






 本文介绍了Google的Protocol Buffers(protobuf),一种轻量级、高效的数据序列化格式,适用于网络通信、持久化存储、配置文件等场景。protobuf通过二进制编码实现高性能、小体积,提供代码生成机制支持多种编程语言,但存在可读性差和非自描述的缺点。文中还详细讲解了protobuf的C++使用、proto文件语法以及测试结果。
本文介绍了Google的Protocol Buffers(protobuf),一种轻量级、高效的数据序列化格式,适用于网络通信、持久化存储、配置文件等场景。protobuf通过二进制编码实现高性能、小体积,提供代码生成机制支持多种编程语言,但存在可读性差和非自描述的缺点。文中还详细讲解了protobuf的C++使用、proto文件语法以及测试结果。
1 需求
为了完成跨进程或跨语言的带数据结构的消息交互,我们引入序列化/发序列化技术,将多种数据序列化为无格式的二进制数据流,然后在接收端将接受的二进制数据流反序列还原为源数据结构。
2 protobuf介绍
2.1 简介
Protobuf 全称 Google Protocol Buffer,是由 Google 开发的一种轻量级、高效、可扩展的数据序列化格式。它旨在用于结构化数据的序列化,主要用于通信协议、数据存储等场景。
适用场景:
- 网络通信:用于跨语言和跨平台的网络通信,例如 RPC(Remote Procedure Call)。
- 持久化存储:将结构化数据序列化后存储在文件或数据库中。
- 配置文件:用于配置文件的读写和管理。
- 数据交换:用于不同系统之间的数据交换和共享。
总的来说,Protobuf 是一种灵活、高效的数据序列化工具,特别适用于需要在不同系统和语言间传输结构化数据的场景,同时也提供了易于使用的接口和强大的数据定义和管理能力。
2.2 优点
- 性能好/效率高
- 时间维度:Protobuf采用二进制编码,可以直接进行内存映射,相比XML解析速度更快。Protobuf的序列化/反序列化速度更快,可以更快地将数据从一个格式转换为另一个格式。在修改协议时,只需增加或删除字段,不用考虑XML那样涉及到数据结构和数据内容的修改,更方便快捷。
- 空间维度:相比XML,Protobuf生成的二进制文件更小,因为它使用了紧凑的二进制编码方式。
- 整体而言,Protobuf以高效的二进制方式存储,比XML小3到10倍,快20到100倍。
- 代码生成机制
在分布式系统中,因为程序代码时分开部署,比如分别为A、B。A系统在调用B系统时,无法直接采用代码的方式进行调用,因为A系统中不存在B系统中的代码。因此,A系统只负责将调用和通信的数据以二进制数据包的形式传递给B系统,由B系统根据获取到的数据包,自己构建出对应的数据对象,生成数据对象定义代码文件。这种利用编译器,根据数据文件自动生成结构体定义和相关方法的文件的机制被称作代码生成机制。
代码生成机制的优点
首先,代码生成机制能够极大解放开发者编写数据协议解析过程的时间,提高工作效率;其次,易于开发者维护和迭代,当需求发生变更时,开发者只需要修改对应的数据传输文件内容即可完成所有的修改。
- 支持“向后兼容”和“向前兼容”
向后兼容:在软件开发迭代和升级过程中,"后"可以理解为新版本,越新的版本越靠后;而“前”意味着早起的版本或者先前的版本。向“后”兼容即是说当系统升级迭代以后,仍然可以处理老版本的数据业务逻辑。
向前兼容:向前兼容即是系统代码未升级,但是接受到了新的数据,此时老版本生成的系统代码可以处理接收到的新类型的数据。
支持前后兼容是非常重要的一个特点,在庞大的系统开发中,往往不可能统一完成所有模块的升级,为了保证系统功能正常不受影响,应最大限度保证通讯协议的向前兼容和向后兼容。
- 支持多种编程语言
Protobuf官方工程主页上显示的已支持的开发语言多达10种,分别有:C++、Java、Python、Objective-C、C#,JavaNano、JavaScript、Ruby、Go、PHP。
此外Protebuf还有丰富的第三方扩展(点此查看)。
2.3 缺点
- 可读性较差
为了提高性能,Protobuf采用了二进制格式进行编码。二进制格式编码对于开发者来说,是没办法阅读的。在进行程序调试时,比较困难。
- 缺乏自描述
诸如XML语言是一种自描述的标记语言,即字段标记的同时就表达了内容对应的含义。而Protobuf协议不是自描述的,Protobuf是通过二进制格式进行数据传输,开发者面对二进制格式的Protobuf,没有办法知道所对应的真实的数据结构,因此在使用Protobuf协议传输时,必须配备对应的proto配置文件。
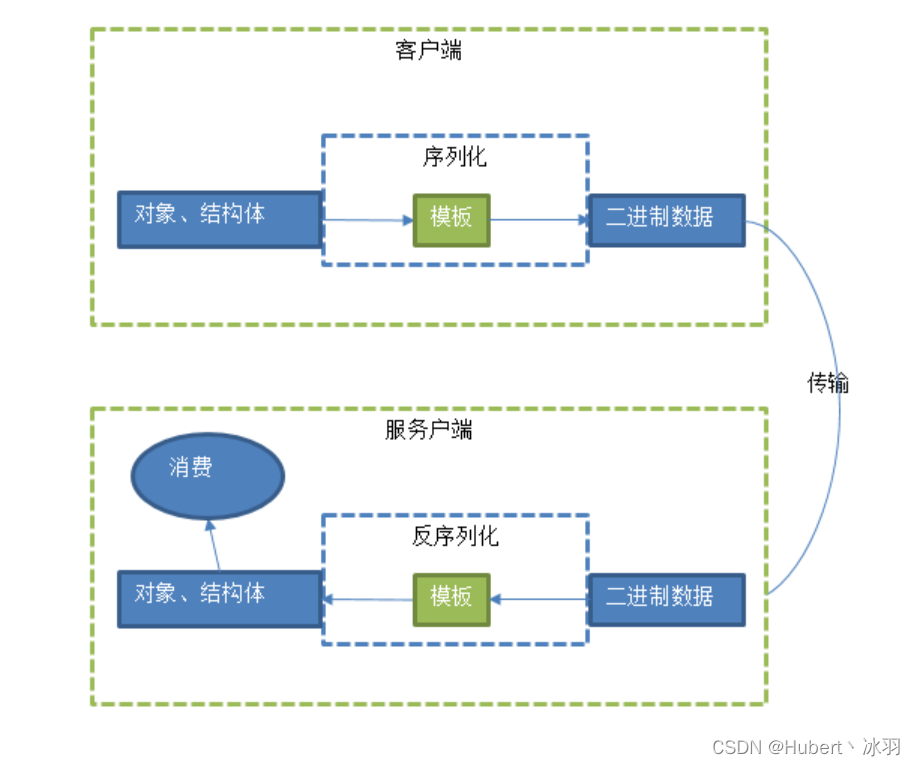
2.4 ProtoBuf在系统中的作用
通信模型如下图,ProtoBuf在此过程中用于序列化和反序列化操作。
3 C++文件
3.1 消息结构
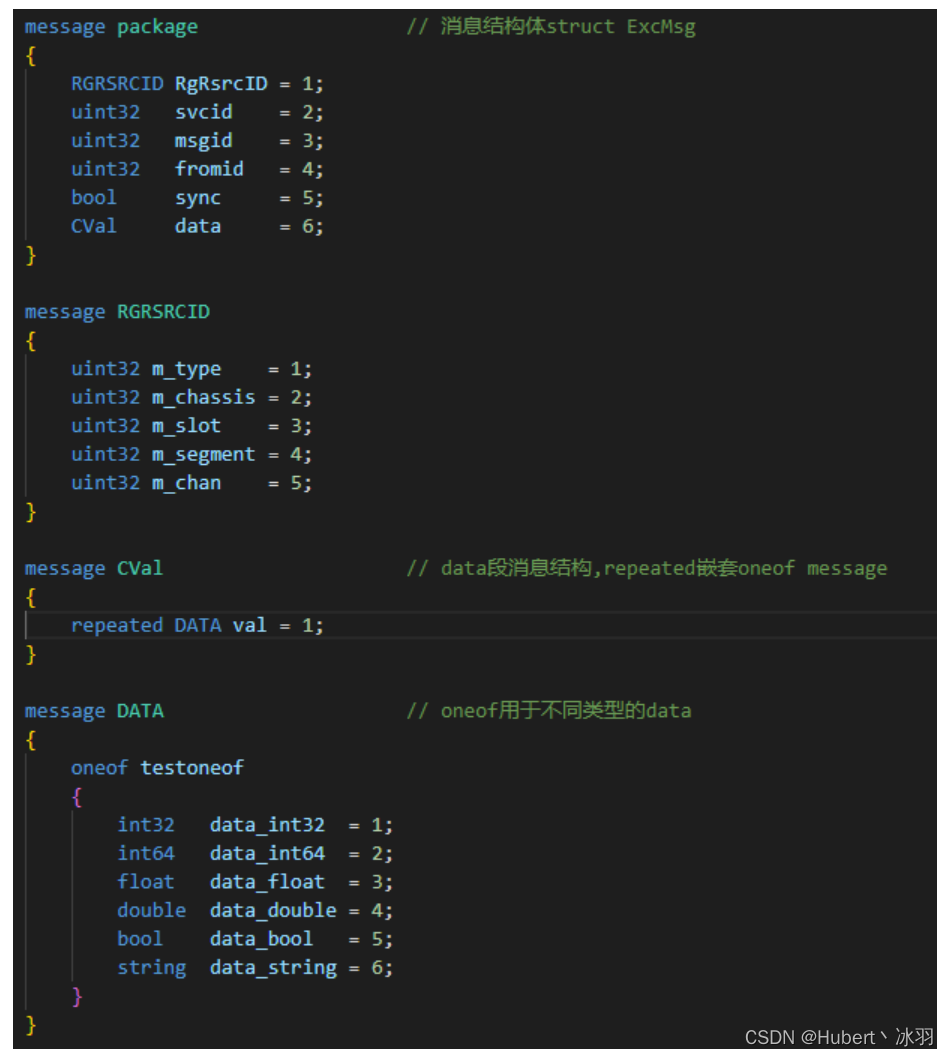
假设消息结构体struct ExcMsg如下表:
| 关键字 | 类型 | 说明 |
|---|---|---|
| RgRsrcID | struct RgRsrcID | 定义硬件对象 |
| svcid | unsigned int16 | 服务id |
| msgid | unsigned int32 | 消息id |
| fromid | unsigned int8 | 消息来源 |
| sync | bool | true: 同步消息,false: 异步消息 |
| data | struct CVal | data封装为包含任意数据类型的结构体,以及对数据操作的接口封装(定义为类的成员函数) |
说明:通过serviceid、msgid确定函数ID,通过fromid确定消息来源,通过RgRsrcID 结构体确定板卡最小操作单位通道。
- ExcMsg消息结构中的成员变量-RgRsrcID 结构体定义,包含最基本几个成员变量:type(板卡类型),chassis(机箱)、slot(子卡)、chan(通道)
| RgRsrcID | 类型 | 说明 |
|---|---|---|
| m_type | unsigned int8 | 板卡类型 |
| m_chassis | unsigned int8 | 机箱号 |
| m_slot | unsigned int8 | 子卡号 |
| m_segment | unsigned int8 | reserved |
| m_chan | std::bitset<EVT_MAX_CH> #denfine EVT_MAX_CH 512 | 选定通道,支持多通道设置,最大可设置512个通道 |
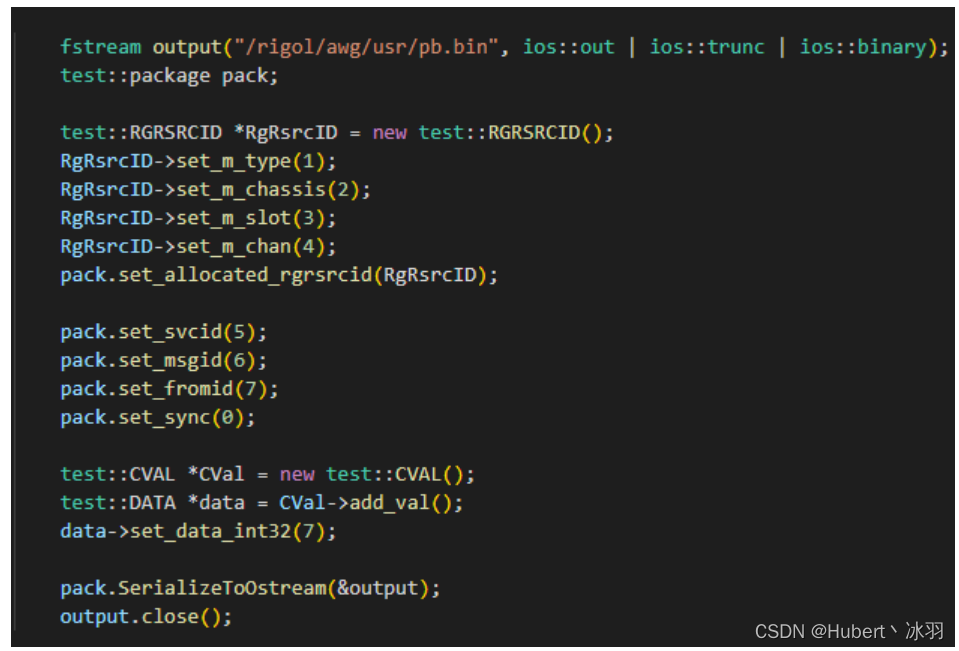
3.2 序列化测试代码
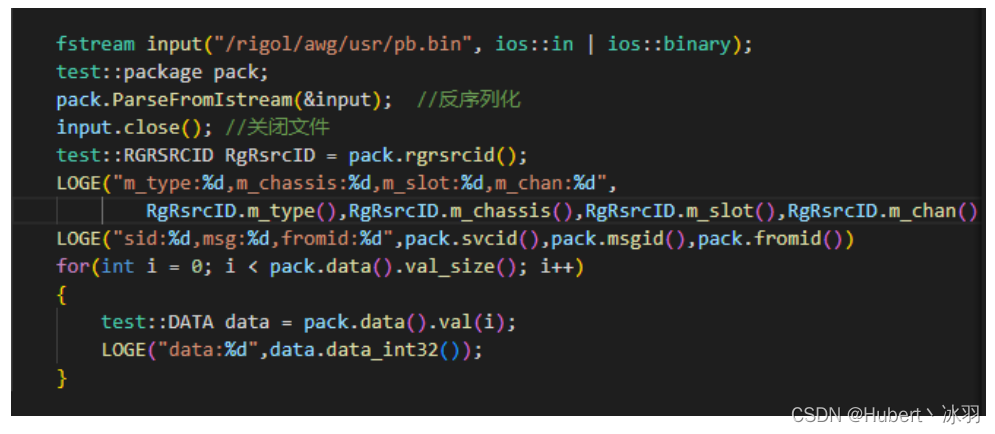
3.3 反序列化测试代码
4 Proto文件
.1 proto文件代码
4.2 protobuf语法
4.2.1 关键字
- message
在使用 Protocol Buffers 之前,我们需要先定义一个消息格式。这个消息格式定义了消息的类型以及每个字段的名称和类型。
- 分配字段编号
每个消息定义中的每个字段都有唯一的编号。这些字段编号用于标识消息二进制格式中的字段,并且在使用消息类型后不应更改。请注意,范围 1 到 15 中的字段编号需要一个字节进行编码,包括字段编号和字段类型。范围 16 至 2047 中的字段编号需要两个字节。所以你应该保留数字 1 到 15 作为非常频繁出现的消息元素。请记住为将来可能添加的频繁出现的元素留出一些空间
- repeated 字段:
可以在一个 message 中重复任何数字多次(包括 0 ),不过这些重复值的顺序被保留。
- oneof字段
oneof字段与c++中的联合体相似。
如果您有一条包含许多字段的消息,并且最多同时设置一个字段,那么您可以通过使用其中一个特性来强制执行此行为,并节省内存。
Oneof字段类似于常规字段,只不过共享内存中的一个字段中的所有字段都是常规字段,而且最多可以同时设置一个字段。设置其中的任何成员都会自动清除所有其他成员。根据所选择的语言,可以使用特殊 case() 或 WhichOneof() 方法检查 one of 中的哪个值被设置(如果有的话)。
oneof字段不可以使用repeated字段,需要使用消息嵌套的方式来解决。
4.2.2 示例
4.2.2.1 message示例
例如,假设我们要定义一个消息格式表示一个人,这个人有一个 ID,一个名字和一个邮箱地址,我们可以用如下的 .proto 文件定义消息:

在这个文件中,我们定义了一个名为 Person 的消息格式,它有三个字段:id、name 和 email。字段的类型分别为 int32、string 和 string。每个字段都有一个唯一的编号,我们称之为字段标识符。
在 .proto 文件中定义消息格式之后,我们可以使用 Protocol Buffers 编译器将 .proto 文件编译成对应语言的类或结构体,从而方便我们在代码中创建和使用消息。
对于 C++ 语言,编译器会生成一个包含每个消息字段的 get 和 set 方法的类。我们可以通过创建这个类的对象来设置或获取消息中的每个字段的值。例如,我们可以使用以下代码创建一个 Person 对象并设置其 id、name 和 email 字段的值:
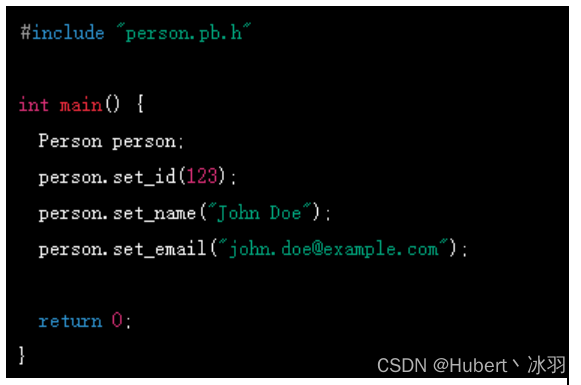
4.2.2.2 repeated示例
定义protobuf结构如下:

在这个文件中,我们定义了一个名为 Person 的消息格式,它有两个字段:id、name。字段的类型分别为 int32、string 。每个字段都有一个唯一的编号,我们称之为字段标识符。我们再定义一个名为Family的消息格式,他有一个字段:person,类型为消息格式Person,用repeated修饰。我们可以通过创建多个person,将其加入Family,用法如下:
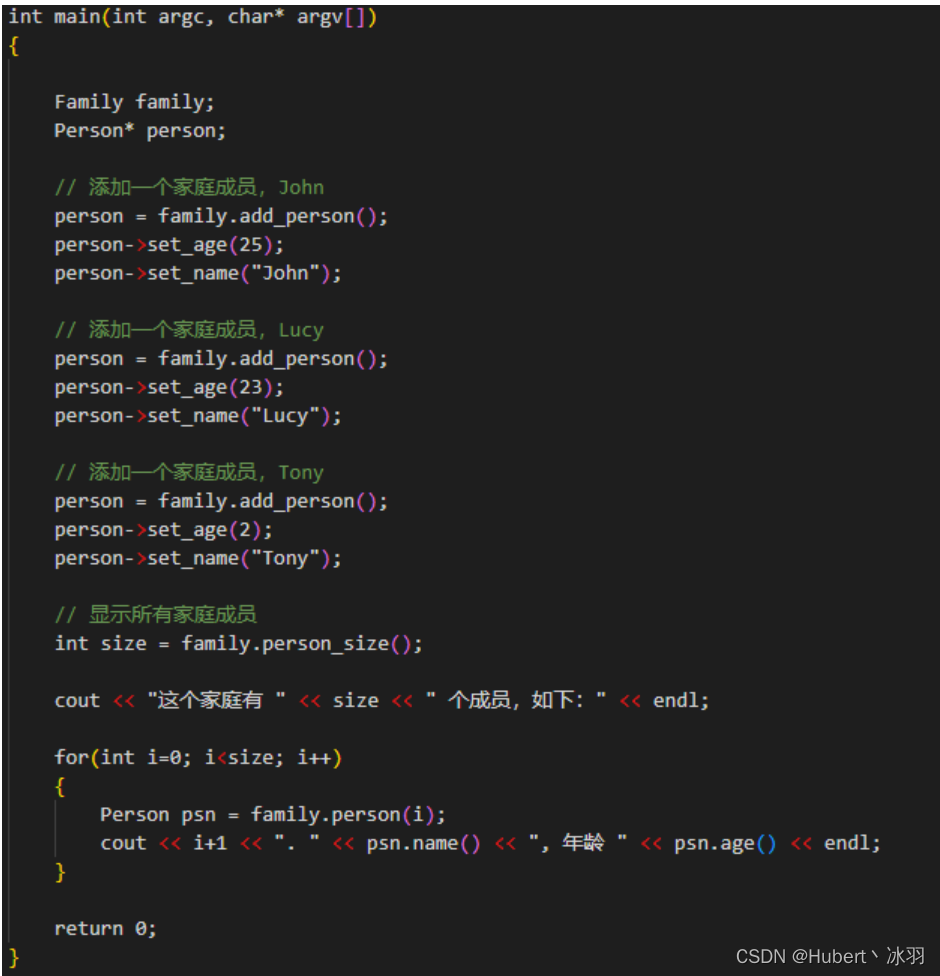
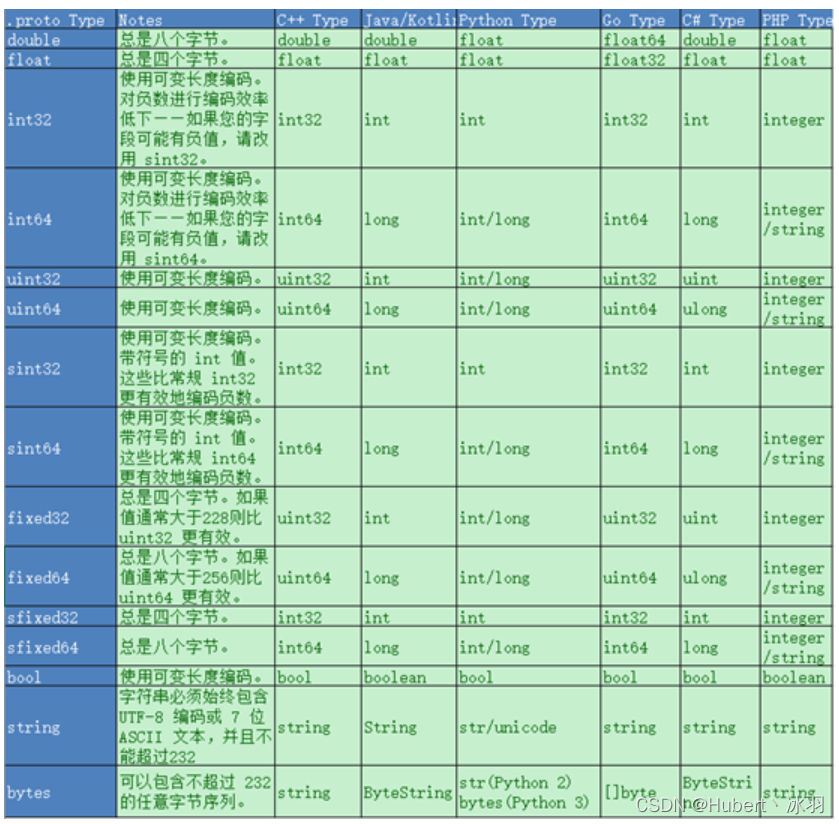
- 各个语言标量类型对应关系
5 测试结果
序列化发送
- struct RgRsrcID :m_type:1,m_chassis:2,m_slot:3,m_chan:4
- sid:5,msg:6,fromid:7,sync:0
- 数据段同时发送五个类型的数据:int,int64,float,bool,string
反序列化结果
- m_type:1,m_chassis:2,m_slot:3,m_chan:4
- sid:5,msg:6,fromid:7,sync:0
- data:8,999999999999999999,1.230000,0,six
序列化前,反序列后数据相同,未丢失。
对比:
RK3399结果如下
| 数据量 | 52 byte | 99 byte | 991 byte | 3419 byte | ||||
|---|---|---|---|---|---|---|---|---|
| Stream(ns) | String (ns) | Stream(ns) | String (ns) | Stream(ns) | String (ns) | Stream(ns) | String (ns) | |
| 序列化 | 11,427 | 7,869 | 15,819 | 9,658 | 121,424 | 75,431 | 446,953 | 268,624 |
| 反序列化 | 16,098 | 14,121 | 22,946 | 20,454 | 170,251 | 170,384 | 749,838 | 756,743 |
x86结果如下
| 数据量 | 52 byte | 99 byte | 991 byte | 3419 byte | ||||
|---|---|---|---|---|---|---|---|---|
| Stream(ns) | String (ns) | Stream(ns) | String (ns) | Stream(ns) | String (ns) | Stream(ns) | String (ns) | |
| 序列化 | 3,869 | 3,795 | 5,397 | 5,402 | 40,439 | 40,202 | 150,005 | 154,420 |
| 反序列化 | 6,555 | 5,951 | 8,778 | 8,403 | 80,775 | 78,661 | 365,803 | 381,032 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









