







 本文介绍了如何使用Linux工具nkf处理CSV文件中的乱码问题,通过nkf--guess检测文件编码,然后使用nkf-w8UTF-8转换并覆盖源文件,确保在不同编码环境下正确显示。
本文介绍了如何使用Linux工具nkf处理CSV文件中的乱码问题,通过nkf--guess检测文件编码,然后使用nkf-w8UTF-8转换并覆盖源文件,确保在不同编码环境下正确显示。
参考资料
一. 前期准备
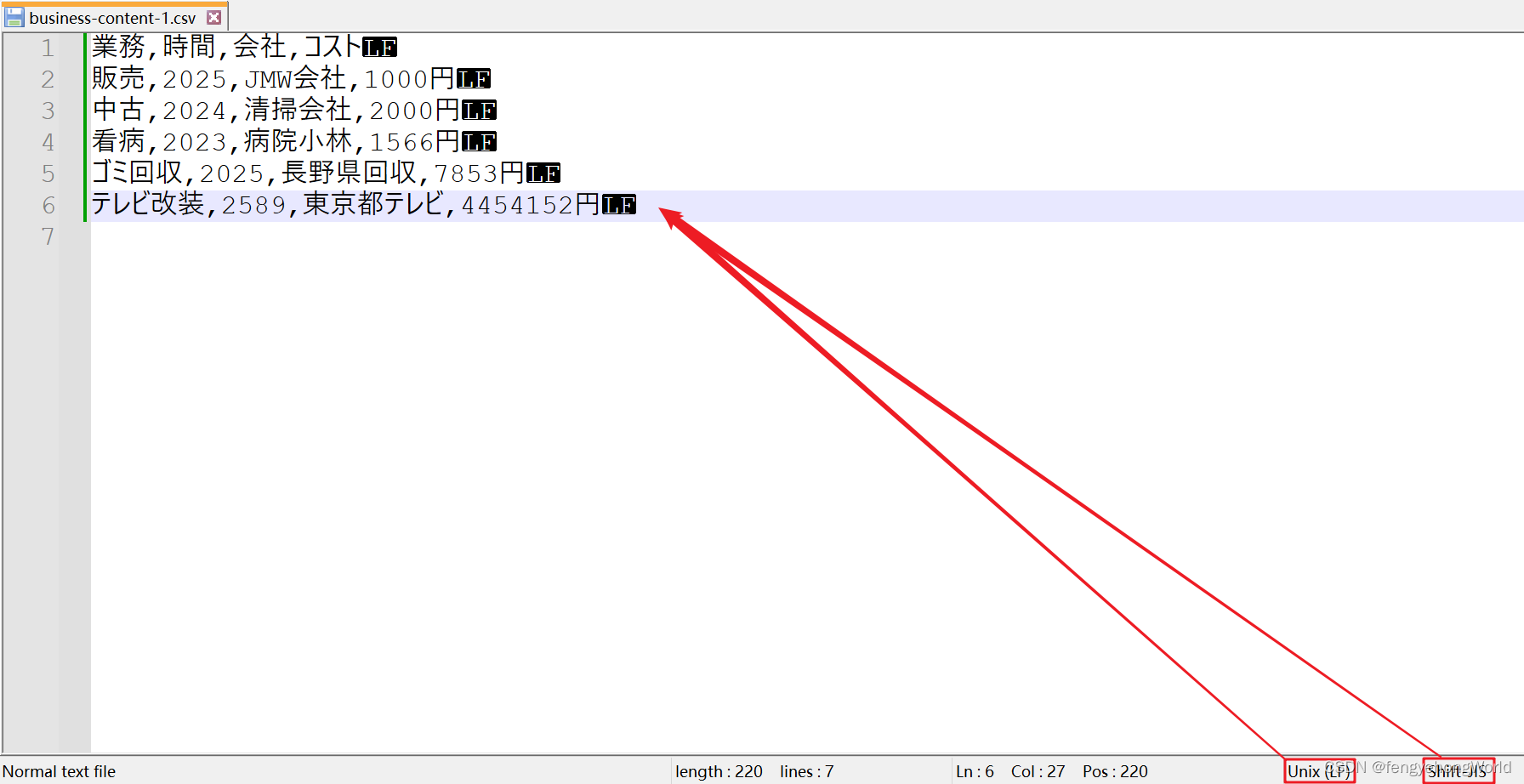
⏹有如下文件,business-content-1.csv
業務,時間,会社,コスト
販売,2025,JMW会社,1000円
中古,2024,清掃会社,2000円
看病,2023,病院小林,1566円
ゴミ回収,2025,長野県回収,7853円
テレビ改装,2589,東京都テレビ,4454152円
⏹由下图可见
- 该csv文件的编码为:Shift-JIS
- 换行符为:LF
二. 乱码现象与分析
😵我们直接使用cat命令打开文件的话,可以看到终端窗口出现了乱码。
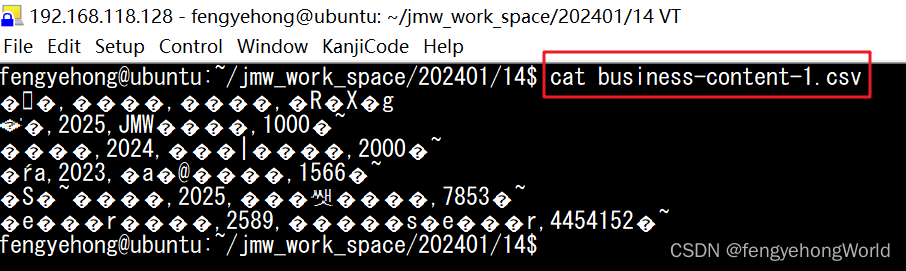
🤔我们使用的是Tera Term连接工具,默认编码为UTF-8格式,而csv文本为Shift-JIS格式,所以出现了乱码。
若我们将终端的显示编码改为Shift-JIS格式之后,再次cat,可以看到文件显示正常。
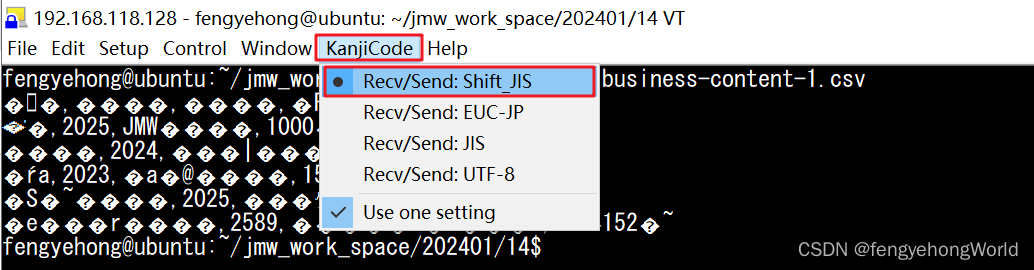
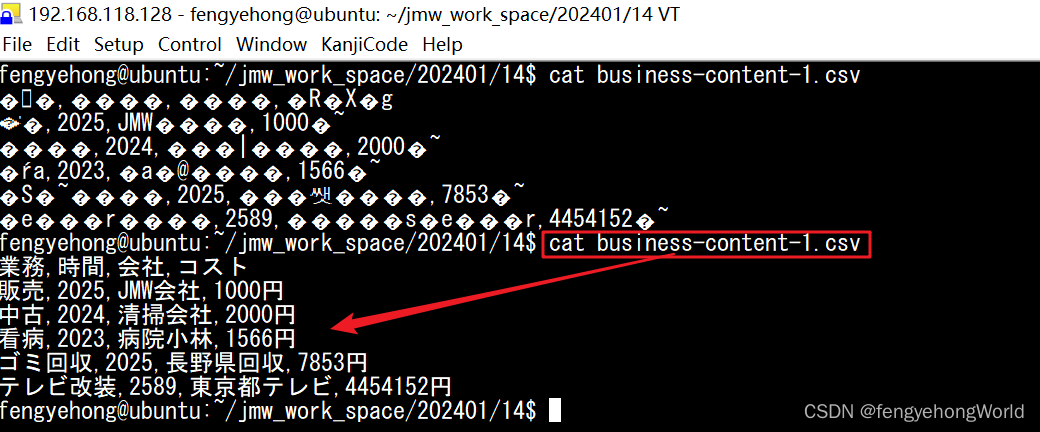
⏹如果要打开的文件,既有Shift-JIS编码的文件,还有其他编码的文件,我们不可能每次都修改终端的编码显示格式。
这个时候,就需要有一个工具来帮我们把转换编码之后的文字显示在终端上。
三. nkf命令简介
nkf命令的全称为 Network Kanji Filter,主要用于处理 日文编码转换,但也支持其他字符编码的转换和标准化,比如
- UTF-8
- Shift_JIS
- EUC-JP
- ISO-2022-JP 等
⏹输出配置项
| 短配置项 | 長配置项 | 意味 |
|---|---|---|
| -j | --jis | JISコードを出力する(默认配置项) |
| -e | --euc | EUCコードを出力する |
| -s | --sjis | Shift-JISコードを出力する |
| -w | UTF-8コードを出力する(BOMなし) | |
| -w8 | UTF-8コードを出力する(BOM有り) | |
| -w16,-w16B0 | UTF-16コードを出力する(ビッグエンディアン/BOMなし) | |
| -w16B | UTF-16コードを出力する(ビッグエンディアン/BOM有り) | |
| -w16L | UTF-16コードを出力する(リトルエンディアン/BOM有り) | |
| -w16L0 | UTF-16コードを出力する(リトルエンディアン/BOMなし) | |
| -I | ISO-2022-JP以外の漢字コードを「〓(げた記号)」に変換する | |
--oc 文字コード | 出力する文字コードを「EUC-JP」や「UTF-8」などで指定する | |
--overwrite | ファイルを変換して上書きする |
⏹换行符配置项
| 短配置项 | 方便记忆 | 意味 |
|---|---|---|
| -Lu | Linux → Unix → Lu | 改行をLFにする(UNIX系) |
| -Lw | Linux → Windows → Lw | 改行をCRLFにする(Windows系) |
| -Lm | Linux → Mac OS → Lm | 改行をCRにする(OS Xより前のmac OS系) |
⏹平片假名转换
nkf --katakana:平假名转换片假名nkf --hiragana:片假名转换平假名
四. 配置项示例
4.1 nkf --guess 查看文件编码
apluser@ubuntu24-01:~/work/20250412$ nkf --guess business-content-1.csv
Shift_JIS (LF)
4.2 输出为UTF-8
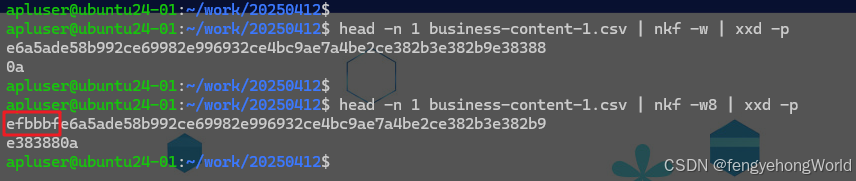
nkf -w 文件名:无BOM的UTF-8nkf -w8 文件名:有BOM的UTF-8

⏹如果通过16进制进程查看的话,可以看到 -w8比-w多了efbbbf,这三个字节 EF BB BF就是BOM。
4.3 换行符转换
⏹nkf 没有明确指定输出编码时,尝试自动识别输入编码,然后默认将输出转为 UTF-8(无 BOM)
-Lw:linux的换行符转换为windows的换行符-s:指定编码为Shift-JIS
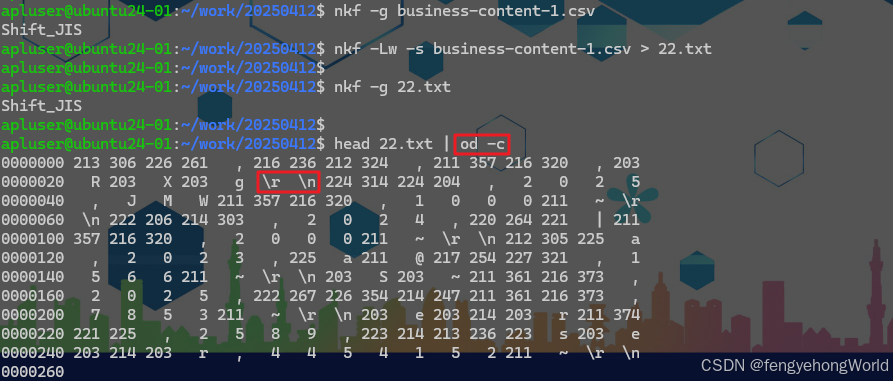
nkf -Lw -s business-content-1.csv > 输出文件名.txt
⏹直接cat文件的话,无法直观的查看换行符,通过od -c命令可以直观的看到换行符已经被转换为\r\n了。
4.4 平片假名转换
nkf --katakana:平假名转换片假名
apluser@ubuntu24-01:~$ echo -e "こんにちは\nおはよう" | nkf --katakana
コンニチハ
オハヨウ
nkf --hiragana:片假名转换平假名
apluser@ubuntu24-01:~$ echo -e "コンニチハ\nオハヨウ" | nkf --hiragana
こんにちは
おはよう

















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









