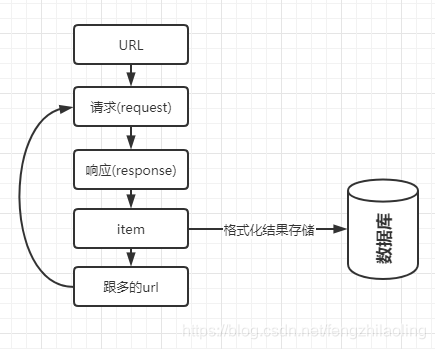
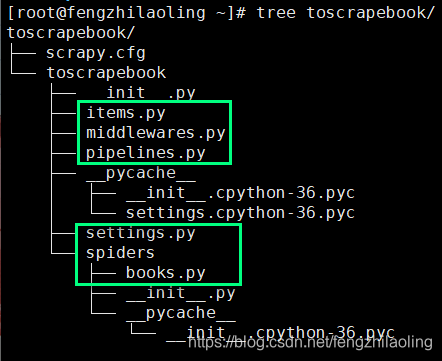
基本流程图 scrapy项目中各个文件作用 我们通过一个爬取书籍名称和价格的爬虫来进行说明 爬取网址:http://books.toscrape.com 这是一个专门用于爬虫练习网站 在框中的文件是我们需要知道和关注的 item.py:定义scrapy的输出内容 middlewares.py:定义各种中间件,主要为了处理各种request和response pipelines.py:定义管的,如何处理抓取的文件 setting.py:项目配置文件,所有的管道、中间件等其他参数必须在setting.py中激活才能生效 spiders:目录中用于存放所有的爬虫文件








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






