







 本文介绍了如何利用MySQL binlog和Canal将数据实时增量同步到Elasticsearch,包括架构设计、Adapter设计思路、单表与多表同步策略,以及解决顺序性、可靠性和数据过滤等问题,旨在提供无侵入的数据库异构同步解决方案。
本文介绍了如何利用MySQL binlog和Canal将数据实时增量同步到Elasticsearch,包括架构设计、Adapter设计思路、单表与多表同步策略,以及解决顺序性、可靠性和数据过滤等问题,旨在提供无侵入的数据库异构同步解决方案。
背景
在我们的开发过程中,经常会在一个项目中使用多种数据库系统。在一些特定场景下,我们希望把数据从一种数据库,同步到另一种异构的数据库,以便进行数据分析统计、完成实时监控、实时搜索等功能。这个异构数据源同步的过程称为Change Data Capture(变化数据捕获)。

我们本文讨论的是Source为MySQL、Target为ElasticSearch的场景下,进行增量和全量同步操作过程。众所周知,MySQL数据库凭借其性能卓越、服务稳定、开放源代码、社区活跃等因素,成为当下最流行的关系型数据库,但是在数据量级较大或涉及到多表操作时,亦或是需要根据地理位置进行查询时,MySQL通常不能给我们很好的支持。
为了解决MySQL查询缓慢、无法查询的问题,我们通常采用ElasticSearch等进行配合检索。在传统方式中,将MySQL同步数据到ElasticSearch通常采用的是双写、MQ消息等形式,这些形式都存在着耦合高、性能差、丢失数据等风险。
所以我们需要探索出一套对业务无侵入的MySQL同步至ElasticSearch异构数据库的解决方案。本文将分别从增量同步、全量同步两个层面进行探讨。
增量同步
架构
将MySQL数据实时增量同步至ElasticSearch中,一般会借助MySQL增量日志binlog实现。目前比较流行的binlog解析获取中间件是由Alibaba开源的Canal,Canal译意为水道/管道/沟渠,主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。
所以我们整体的解决方案为:上游通过Canal将解析好的binlog消息发送到Kafka中,下游通过一个Adapter进行解析配置、消费消息。
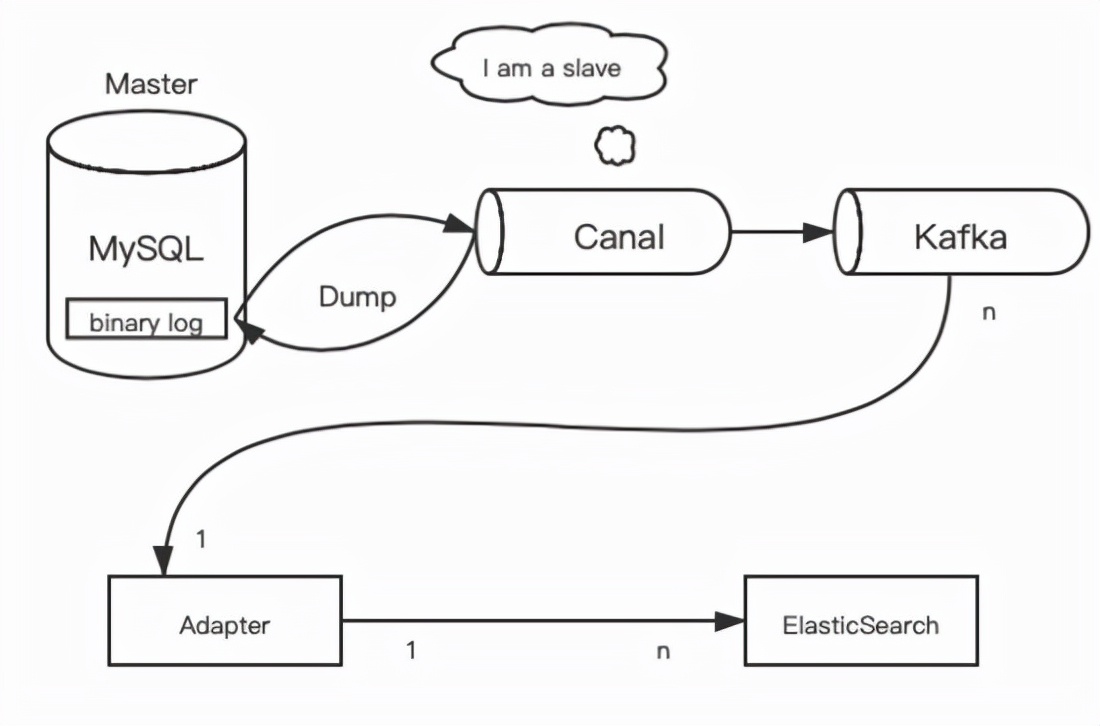
参考上面的图片,我们可以知道整体分成了三个步骤:
- Canal通过伪装成MySQL Slave,模拟MySQL Slave的交互协议,向MySQL Master发送dump协议,MySQL Master收到Canal发送过来的dump请求,开始推送binlog给Canal,然后Canal解析binlog;
- Canal将解析序列化好的binlog信息发送到Kafka;
- Adapter根据用户配置信息,接收Kafka中的信息解析处理,将最终数据更新到ElasticSearch的操作。
Adapter设计思路
经过调研,Adapter决定采用通过SQL语句配置,系统根据SQL进行解析获得所需表及字段映射关系形式。解析这一过程利用开源数据库连接池Druid实现。
比如下面的演示,用户配置了一条SQL语句,系统自动解析确定ElasticSearch的字段信息,并缓存MySQL的表和字段与ElasticSearch的字段映射关系。
使用者可以通过定义字段的别名设置在ElasticSearch中的对应字段名,同名字段则不需要别名。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









