







oracle 数据处理过程中经常遇到数据行列转换的需求,故现整理自己用的一些方法供大家参考
方法一:
使用自带的转换函数wmsys.wm_concat()
源数据如下
select t.rank, t.Name from t_menu_item t;
10 CLARK
10 KING
10 MILLER
20 ADAMS
20 FORD
20 JONES
20 SCOTT
20 SMITH
30 ALLEN
30 BLAKE
30 JAMES
30 MARTIN
30 TURNER
30 WARD
我们通过 10g 所提供的 WMSYS.WM_CONCAT 函数即可以完成 行转列的效果
select t.rank, WMSYS.WM_CONCAT(t.Name) TIME From t_menu_item t GROUP BY t.rank; DEPTNO ENAME
10 CLARK, KING, MILLER
20 ADAMS, FORD, JONES, SCOTT, SMITH
30 ALLEN, BLAKE, JAMES, MARTIN, TURNER, WARD
这种方法转换得到的数据是以“,”分割的字符串数据。
方法二:
自己构建转换函数,实现行转列。
函数代码如下:
CREATE OR REPLACE
type PivotImpl as object
(
ret_type anytype, -- The return type of the table function
stmt varchar2(32767),
fmt varchar2(32767),
cur integer,
static function ODCITableDescribe( rtype out anytype, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 )
return number,
static function ODCITablePrepare( sctx out PivotImpl, ti in sys.ODCITabFuncInfo, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 )
return number,
static function ODCITableStart( sctx in out PivotImpl, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 )
return number,
member function ODCITableFetch( self in out PivotImpl, nrows in number, outset out anydataset )
return number,
member function ODCITableClose( self in PivotImpl )
return number
)
/
create or replace type body PivotImpl as
static function ODCITableDescribe( rtype out anytype, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number )
return number
is
atyp anytype;
cur integer;
numcols number;
desc_tab dbms_sql.desc_tab2;
rc sys_refcursor;
t_c2 varchar2(32767);
t_fmt varchar2(1000);
begin
cur := dbms_sql.open_cursor;
dbms_sql.parse( cur, p_stmt, dbms_sql.native );
dbms_sql.describe_columns2( cur, numcols, desc_tab );
dbms_sql.close_cursor( cur );
--
anytype.begincreate( dbms_types.typecode_object, atyp );
for i in 1 .. numcols - 2
loop
atyp.addattr( desc_tab( i ).col_name
, case desc_tab( i ).col_type
when 1 then dbms_types.typecode_varchar2
when 2 then dbms_types.typecode_number
when 9 then dbms_types.typecode_varchar2
when 11 then dbms_types.typecode_varchar2 -- show rowid as varchar2
when 12 then dbms_types.typecode_date
when 208 then dbms_types.typecode_varchar2 -- show urowid as varchar2
when 96 then dbms_types.typecode_char
when 180 then dbms_types.typecode_timestamp
when 181 then dbms_types.typecode_timestamp_tz
when 231 then dbms_types.typecode_timestamp_ltz
when 182 then dbms_types.typecode_interval_ym
when 183 then dbms_types.typecode_interval_ds
end
, desc_tab( i ).col_precision
, desc_tab( i ).col_scale
, case desc_tab( i ).col_type
when 11 then 18 -- for rowid col_max_len = 16, and 18 characters are shown
else desc_tab( i ).col_max_len
end
, desc_tab( i ).col_charsetid
, desc_tab( i ).col_charsetform
);
end loop;
if instr( p_fmt, '@p@' ) > 0
then
t_fmt := p_fmt;
else
t_fmt := '@p@';
end if;
open rc for replace( 'select distinct ' || t_fmt || '
from( ' || p_stmt || ' )
order by ' || t_fmt
, '@p@'
, desc_tab( numcols - 1 ).col_name
);
loop
fetch rc into t_c2;
exit when rc%notfound;
atyp.addattr( t_c2
, case desc_tab( numcols ).col_type
when 1 then dbms_types.typecode_varchar2
when 2 then dbms_types.typecode_number
when 9 then dbms_types.typecode_varchar2
when 11 then dbms_types.typecode_varchar2 -- show rowid as varchar2
when 12 then dbms_types.typecode_date
when 208 then dbms_types.typecode_urowid
when 96 then dbms_types.typecode_char
when 180 then dbms_types.typecode_timestamp
when 181 then dbms_types.typecode_timestamp_tz
when 231 then dbms_types.typecode_timestamp_ltz
when 182 then dbms_types.typecode_interval_ym
when 183 then dbms_types.typecode_interval_ds
end
, desc_tab( numcols ).col_precision
, desc_tab( numcols ).col_scale
, case desc_tab( numcols ).col_type
when 11 then 18 -- for rowid col_max_len = 16, and 18 characters are shown
else desc_tab( numcols ).col_max_len
end
, desc_tab( numcols ).col_charsetid
, desc_tab( numcols ).col_charsetform
);
end loop;
close rc;
atyp.endcreate;
anytype.begincreate( dbms_types.typecode_table, rtype );
rtype.SetInfo( null, null, null, null, null, atyp, dbms_types.typecode_object, 0 );
rtype.endcreate();
return odciconst.success;
exception
when others then
return odciconst.error;
end;
--
static function ODCITablePrepare( sctx out PivotImpl, ti in sys.ODCITabFuncInfo, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number )
return number
is
prec pls_integer;
scale pls_integer;
len pls_integer;
csid pls_integer;
csfrm pls_integer;
elem_typ anytype;
aname varchar2(30);
tc pls_integer;
begin
tc := ti.RetType.GetAttrElemInfo( 1, prec, scale, len, csid, csfrm, elem_typ, aname );
--
if instr( p_fmt, '@p@' ) > 0
then
sctx := PivotImpl( elem_typ, p_stmt, p_fmt, null );
else
sctx := PivotImpl( elem_typ, p_stmt, '@p@', null );
end if;
return odciconst.success;
end;
--
static function ODCITableStart( sctx in out PivotImpl, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number )
return number
is
cur integer;
numcols number;
desc_tab dbms_sql.desc_tab2;
t_stmt varchar2(32767);
type_code pls_integer;
prec pls_integer;
scale pls_integer;
len pls_integer;
csid pls_integer;
csfrm pls_integer;
schema_name varchar2(30);
type_name varchar2(30);
version varchar2(30);
attr_count pls_integer;
attr_type anytype;
attr_name varchar2(100);
dummy2 integer;
begin
cur := dbms_sql.open_cursor;
dbms_sql.parse( cur, p_stmt, dbms_sql.native );
dbms_sql.describe_columns2( cur, numcols, desc_tab );
dbms_sql.close_cursor( cur );
--
for i in 1 .. numcols - 2
loop
t_stmt := t_stmt || ', "' || desc_tab( i ).col_name || '"';
end loop;
--
type_code := sctx.ret_type.getinfo( prec
, scale
, len
, csid
, csfrm
, schema_name
, type_name
, version
, attr_count
);
for i in numcols - 1 .. attr_count
loop
type_code := sctx.ret_type.getattreleminfo( i
, prec
, scale
, len
, csid
, csfrm
, attr_type
, attr_name
);
t_stmt := t_stmt || replace( ', max( decode( ' || sctx.fmt || ', ''' || attr_name || ''', ' || desc_tab( numcols ).col_name || ' ) )'
, '@p@'
, desc_tab( numcols - 1 ).col_name
);
end loop;
t_stmt := 'select ' || substr( t_stmt, 2 ) || ' from ( ' || sctx.stmt || ' )';
for i in 1 .. numcols - 2
loop
if i = 1
then
t_stmt := t_stmt || ' group by "' || desc_tab( i ).col_name || '"';
else
t_stmt := t_stmt || ', "' || desc_tab( i ).col_name || '"';
end if;
end loop;
--
--dbms_output.put_line( t_stmt );
sctx.cur := dbms_sql.open_cursor;
dbms_sql.parse( sctx.cur, t_stmt, dbms_sql.native );
for i in 1 .. attr_count
loop
type_code := sctx.ret_type.getattreleminfo( i
, prec
, scale
, len
, csid
, csfrm
, attr_type
, attr_name
);
case type_code
when dbms_types.typecode_char then dbms_sql.define_column( sctx.cur, i, 'x', 32767 );
when dbms_types.typecode_varchar2 then dbms_sql.define_column( sctx.cur, i, 'x', 32767 );
when dbms_types.typecode_number then dbms_sql.define_column( sctx.cur, i, cast( null as number ) );
when dbms_types.typecode_date then dbms_sql.define_column( sctx.cur, i, cast( null as date ) );
when dbms_types.typecode_urowid then dbms_sql.define_column( sctx.cur, i, cast( null as urowid ) );
when dbms_types.typecode_timestamp then dbms_sql.define_column( sctx.cur, i, cast( null as timestamp ) );
when dbms_types.typecode_timestamp_tz then dbms_sql.define_column( sctx.cur, i, cast( null as timestamp with time zone ) );
when dbms_types.typecode_timestamp_ltz then dbms_sql.define_column( sctx.cur, i, cast( null as timestamp with local time zone ) );
when dbms_types.typecode_interval_ym then dbms_sql.define_column( sctx.cur, i, cast( null as interval year to month ) );
when dbms_types.typecode_interval_ds then dbms_sql.define_column( sctx.cur, i, cast( null as interval day to second ) );
end case;
end loop;
dummy2 := dbms_sql.execute( sctx.cur );
return odciconst.success;
end;
--
member function ODCITableFetch( self in out PivotImpl, nrows in number, outset out anydataset )
return number
is
c1_col_type pls_integer;
type_code pls_integer;
prec pls_integer;
scale pls_integer;
len pls_integer;
csid pls_integer;
csfrm pls_integer;
schema_name varchar2(30);
type_name varchar2(30);
version varchar2(30);
attr_count pls_integer;
attr_type anytype;
attr_name varchar2(100);
v1 varchar2(32767);
n1 number;
d1 date;
ur1 urowid;
ids1 interval day to second;
iym1 interval year to month;
ts1 timestamp;
tstz1 timestamp with time zone;
tsltz1 timestamp with local time zone;
begin
outset := null;
if nrows < 1
then
-- is this possible???
return odciconst.success;
end if;
--
--dbms_output.put_line( 'fetch' );
if dbms_sql.fetch_rows( self.cur ) = 0
then
return odciconst.success;
end if;
--
--dbms_output.put_line( 'done' );
type_code := self.ret_type.getinfo( prec
, scale
, len
, csid
, csfrm
, schema_name
, type_name
, version
, attr_count
);
anydataset.begincreate( dbms_types.typecode_object, self.ret_type, outset );
outset.addinstance;
outset.piecewise();
for i in 1 .. attr_count
loop
type_code := self.ret_type.getattreleminfo( i
, prec
, scale
, len
, csid
, csfrm
, attr_type
, attr_name
);
--dbms_output.put_line( attr_name );
case type_code
when dbms_types.typecode_char then
dbms_sql.column_value( self.cur, i, v1 );
outset.setchar( v1 );
when dbms_types.typecode_varchar2 then
dbms_sql.column_value( self.cur, i, v1 );
outset.setvarchar2( v1 );
when dbms_types.typecode_number then
dbms_sql.column_value( self.cur, i, n1 );
outset.setnumber( n1 );
when dbms_types.typecode_date then
dbms_sql.column_value( self.cur, i, d1 );
outset.setdate( d1 );
when dbms_types.typecode_urowid then
dbms_sql.column_value( self.cur, i, ur1 );
outset.seturowid( ur1 );
when dbms_types.typecode_interval_ds then
dbms_sql.column_value( self.cur, i, ids1 );
outset.setintervalds( ids1 );
when dbms_types.typecode_interval_ym then
dbms_sql.column_value( self.cur, i, iym1 );
outset.setintervalym( iym1 );
when dbms_types.typecode_timestamp then
dbms_sql.column_value( self.cur, i, ts1 );
outset.settimestamp( ts1 );
when dbms_types.typecode_timestamp_tz then
dbms_sql.column_value( self.cur, i, tstz1 );
outset.settimestamptz( tstz1 );
when dbms_types.typecode_timestamp_ltz then
dbms_sql.column_value( self.cur, i, tsltz1 );
outset.settimestampltz( tsltz1 );
end case;
end loop;
outset.endcreate;
return odciconst.success;
end;
--
member function ODCITableClose( self in PivotImpl )
return number
is
c integer;
begin
c := self.cur;
dbms_sql.close_cursor( c );
return odciconst.success;
end;
end;
/
-- 在外面包装一层PLSQL函数:
create or replace
function pivot( p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 )
return anydataset pipelined using PivotImpl;
/
/**************
eg.
select *
from table( pivot('select deptno
, job
, avg(sal) sal_avg
from scott.emp
group
by deptno
, job
')
);
***************/转换前数据
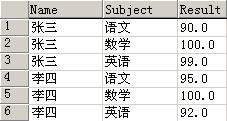
调用pivot()函数后的数据展示结果
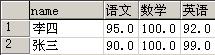
这种方法的好处是转换列自由,不用特殊指定。
方法三:
这种方法适用于数据量小并且列字段固定的情况,就是使用decode和sum实现转换,这种方法网上很多,也很简单,就不详细介绍。















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









