







CSAPP Note chap12 PartB
CSAPP 读书笔记系列chap12
chap 12 并发编程
这一次说的是多线程并发编程,是也一个比较广泛的话题.
对于并发编程为什么会引起的一些问题,可以看下SICP,之前的简单博客笔记
这一章要讲的内容很多,打算分开两部分Part A和part B 来写
PartA讲服务器的三种并发编程
- 基于进程
- 基于事件
- 基于线程
PartB讲并发编程的一些基本概念
- 共享变量
- 信号量,进度图和互斥
- 生产者-消费者问题 和读者写者问题
- 线程安全,可重入函数
- 竞争和死锁
PartB
这是第二篇,为Part B
共享变量和线程内存模型
线程的内存模型
线程的内存模型,因为概念上的模型和实际的模型有一些差异
在概念上的模型中:
- 多个线程在一个单独进程的上下文中运行
- 每个线程有单独的线程上下文(线程 ID,栈,栈指针,PC,条件码,GP 寄存器)
- 所有的线程共享剩下的进程上下文
- Code, data, heap, and shared library segments of the process virtual address space
- Open files and installed handlers
在实际的模型中,线程的单独上下文数据却不是严格独立的:
- 寄存器的值虽然是隔离且被保护的,但是在栈中的值并不是这样的(其他线程也可以访问)
共享变量Shared Variables
当变量映射到内存时,多线程有几种方式:
全局变量:在函数外声明的变量
- 虚拟内存中有全局唯一的一份实例,任何线程都可以引用
本地自动(局部)变量:在函数内声明,且没有用 static 关键字
- 每个线程的栈中都保存着对应自己线程的局部变量的实例
局部静态变量:在函数内用 static 关键字声明的变量
- 虚拟内存中有全局唯一的一份实例
Share Variable is not as simple as “global variables are shared” and
“stack variables are private”,A variable x is shared if and only if multiple threads reference some instance of x.
也就是说当一个变量为共享表示,当且仅当多个线程引用这个变量的某个实例,也就是被一个以上的线程引用
例子如下:
char **ptr; // 全局变量
int main()
{
long i; // 主线程的本地自动变量
pthread_t tid;
char *msgs[2] = {
"Good Day!",
"Bad Day!"
}; // 主线程的本地自动变量,被两个对等线程间接引用
ptr = msgs; // 一个被主线程和对等线程间接引用的全局变量
for (i = 0; i < 2; i++)
Pthread_create(&tid, NULL, thread, (void *)i);
Pthread_exit(NULL);
}
void *thread(void *vargp)
{
long myid = (long)vargp; // 一个本地自动变量,只有一个实例,分别于两个对等线程的栈中
static int cnt = 0; // 一个静态变量,被两个线程引用,分别读和写
// 这里每个线程都可以访问 ptr 这个全局变量
printf("[%ld]: %s (cnt=%d)\n", myid, ptr[myid], ++cnt);
return NULL;
}在这个例子中,共享变量有 ptr, cnt 和 msgs;非共享变量有 i 和 myid。
信号量,进度图和互斥
幻读等麻烦
共享变量的引入,会带来一些麻烦,cpu时间片争夺资源造成的不可知危害
SICP中chap3.4也有说到的幻读等问题
书上也给了一个幻读的例子,也就是一个计数器如下:
// 全局共享变量
volatile long cnt = 0; // 计数器
// 线程处理函数
void *thread(void *vargp) {
long i, niters = *((long *)vargp);
for (i = 0; i < niters; i++)
cnt++;
return NULL;
}
int main(int argc, char **argv)
{
long niters;
pthread_t tid1, tid2;
niter2 = atoi(argv[1]);
Pthread_create(&tid1, NULL, thread, &niters);
Pthread_create(&tid2, NULL, thread, &niters);
Pthread_join(tid1, NULL);
Pthread_join(tid2, NULL);
// 检查结果
if (cnt != (2 * niters))
printf("Wrong! cnt=%ld\n", cnt);
else
printf("Correct! cnt=%ld\n", cnt);
exit(0);
}运行的结果每次不一样
➜ conc ./badcnt 10000
OK cnt=20000
➜ conc ./badcnt 10000
BOOM! cnt=10458把操作 cnt 的部分抽出来单独看一看:
线程中循环部分的代码为:
for (i = 0; i < niters; i++)
cnt++;
对应的汇编代码为
# 以下四句为 Head 部分,记为 H
movq (%rdi), %rcx
testq %rcx, %rcx
jle .L2
movl $0, %eax
.L3:
movq cnt(%rip), %rdx # 载入 cnt,记为 L
addq $1, %rdx # 更新 cnt,记为 U
movq %rdx, cnt(%rip) # 保存 cnt,记为 S
# 以下为 Tail 部分,记为 T
addq $1, %rax
cmpq %rcx, %rax
jne .L3
.L2:这里有一点需要注意,cnt 使用了 volatile 关键字声明,意思是不要在寄存器中保存值,无论是读取还是写入,都要对内存操作(write-through )。
这里把具体的步骤分成 5 步:HLUST,尤其要注意 LUS 这三个操作,这三个操作必须在一次执行中完成,一旦次序打乱,就会出现问题,不同线程拿到的值就不一定是最新的。
也就是说该函数的正确执行和指令的执行顺序有关
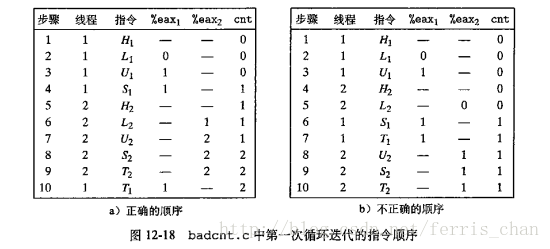
进度图
进度图将 n个并发线程的执行模型化为一条n维笛卡尔空间中的轨迹线,每条轴k对应k的进度.
例如下图,对于 H1,L1,U1,H2,L2,S1,T1,U2,S2,T2的轨迹线的进度图
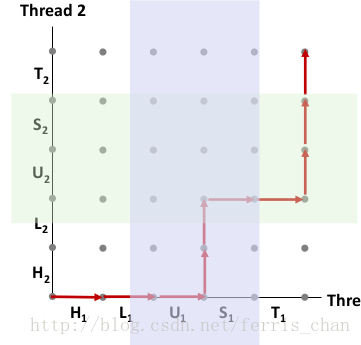
对于线程i,操作共享变量cnt内容的指令(,Li,Ui,Si)构成了一个临界区,每个临界区不应该和其他线程的临界区交替执行.
也就是说,需要对共享变量进行互斥的访问
当线程绕开不安全区是,叫做安全轨迹线;反之,为不安全轨迹线.
信号量
Dijkstra 提出用信号量来限制程序的执行顺序,从而解决经典的同步不同问题.
信号量s是具有非负整数的全局变量, 只能具备两种操作动作,称为 V(Verhogen,增加操作;又称signal())与 P(Proberen,测试减一操作;又为wait())。
V 操作会增加信号量 S 的数值,P 操作会减少。运作方式:
- 1.初始化信号量S,给与它一个非负数的整数值。
2.运行 P,信号量 S 的值将被减少。企图进入临界区块的进程,需要先运行 P。当信号量 S 减为负值时,进程会被挡住,不能继续;当信号量S不为负值时,进程可以获准进入临界区块。
3.运行 V,信号量 S 的值会被增加。结束离开临界区块的进程,将会运行 V。当信号量 S 不为负值时,先前被挡住的其他进程,将可获准进入临界区块。
在C语言中,POSIX 定义了许多操作信号量的函数.
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value); // 初始化信号量
int sem_wait(sem_t *sem); // P(s)
int sem_post(sem_t *sem); // V(s)而对于之前的程序计数器,其修改信号量操作为:
// 先定义信号量
volatile long cnt = 0;
sem_t mutex;
Sem_init(&mutex, 0, 1);
// 在线程中用 P 和 V 包围关键操作
for (i = 0; i < niters; i++)
{
P(&mutex);
cnt++;
V(&mutex);
}一般而言,需要把s初始化为1,(因为其值总为1或0,所以称为二元信号量).
以提供互斥目的的二元信号量称为互斥锁(mutex),对其进行P操作为加锁,执行V操作为解锁
生产者-消费者问题
信号量可以调度对共享资源的访问,一个线程可以使用信号量通知另外一个线程,程序中某些状态.
利用信号量实现生产者-消费者问题,生产者-消费者问题如下:
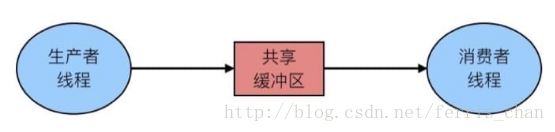
具体的同步模型为:
- 生产者等待空位slot,产生项目item 存储到有限的缓冲区 buffer,并通知消费者
- 消费者等待 item,从缓冲区 buffer 中移除并消费 item,并通知生产者
更加详细的生产者-消费者问题,其和队列关系等可以看这篇http://blog.csdn.net/kaiwii/article/details/6758942
可以实现一个有 n 个元素 buffer,为此,我们需要一个 mutex 和两个用来计数的 semaphore:
- mutex: 用来保证对 buffer 的互斥访问
- slots: 统计 buffer 中可用的 slot 数目
- items: 统计 buffer 中可用的 item 数目
可以定义一个包:
// 头文件 sbuf.h
// 包括几个基本操作
#include "csapp.h"
typedef struct {
int *buf; // Buffer array
int n; // Maximum number of slots
int front; // buf[(front+1)%n] is first item
int rear; // buf[rear%n] is the last item
sem_t mutex; // Protects accesses to buf
sem_t slots; // Counts available slots
sem_t items; // Counts available items
} sbuf_t;
void sbuf_init(sbuf_t *sp, int n);
void sbuf_deinit(sbuf_t *sp);
void sbuf_insert(sbuf_t *sp, int item);
int sbuf_remove(sbuf_t *sp);具体的实现如下
// sbuf.c
// Create an empty, bounded, shared FIFO buffer with n slots
void sbuf_init(sbuf_t *sp, int n) {
sp->buf = Calloc(n, sizeof(int));
sp->n = n; // Buffer holds max of n items
sp->front = sp->rear = 0; // Empty buffer iff front == rear
Sem_init(&sp->mutex, 0, 1); // Binary semaphore for locking
Sem_init(&sp->slots, 0, n); // Initially, buf has n empty slots
Sem_init(&sp->items, 0, 0); // Initially, buf has 0 items
}
// Clean up buffer sp
void sbuf_deinit(sbuf_t *sp){
Free(sp->buf);
}
// Insert item onto the rear of shared buffer sp
void sbuf_insert(sbuf_t *sp, int item) {
P(&sp->slots); // Wait for available slot
P(&sp->mutext); // Lock the buffer
sp->buf[(++sp->rear)%(sp->n)] = item; // Insert the item
V(&sp->mutex); // Unlock the buffer
V(&sp->items); // Announce available item
}
// Remove and return the first tiem from the buffer sp
int sbuf_remove(sbuf_f *sp) {
int item;
P(&sp->items); // Wait for available item
P(&sp->mutex); // Lock the buffer
item = sp->buf[(++sp->front)%(sp->n)]; // Remove the item
V(&sp->mutex); // Unlock the buffer
V(&sp->slots); // Announce available slot
return item;
}生产者消费者模式主要用于:
- 多媒体处理
- 生产者生成 MPEG 视频帧,消费者进行渲染
- 事件驱动的图形用户界面
- 生产者检测到鼠标点击、移动和键盘输入,并把对应的事件插入到 buffer 中
- 消费者从 buffer 中获取事件,并绘制到到屏幕上
读者-写者问题
读者-写者问题是互斥问题的通用描述,具体为:
- 读者线程只读取对象
- 写者线程修改对象
- 写者对于对象的访问是互斥的,也就是必须拥有对象独占的访问
- 多个读者可以同时读取对象
根据不同的读写策略,也就是读者写者的优先级,有两类读者写者问题,需要注意的是,这两种情况都可能出现 饥饿starvation,饥饿是一种无限期地阻塞。
第一类读者写者问题(读者优先)
- 如果写者没有获取到使用对象的权限,不应该让读者等待
- 在等待的写者之后到来的读者应该在写者之前处理
- 也就是说,只有没有读者的情况下,写者才能工作
第二类读者写者问题(写者优先)
- 一旦写者可以处理的时候,就不应该进行等待
- 在等待的写者之后到来的读者应该在写者之后处理
对于第一类读者写者问题(读者优先),书上给出一个简单解答
int readcnt;
/* Initially 0 */
sem_t mutex, w; /* Both initially 1 */
void reader(void) {
while (1) {
P(&mutex);
readcnt++;
if (readcnt == 1) /* First in */
P(&w);
V(&mutex);
/* Reading happens here */
P(&mutex);
readcnt--;
if (readcnt == 0) /* Last out */
V(&w);
V(&mutex);
}
}
Writers : void writer(void) {
while (1) {
P(&w);
/* Writing here */
V(&w);
}
}
使用线程提高并行性
并行和并发
所有程序都可以分为顺序程序或并发程序,而并行程序是一个运行在多个处理器的并发程序.也就是说,之前的流水线模型是一种”伪并发”的顺序程序
三者关系如下:
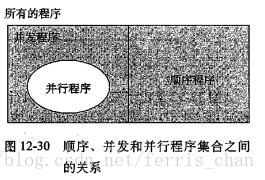
而线程的引入才真正实现并行程序的实现,但也带来的共享变量需要同步问题也是巨大的.
并行编程的一个重要的教训为:
* 同步开销巨大,要尽可能避免.如无可避免,也要用尽可能多的有用计算来弥补这个开销*
也就是同步得要有价值
而避免同步的一个方法为可以把一个大任务分成若干个独立的子任务,或者用分而治之的方式来解决;例如引入私有变量,不用共享变量
书上给了一个并行求数组和 还有一个 并行快排 的例子,值得研究
超线程
一般而言,一个核心处理一个线程。而在超线程的设计中,一个核心可以处理若干个线程,秘诀在于多出来了若干套指令控制流.
并发问题
这里可以承接SICP的3.4 节并发:时间是一个本质问题
说的是并发带来的问题
线程安全 和 可重入函数
在线程中调用的函数必须是线程安全的,定义为:
A function is thread-safe iff it will always produce correct results when called repeatedly from multiple concurrent threads
也就是:当且仅当被多个并发线程反复调用时,函数还会产生正确的结果
注意和 可重入函数区别,可以参考论坛上的讨论http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=971102
可重入是指线程安全函数在被多个线程调用时,不会引用任何的共享变量的函数,也就是线程安全函数的真子集
三者关系如下:

这里也可以结合数据库事务的理解,事务的特性如下(ACID):
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持续性(Durability )
而常见的线程不安全函数有四类:
- 1.不保护共享变量的函数
- 解决办法:使用 P 和 V semaphore 操作
- 问题:同步操作会影响性能
2.在多次调用间保存状态的函数
- 解决办法:把状态当做传入参数
-
- 返回指向静态变量的指针的函数
- 解决办法1:重写函数,传地址用以保存
- 解决办法2:上锁,并且进行复制
- 返回指向静态变量的指针的函数
4.调用线程不安全函数的函数
- 解决办法:只调用线程安全的函数
一般而言,标准 C 库中的函数都是线程安全的(如 malloc, free, printf, scanf),大多数 Unix 的系统调用也都是线程安全的。
竞争和死锁
竞争race
竞争指的是:它旨在描述一个系统或者进程的输出依赖于不受控制的事件出现顺序或者出现时机。此词源自于两个信号试着彼此竞争,来影响谁先输出。
数字电路上也有,一般是增加卡诺图的无关项来消去
而线程中,如果计算机中的两个线程同时试图修改一个共享内存的内容,在没有并发控制的情况下,最后的结果依赖于两个线程的执行顺序与时机。
也可以见竞争wiki
死锁deadlock
死锁:当两个以上的运算单元,双方都在等待对方停止执行,以取得系统资源,但是没有一方提前退出时,无穷无尽等下去。
其发生的条件:
- 禁止抢占:no preemption
- 持有和等待:hold and wait
- 互斥:mutual exclusion
- 循环等待:circular waiting
在进度图中,死锁区域为:
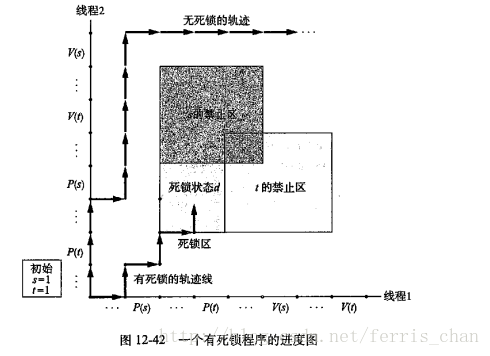
所以这里也有一个互斥锁加锁的顺序来避免死锁的发生,数据库中也有这个概念
* 给定一个互斥操作的一个全序,如果每个线程都是以一种顺序来获得互斥锁 并以相反的顺序释放,所以该程序就是无死锁的 *
数据库中的:
- 排它锁(eXclusive lock,简记为X锁)
- 排它锁又称为写锁
- 若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁
共享锁(Share lock,简记为S锁)
- 共享锁又称为读锁
- 若事务T对数据对象A加上S锁,则其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁
全书总结
有人说CSAPP是一本奇书,看完果然如此.从数电的二进制开始说起,谈到汇编机器码;然后到数据结构,库的调用,再到虚拟内存,链接; 也谈到异常控制,信号的处理; 还可以结合SICP谈到多线程,并行并发;同时也涉及网络编程,HTTP事务.
中间的lab实验也是很有趣,可以结合其他数据结构的算法,例如是内存的分配是集装箱问题等.这本书真的是amazing,遗憾的是没有早点看,之前看的都是零零散散的知识,这本书希望以后可以再读一下.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









