






 本文介绍了字典树(Trie Tree)在前缀搜索中的应用,通过优化存储结构减少内存浪费并提高查询效率。在示例中,详细展示了字典树节点的实现及插入、查询操作。字典树的每个节点代表一个字符,通过子节点数组表示字符值,支持大小写查询。在查询时,采用递归深度遍历的方式查找匹配的字符串。
本文介绍了字典树(Trie Tree)在前缀搜索中的应用,通过优化存储结构减少内存浪费并提高查询效率。在示例中,详细展示了字典树节点的实现及插入、查询操作。字典树的每个节点代表一个字符,通过子节点数组表示字符值,支持大小写查询。在查询时,采用递归深度遍历的方式查找匹配的字符串。
字典树一般使用在前缀名搜索中,例如我要搜索自己微信朋友中的某个好友,只需要输入它的前几个字,系统就会给我返回一个包含这些字符的姓名集合。大致效果如下所示:
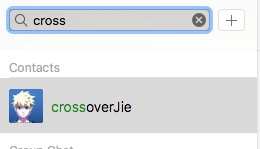
再没有任何限制的条件下我们最简单的实现是把这些所有的字符串存放在一个容器中(List,Set)查询时挨个遍历,利用String.startWith(“prefix”)来进行搜索
但这样有几个问题
第一、首先存储资源比较浪费
第二、查询效率比较低,需要遍历集合后再遍历字符串的char数组
假设我需要存放 java,javascript,jsp,php 这些字符串时在 ArrayList 中会怎么存放?
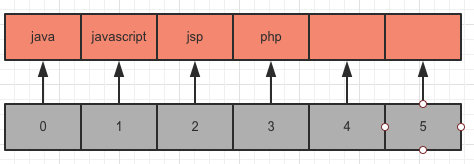
很明显,会是这样完整的存放在一个数组中;同时这个数组还可能存在浪费,没有全部使用完。
但其实仔细观察这些数据会发现有一些共同特点,比如 java,javascript 有共同的前缀 java;和 jsp 有共同的前缀 j。
那是否可以把这些前缀利用起来呢?这样就可以少存储一份。
比如写入 java,javascript 这两个字符串时存放的结构如下:
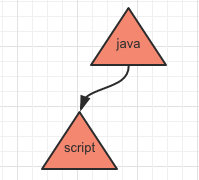
当再存入一个 jsp 时:
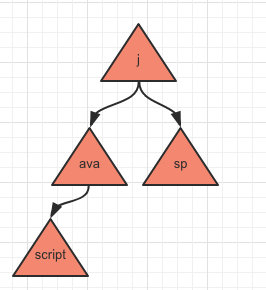
相信大家应该已经看明白了,按照这样的存储方式可以节省很多内存,同时查询效率也比较高。
具体实现
/**
* 字典树节点
*/
private class Node {
/**
* 是否为最后一个字符
*/
public boolean isEnd = false;
/**
* 如果只是查询,则不需要存储数据
*/
public char data;
public Node[] children = new Node[CHILDREN_LENGTH];
}
字典树的节点实现,其中的 isEnd 判断是否是最后一个节点
利用一个 Node[] children 来存放子节点。
public class TrieTree {
/**
* 大小写都可保存
*/
private static final int CHILDREN_LENGTH = 26 * 2;
/**
* 存放的最大字符串长度
*/
private static final int MAX_CHAR_LENGTH = 16;
private static final char UPPERCASE_STAR = 'A';
/**
* 小写就要 -71
*/
private static final char LOWERCASE_STAR = 'G';
目前只能支持大小写字母的查询
为了可以区分大小写查询,所以子节点的长度相当于是 26*2。
写入数据
public void insert(String data) {
this.insert(this.root, data);
}
private void insert(Node root, String data) {
char[] chars = data.toCharArray();
for (int i = 0; i < chars.length; i++) {
char aChar = chars[i];
int index;
//标记点1
if (Character.isUpperCase(aChar)) {
index = aChar - UPPERCASE_STAR;
} else {
//小写就要 -71
index = aChar - LOWERCASE_STAR;
}
//标记点2
if (index >= 0 && index < CHILDREN_LENGTH) {
if (root.children[index] == null) {
Node node = new Node();
root.children[index] = node;
root.children[index].data = chars[i];
}
//标记点3
//最后一个字符设置标志
if (i + 1 == chars.length) {
root.children[index].isEnd = true;
}
//指向下一节点
root = root.children[index];
}
}
}
这里以一个单测为例,写入了三个字符串,那最终形成的数据结构如下:
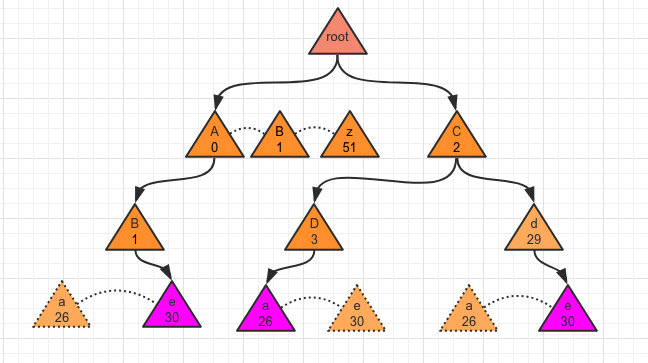
- 每个节点都是一个字符,这样树的高度最高为52
- 每个节点的子节点都是长度为 52 的数组;所以可以利用数组的下标表示他代表的字符值。比如 0 就是大 A,26 则是小 a,以此类推。
查询数据
public List<String> prefixSearch(String key) {
List<String> value = new ArrayList<String>();
if (StringUtil.isEmpty(key)) {
return value;
}
char k = key.charAt(0);
int index;
if (Character.isUpperCase(k)) {
index = k - UPPERCASE_STAR;
} else {
index = k - LOWERCASE_STAR;
}
if (root.children != null && root.children[index] != null) {
return query(root.children[index], value,
key.substring(1), String.valueOf(k));
}
return value;
}
其实就是采用递归进行深度遍历
private List<String> query(Node child, List<String> value, String key, String result) {
if (child.isEnd && key == null) {
value.add(result);
}
if (StringUtil.isNotEmpty(key)) {
char ca = key.charAt(0);
int index;
if (Character.isUpperCase(ca)) {
index = ca - UPPERCASE_STAR;
} else {
index = ca - LOWERCASE_STAR;
}
/**
else的话说明构造的字典树中没有要搜索的字母,
比如字典树中有java,javascript但是搜索的却是mmmm,
直接返回空value即可
*/
if (child.children[index] != null) {
query(child.children[index], value, key.substring(1).equals("") ? null : key.substring(1), result + ca);
}
} else {
for (int i = 0; i < CHILDREN_LENGTH; i++) {
if (child.children[i] == null) {
continue;
}
int j;
if (Character.isUpperCase(child.children[i].data)) {
j = UPPERCASE_STAR + i;
} else {
j = LOWERCASE_STAR + i;
}
char temp = (char) j;
query(child.children[i], value, null, result + temp);
}
}
return value;
}
查询总的来说要麻烦一些,其实就是对树进行深度遍历;最终的思想看图就能明白。















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









