跳转 等都属于指令序列复用,所以只有具有这些功能的指令才会产生安全点。
上面的代码中出现的for循环叫做counted loop, 就是有明确的循环计数器变量,而且该变量有明确的起始值、终止值、步进长度的循环。它有可能被优化为循环末尾没有safepoint,于是如果这个循环的循环次数很多、循环体里又不调用别的方法或者是调用了方法但被内联进来了,就有可能会导致进入safepoint非常耗时。
"不调用别的方法或者是调用了方法但被内联" ,调用别的方法或者调用了方法但被内联会产生安全点,如果这个循环里面没有做这些,也就是不存在任何安全点
优化方案1,正是通过 修改jvm设定安全点的规则来达到在t2线程中加入安全点
优化方案2,正是通过 通过适应jvm设定安全点的规则来达到在t2线程中加入安全点















 7634
7634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









