





前言
计算数据点之间的距离是从事机器学习经常遇到的任务,经常使用的距离度量有:欧式距离、余弦距离、城市距离…等等。一个常见的问题是一旦问题的维数非常大时,传统度量函数的计算变得非常耗时与复杂。度量学习的目标在于以机器学习的方式构造出与任务数据相关的距离度量,从而摆脱来自任务的限制以及达到降维的结果。随着近年来深度学习在各个领域的研究与应用,深度度量学习也成为可能。实用度量学习(Practical Metric Learning)是 OpenMetricLearning 开发者 Aleksei Shabanov 所写的一篇简介度量学习以及 OpenMetricLearning 的文章,旨在推广 OML 在深度度量学习的应用。为了面向国内的读者,我应 Aleksei 的要求把文章翻译成中文。个人中文水平一般,译文若有不通顺的地方,请多包涵。
这篇帖子是关于最近发布的开源项目:OpenMetricLearning (OML),这个项目的目标之一是降低度量学习(metric learning)的进入门槛。我们将会在文中简要地介绍度量理论以及代码范例,并透过一个简单的范例,演示 OML 与当前最先进的方法不相上下的表现。由于 OML 是个新项目,因此您在 GitHub 上的每一个星星点赞对我们来说都是鼓励。

关于度量学习
度量学习管道 (ML) 的目标是构建一个度量函数,用以估计 2 个对象之间的距离或相似性,我们可以使用这样的函数执行聚类、搜索、异常检测等等工作。 深度神经网络的使用为我们开启了深度度量学习的可能,其中有两种主要方法:
- 双生神经网络(Siamese Neural Network):这种类型的神经网络透过两个输入端分别读取不同的对象,按照任务设置,判别二者是否相同或者估计其相似度。
- 表象学习(Representation Learning):神经网络读取对象,在某个高维空间中取回一个表示该对象的向量,然后计算向量之间的经典距离,例如余弦距离。
现在我们试想一下,对于 n 个对象计算他们之间所有成对距离需要多少时间。第一种方法需要 前向传递步骤,第二种方法需要
步前向传递和
的距离计算。由于距离计算比模型推断结果快得多,第二种方法在实践中更为常见。
这是在 Fashion MINST 数据集上所训练的模型的向量空间:

度量学习与分类
由于这两项任务看起来颇为相似,这使得与它们相关术语让人产生困惑。从一方面来看,您可以训练一个分类器,然后使用其倒数第二层导出的特征作为向量表示,并进行距离估计。另外一方面,您可以训练使用非分类损失函数(non-classification loss function)的模型(如三元组损失 triplet loss,下面有更多详细信息),通过从 k 个最近邻 (kNN) 中最频繁出现的标签,将从模型得到的特征进行分类。
尽管上述两个方法有相似性,他们之间依然有所差异:
- 分类模型需要在训练集和测试集中具有相同的类,但度量学习不要求这个条件。
- 度量学习可以在没有类级别标签的情况下使用。例如,它能够处理被人工标记为正面和负面的成对对象。至于正面、负面的意义取决于任务定义。
是否有度量学习的基准?
是的,就像分类任务一样,研究人员在一组常用的数据集上比较他们的结果,例如这个排行榜就是基于图像数据集。
如何训练和验证模型?
让我们考虑上面排行榜中的 DeepFashion 数据集。它由 17 类衣服(夹克、牛仔裤、短裤等)和 8000 个类(特定物品的 id)组成。类的中位数为 5 张图像。
这些类被分成没有交集的训练集和验证集。请注意,拆分是在类级别上执行的。验证的想法是模拟搜索过程,因此它分为查询组(搜索请求)和图库组(搜索索引)。 请注意,这里是在图像级别上进行区分。例如,一件夹克 id 001 有 7 张图片,其中 3 张在查询组,其余 4 张在图库组。模型训练的目标是:给定 3 张查询图像,使其返回 4 个图库图像作为最相关结果。
接下来让我们看看我们如何用经典的三元组损失函数来训练模型。如果你很熟悉这个损失函数,请跳过下面的部分。
针对不熟悉的人的三元组损失函数简介
其中
- 由锚点(anchor)、正对象(positive)(与锚点具有相同的 id)、负对象(negative)(与锚点的 id 不同)所组成的三元组。根据任务的不同,我们可能需要征用图片的视觉相似性或引入其他逻辑而不是要求 id 相等;
- 我们想要最小化的锚点和正对象之间的距离;
- 我们想要最大化的锚点和负对象之间的距离;
- 边距参数。
三元组损失函数除了上述的经典定义之外,也有其他有时后能更好地收敛的定义。例如,这里是一个“软”版本的三元组损失函数:

训练管道
- Sampler - 在至少有 2 个类别,每个类别至少有 2 个图像的条件下创建一个批次(换句话说一个批次最少有 4 张图像,否则我们无法获得三元组)。通常,批次是类平衡的。
- The batch(批次) - 模型读取批次并将之转变成向量表象。
- Miner - 负责从这批向量中收集三元组。它可以收集所有可能的三元组或只收集最困难的三元组(当负距离最小而正距离最大时)。 还有许多其他可用的技术,例如,利用跨批次内存来扩大有效批次大小。
- Optimizer - 为上述三元组损失函数计算梯度。
刚刚所讲述的训练管道可以依据实际情况调整,并非是一成不变的。比方说:
- 如果使用分类损失(如 Log loss 或 ArcFace),则不需要 Miner。
- 如果没有类别标签,但数据在三元组或成对级别上进行了标记,则可以将其直接传递给损失函数,而无需使用 Miner。
- Miner 分别收集四元组与收集成对级别,然后个别计算四元组损失函数以及对比损失函数(contrastive loss)。
验证管道
- 对整个验证集进行推理并累积获得的嵌入。
- 计算所有可能的查询组(
)与图库组(
)对之间的距离,得到一个大小为
的矩阵。然后我们按行对其进行排序,将图库组中距离最小的项目放在搜索结果的顶部。
- 计算度量,可从信息检索的研究领域当中选择度量:
:如果前
个结果至少有一个正确答案,则
:是前
与上一个类似,但考虑了正确结果的位置。
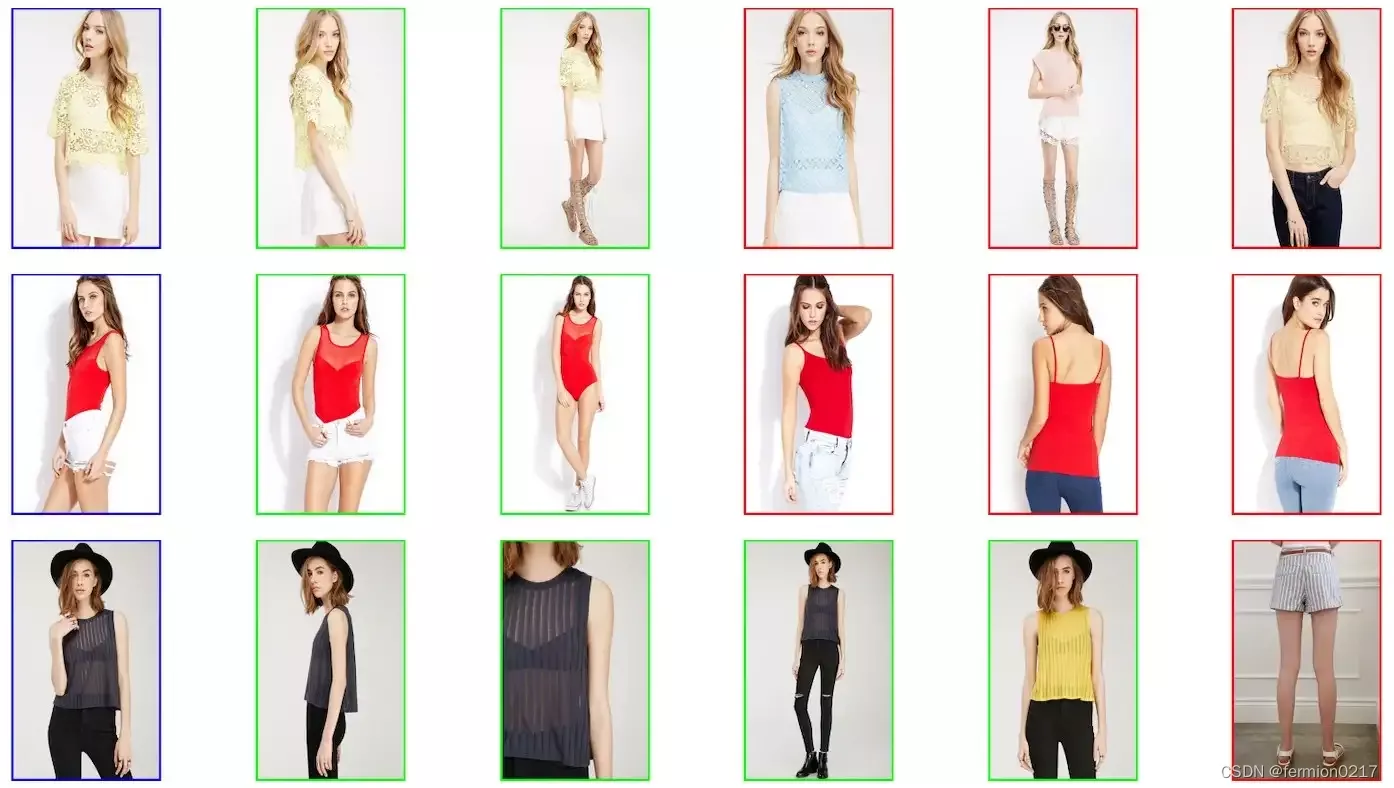
让我们看一个例子:3 张查询图片(蓝色框表示),我们按照距离增加的顺序依次返回 5 张图像。 其中一些具有相同的项目 id(以绿框显示为正确答案),但其中一些没有(以红框显示为错误)。对于所有这些结果, 等于 1。
的计算有点复杂,因为我们需要知道与给定查询相关的所有可能正确答案的数量,以便在无法返回
个正确结果时不降低度量。例如,假设第一个查询在图库组中有 5 个具有相同 id 的图像,第二个有 3 个,第 3 个有 4 个。因此,度量值如下:
关于 OpenMetricLearning(OML)
OML 是一个基于 PyTorch 的新表象学习库。我们在下面列出了简单的代码示例以帮助理解。在实践中你或许对与 PyTorch Lightning 或 Config API 集成的管道更感兴趣(下面有更多详细信息),但其实它们遵循相同的逻辑。
训练代码
import torch
from tqdm import tqdm
from oml.datasets.base import DatasetWithLabels
from oml.losses.triplet import TripletLossWithMiner
from oml.miners.inbatch_all_tri import AllTripletsMiner
from oml.models.vit.vit import ViTExtractor
from oml.samplers.balance import BalanceSampler
from oml.utils.download_mock_dataset import download_mock_dataset
# download dummy dataset
dataset_root = "mock_dataset/"
df_train, _ = download_mock_dataset(dataset_root)
# create a model based on checkpoint pretrained is a self-supervised way
model = ViTExtractor("vits16_dino", arch="vits16", normalise_features=False).train()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-6)
train_dataset = DatasetWithLabels(df_train, dataset_root=dataset_root)
# create criterion consists of loss function and miner
criterion = TripletLossWithMiner(margin=0.1, miner=AllTripletsMiner())
# create sample that puts 2 samples for 2 classes into the batch
sampler = BalanceSampler(train_dataset.get_labels(), n_labels=2, n_instances=2)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_sampler=sampler)
# rest of the code doesn't differ from a normal PyTroch pipeline
for batch in tqdm(train_loader):
embeddings = model(batch["input_tensors"])
loss = criterion(embeddings, batch["labels"])
loss.backward()
optimizer.step()
optimizer.zero_grad()验证代码
import torch
from tqdm import tqdm
from oml.datasets.base import DatasetQueryGallery
from oml.metrics.embeddings import EmbeddingMetrics
from oml.models.vit.vit import ViTExtractor
from oml.utils.download_mock_dataset import download_mock_dataset
# download dummy dataset
dataset_root = "mock_dataset/"
_, df_val = download_mock_dataset(dataset_root)
# create a model based on checkpoint pretrained is a self-supervised waymodel = ViTExtractor("vits16_dino", arch="vits16", normalise_features=False).eval()
val_dataset = DatasetQueryGallery(df_val, dataset_root=dataset_root)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=4)
# create metrics calculator that handles vectors accumulation and metrics compute
calculator = EmbeddingMetrics()
calculator.setup(num_samples=len(val_dataset))
with torch.no_grad():
for batch in tqdm(val_loader):
batch["embeddings"] = model(batch["input_tensors"])
calculator.update_data(batch) # accumulating vectors
# compute metrics: cmc@k, precision@k, map@k
metrics = calculator.compute_metrics()OpenMetricLearning 与 PyTorch Metric Learning
基于一切都是相对的这个概念,为了让你更好地认识 OML,我们把它与 PyTorch Metric Learning(PML)进行比较。PML 是广受欢迎的度量学习库,它包含丰富的损失函数、Miner、距离和 reducer 集合。一开始我们尝试使用 PML 来满足我们的需求,但最终我们开发了 OML,因它更面向管道与配方,这也是为什么我们透过范例演示 OML 的原因。以下是 OML 与 PML 几个不同之处:
- OML 支持 Config API,它允许通过以所需格式准备配置(config)和数据来训练模型(就像将数据转换为 COCO 格式以从 mmdetection 训练检测器)。
- OML 专注于端到端管道和实际应用,它在贴近现实应用且受欢迎的基准上提供了基于配置的示例(例如具有数千个 id 的产品照片)。 我们在这些数据集、训练和发布的模型及其配置上发掘了一些很好的超参数组合。因此 OML 比 PML 更面向配方(recipes)。关于这点,PML 作者也曾经表示过 PML 更侧重于工具面向(如损失函数……等等)而不是管道与配方。此外,PML 中的示例主要用于 CIFAR 和 MNIST 数据集。
- OML 有许多预训练模型,可以像在 torchvision 中一样轻松地从代码中调用这些模型(例如 resnet50(pretrained=True) 时)。
- OML 与 PyTorch Lightning 集成,因此,我们可以使用其 Trainer 的强大功能。这在我们使用 DDP(分散数据并行,distributed data parallel)时特别有用,您可以比较我们的 DDP 示例和 PML 示例。顺便说一句,PML 也有 Trainers,但不在示例中,而是使用自定义的训练/测试函数。
我们相信,OML 的 Config API、简洁示例和众多预训练模型,将会大大降低进入度量学习领域的门槛。
使用 OpenMetricLearning 训练的模型的准确度如何?
我可以说它的准确度与目前最先进的方法相当。让我们考虑一下 Hyp-ViT,这是用对比损失函数训练的 ViT 架构,但其嵌入被投影到某个双曲空间中。正如其作者所说,双曲空间能够更好的描述现实世界数据的嵌套结构。因此,这篇论文需要一些繁重的数学以便进行双曲空间中常用的运算。
我们用三元组损失训练了相同的架构并准备其余参数:训练和测试转换、图像大小和 optimizer。诀窍在于我们对 Miner 和 Sampler 基于经验的调整:
- 对 Sampler 的批次限制其中类别 C 的数量。 例如,当只有一个类别 C = 1 时,它只将夹克放入一批次,而将牛仔裤放入另一批次中。这种方法自动地更不容易产生负对:因为对于模型来说,了解为什么两件夹克不同比理解一件夹克和一件 T 恤的相同更有意义。
- 透过只保留最难的三元组(具有最大的正距离和最小的负距离),Miner 使任务变得更加困难。

这个比较结果显示 OML 与最先进的方法二者表现相当,而且 OML 使用简单的启发式算法避免了繁重的数学运算。
小结
如果您想进一步探讨我们刚刚提过的机器学习问题类型,欢迎您为 OpenMetricLearning 做出贡献。您可以尝试目前现有的任务(我们既有科学任务也有工程任务),或者通过提交新问题提出您自己的想法。对于您在 GitHub 上的星星点赞还有鼓掌,我们一并致谢!















 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









