






1.背景介绍
我因为书店的藏书都放在供应商的库上,所以就想把在别人系统上我这边的藏书书单拿出来上线到我的系统中,自己进行维护,所以就直接上手去爬取数据,同时存储到我本地的MySQL库
2.环境准备
-
首先安装python,不再详述,直接百度在搜索框中输入“python 安装教程”按步骤进行即可
-
安装scrapy 、pymysql包,直接在命令行中输入
pip install scrapy pip install pymysql -
新建一个项目
scrapy startproject myspider生成如下图所示目录树
-
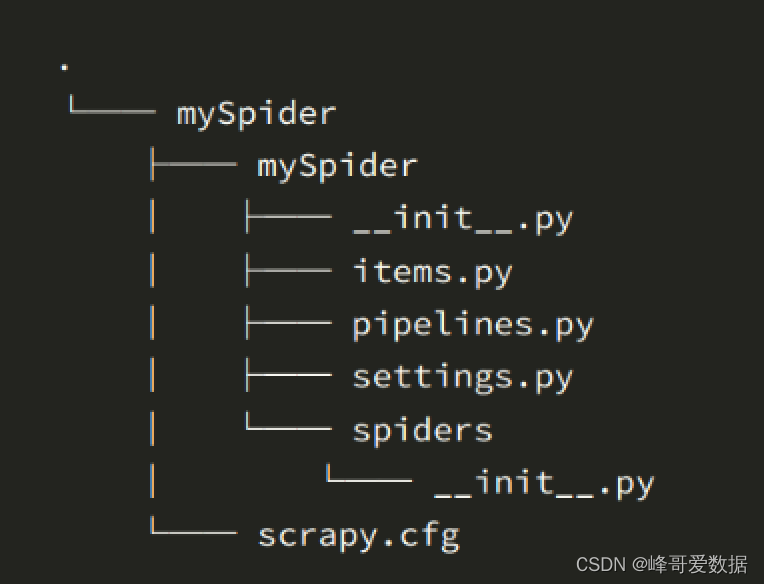
-
创建一个爬虫文件,可以用如下代码快速生成文件和初始代码
scrapy genspider itcast "bookspider.cn" -
在爬虫文件中发送请求并获取响应,首先需要获取到登录的cookie和headers,操作方式如下
打开网页,进入到“开发者工具”界面,如下操
-

-
进入Convert curl commands to code 进行对应转换
-
生成如下结果,写到bookspider.py文件中
-
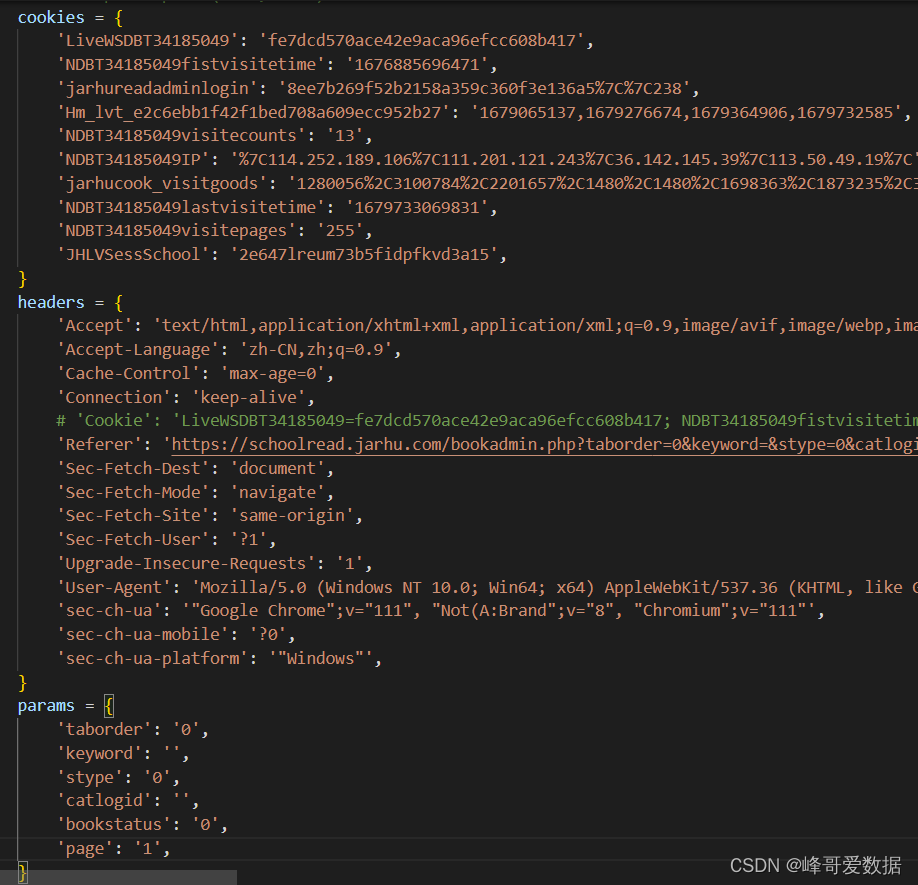
3.获取item内容
-
首先在items.py中定义好想要的字段,所有字段定义方式一致
class BookItem(scrapy.Item): btitle = scrapy.Field() bimg = scrapy.Field() bsmma = scrapy.Field() bprice = scrapy.Field() -
在爬取页面请求文件bookspider.py中的params中处理抓取到的页面
其中parse是scrapy处理请求固定的函数
`def parse(self,response): selector1 = Selector(response)2.1. path解析页面
tr = selector1.css(".rept_detail tr:nth-of-type(n+2)") items = [] for xi in tr: b = xi.css('td b::text').extract_first() img = xi.css('td img::attr(src)').extract_first() content = xi.css('td::text').extract()2.2 处理items中的字段
item = BookItem() item['btitle'] = b item['bimg'] = img item['bsmma'] = content[1].split(':')[1] item['bprice'] = content[2].split(':')[1] item['bcbs'] = content[3].split(':')[1] item['bactor'] = content[4].split(':')[1] item['bgcbh'] = content[5].split(':')[1] item['bgcfl'] = content[6].split(':')[1] item['bztfl'] = content[7].split(':')[1] item['bcreatedate'] = content[8].split(':')[1] item['bgczt'] = content[9].split(':')[1]2.3 循环处理 item内容
yield item2.4 循环请求所有的页,直到结束
if self.start <=91: self.start +=1 else: break yield scrapy.Request('https://XXXX.com/bookadmin.php',callback=self.params, cookies=self.cookies,params=self.params, headers=self.headers) items.append(item)
4.管道传输
直接在pipelines.py中连接数据库,编写SQL导入到数据库即可
def process_item(self,item,spider):
print(self.connect)
cursor = self.connect.cursor()
insert_sql = '''
insert into book_manage(btitle ,bimg ,bsmma,bprice,bpublisher,bactor,bgcbh,bgcfl,bztfl,bcreatedate ,bgczt ,bupdatetime) values("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")
'''
cursor.execute(insert_sql%(item['btitle'] ,item['bimg'] ,item['bsmma'] ,item['bprice'] ,item['bcbs'] ,item['bactor'] ,item['bgcbh'] ,item['bgcfl'] ,item['bztfl'],item['bcreatedate'],item['bgczt'],item['bupdatetime']))`
cursor.close()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









