







 本文详细探讨了视觉目标跟踪的概念,包括基本原理:候选框生成、特征表达/提取和决策,以及如何在后续帧中找到感兴趣物体。通过运动员博尔特的例子解释了视觉目标跟踪的三方面问题。文章还介绍了视觉目标跟踪的应用场景,如安防、监控、巡检等,并概述了如何进行视觉目标跟踪,包括运动模型、特征模型和观测模型。最后,讨论了跟踪算法的评估指标和常用数据集。
本文详细探讨了视觉目标跟踪的概念,包括基本原理:候选框生成、特征表达/提取和决策,以及如何在后续帧中找到感兴趣物体。通过运动员博尔特的例子解释了视觉目标跟踪的三方面问题。文章还介绍了视觉目标跟踪的应用场景,如安防、监控、巡检等,并概述了如何进行视觉目标跟踪,包括运动模型、特征模型和观测模型。最后,讨论了跟踪算法的评估指标和常用数据集。
前言:
视觉目标跟踪 (visual object tracking) 是计算机视觉 (computer vision) 领域的一个重要研究问题。通常来说,视觉目标跟踪是在一个视频的后续帧中找到在当前帧中定义的感兴趣物体 (object of interest) 的过程,主要应用于一些需要目标空间位置以及外观(形状、颜色等)特性的视觉应用中。
1 什么是视觉目标跟踪
跟踪是在一个视频的后续帧中找到在当前帧中定义的感兴趣物体 (object of interest) 的过程。
注:上述定义主要关注跟踪的三方面问题,即“找到”、“感兴趣物体”、和“后续帧”。注意,这里的当前帧可以是视频中的任意一帧。通常来说,跟踪是从视频的第二帧开始的,第一帧用来标记目标的初始位置 (ground truth)。
下面,我们利用博尔特参加男子百米短跑的例子来解释这三方面问题。
视觉目标跟踪的基本原理

“找到”:如何locate博尔特?
假设在视频上一帧我们找到了博尔特所在的位置,我们要做的是在当前帧中继续找到博尔特所在的位置。如前所述,视觉是跟踪问题(视觉目标跟踪)的限定条件,其带来了可以利用的性质。在这里,我们可以利用的de facto rules是:在同一段视频中,相同的物体在前后两帧中的尺寸和空间位置不会发生巨大的变化。比如我们可以做出如下判断:博尔特在当前帧中的空间位置大概率会在跑道中,而几乎不可能在旁边的草坪内。也就是说,如果我们想知道博尔特在当前帧中的空间位置,我们只需要在跑道中生成一些候选位置,然后在其中进行寻找即可。上述过程引出了跟踪中一个重要的子问题,即candidate generation,通常被表述为候选框生成。
“感兴趣物体”:如何shape博尔特?
博尔特就是图像中个子最高,并且穿着黄色和绿色比赛服的人。但是,我们忽略了一个问题,就是我们对于博尔特的“定义”其实已经包含了很多高度抽象的信息,例如个子最高,还有黄色和绿色的比赛服。在计算机视觉领域中,我们通常将这些高度抽象的信息称之为特征。对于计算机而言,如果没有特征,博尔特和草坪、跑道、或者图像中其他对于人类有意义的物体没有任何区别。因此,想让计算机对博尔特进行跟踪,特征表达/提取 (feature representation/extraction) 是非常重要的一环,也是跟踪中第二个重要的子问题。
“后续帧”:如何distinguish博尔特 (from others) ?
在这里,我们将“后续帧”关注的问题定义为如何利用前一帧中的信息在当前帧中鉴别 (distinguish) 目标。我们不仅需要在“后续帧”中的每一帧都能完成对目标的跟踪,还强调连续帧之间的上下文关系对于跟踪的意义。直观理解,该问题的答案非常简单:在当前帧中找到最像上一帧中的跟踪结果的物体即可。这就引出了跟踪中第三个重要的子问题:决策 (decision making)。决策是跟踪中最重要的一个子问题,也是绝大多数研究人员最为关注的问题。通常来说,决策主要解决匹配问题,即将当前帧中可能是目标的物体和上一帧的跟踪结果进行匹配,然后选择相似度最大的物体作为当前帧的跟踪结果。
分别介绍了跟踪基本原理中的三个子问题:候选框生成、特征表达/提取、及决策。需要注意的是,这三个子问题并非彼此独立。有时候,决策问题的解决方案会包含更为精确的候选框生成和/或更为抽象的特征提取,利用端到端 (end-to-end) 的思想解决跟踪问题,来提高跟踪系统和算法的性能。这在近几年流行的基于深度学习的跟踪算法中非常常见。
视觉目标跟踪的应用
从某种意义来说,在回答“视觉目标跟踪有哪些应用”的问题之前,我们应该先讨论学术研究方法论中“为什么”的问题,即“为什么要做视觉目标跟踪”。
跟踪在计算机视觉科学的经典应用领域,包括安防领域(车辆跟踪、车牌识别等)、监控领域(人脸识别、步态识别等)、巡检领域(无人机追踪、机器人导航等)、以及新兴的智慧生活(人机交互、VR/AR等)、智慧城市(流量监测等)、以及智慧工业(远程医疗等)等。跟踪问题的主要应用可以总结为:跟踪主要应用于对视频或连续有语义关联的图像中任意目标的空间位置、形状和尺寸的获知。作为检测算法的补充,其可以在视频或连续有语义关联的图像中提供目标的空间位置,降低整个系统的复杂度(例如检测仅应用于视频第一帧识别出目标,以及后续帧中的某些帧来确定目标位置,然后在其余帧中应用跟踪确定目标位置)。
2 如何进行视觉目标跟踪
视觉目标跟踪的系统架构
候选框生成、特征表达/提取、和决策构成了一条完整的逻辑链路。具体来说,对于视频中的每一帧(通常不包括第一帧),跟踪的系统流程可以用图中的架构来表示:
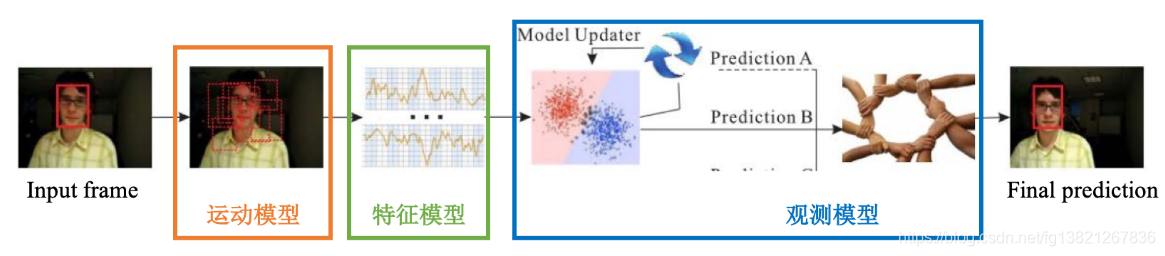
如图所示,在跟踪系统中,上一帧(含跟踪结果,如图中input frame)和当前帧会被作为系统输入,然后分别经过运动模型 (motion model)、特征模型 (feature model)、和观测模型 (observation model),最终作为当前帧对目标位置的预测 (final prediction) 输出。其中,候选框生成、特征表达/提取、和决策三个子问题分别在上述三个模型中被解决,其输入与输出的对应关系如表。
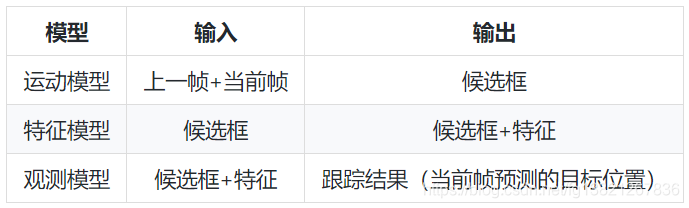
注意,图3中的跟踪系统架构应用了假设检验 (hypothesis testing
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









