






引言
作为工程师,每天接触的是电源的设计工程师,发现不管是电源的老手,高手,新手,几乎对控制环路的设计一筹莫展,基本上靠实验.靠实验当然是可以的,但出问题时往往无从下手,在这里我想以反激电源为例子(在所有拓扑中环路是最难的,由于RHZ 的存在),大概说一下怎么计算,至少使大家在有问题时能从理论上分析出解决问题的思路。
1、一些基本知识,零,极点的概念
示意图:
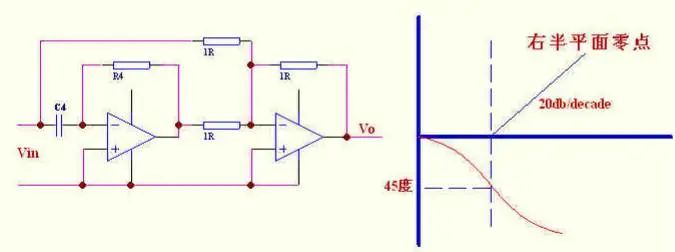
这里给出了右半平面零点的原理表示,这对用PSPICE 做仿真很有用,可以直接套用此图。
递函数自己写吧,正好锻炼一下,把输出电压除以输入电压就是传递函数。
bode 图可以简单的判定电路的稳定性,甚至可以确定电路的闭环响应,就向我下面的图中表示的.零,极点说明了增益和相位的变化。
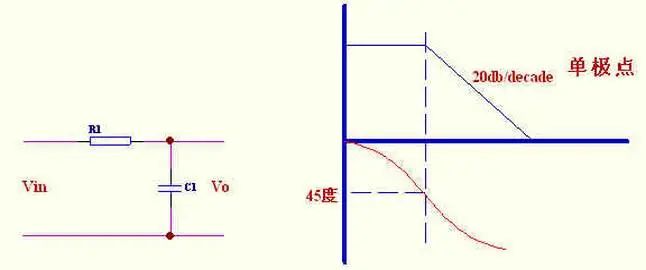
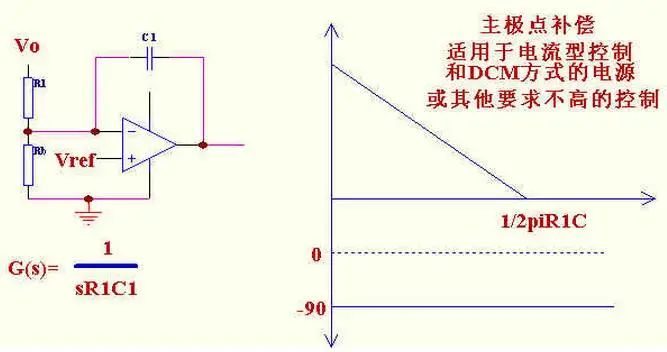
2、单极点补偿
适用于电流型控制和工作在DCM 方式并且滤波电容的ESR 零点频率较低的电源.其主要作用原理是把控制带宽拉低,在功率部分或加有其他补偿的部分的相位达到180 度以前使其增益降到0dB. 也叫主极点补偿。
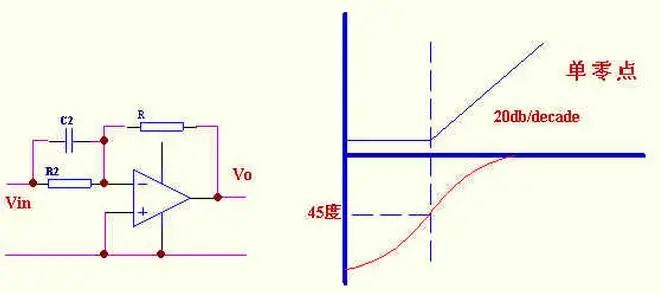
双极点,单零点补偿,适用于功率部分只有一个极点的补偿.如:所有电流型控制和非连续方式电压型控制。
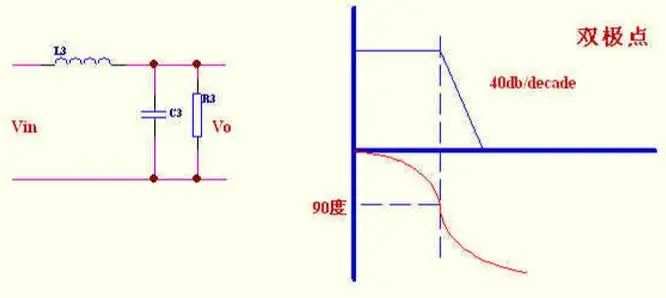
三极点,双零点补偿.适用于输出带LC谐振的拓扑,如所有没有用电流型控制的电感电流连续方式拓扑。
C1 的主要作用是和R2 提升相位的.当然提高了低频增益.在保证稳定的情况下是越小越好。
C2 增加了一个高频极点,降低开关躁声干扰。
串联C1 实质是增加一个零点,零点的作用是减小峰值时间,使系统响应加快,并且死循环越接近虚轴,这种效果越好.所以理论上讲,C1 是越大越好.但要考虑,超调量和调节时间,因为零点越距离虚轴越近,死循环零点修正系数Q 越大,而Q 与超调量和调节时间成正比,所以又不能大.总之,考虑死循环零点要折衷考虑。
并联C2 实质是增加一个极点,极点的作用是增大峰值时间,使系统响应变慢.所以理论上讲,C2也是越大越好.但要考虑到,当零极点彼此接近时,系统响应速度相互抵消.从这一点就可以说明,我们要及时响应的系统C1 大,至少比C2 大。
3、环路稳定的标准
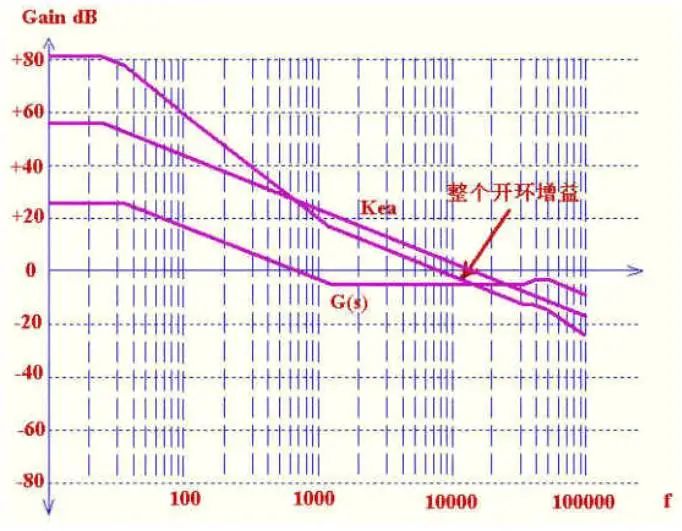
只要在增益为1 时(0dB)整个环路的相移小于360 度,环路就是稳定的。
但如果相移接近360 度,会产生两个问题:1)相移可能因为温度,负载及分布参数的变化而达到360 度而产生震荡;2)接近360 度,电源的阶跃响应(瞬时加减载)表现为强烈震荡,使输出达到稳定的时间加长,超调量增加.如下图所示具体关系。
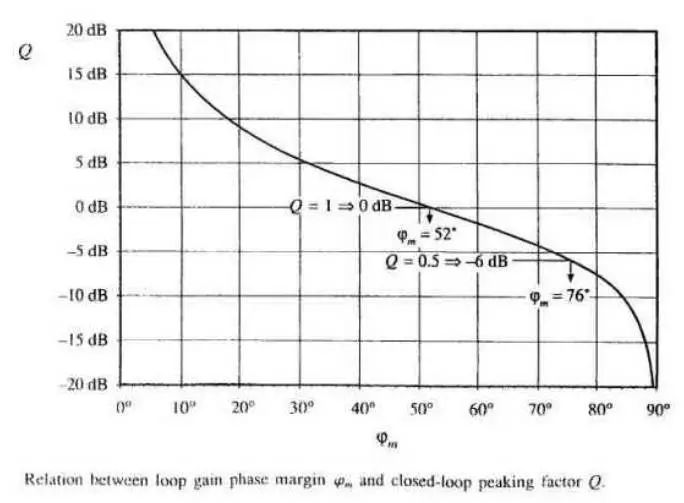
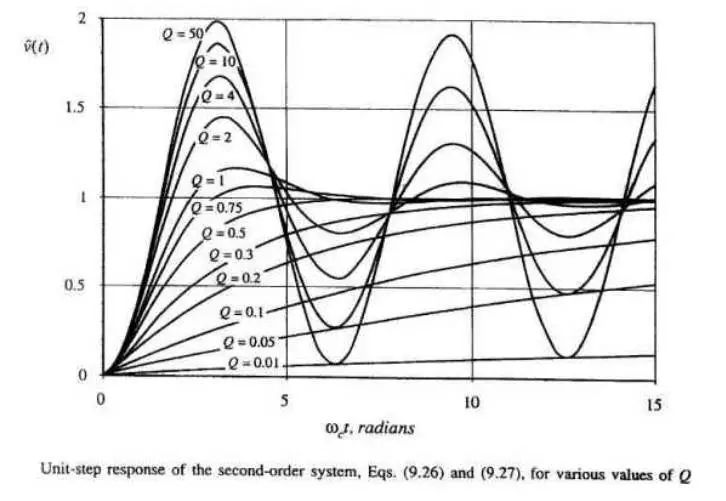
所以环路要留一定的相位裕量,如图Q=1时输出是表现最好的,所以相位裕量的最佳值为52度左右,工程上一般取45度以上.如下图所示:
这里要注意一点,就是补偿放大器工作在负反馈状态,本身就有180度相移,所以留给功率部分和补偿网络的只有180度.幅值裕度不管用上面哪种补偿方式都是自动满足的,所以设计时一般不用特别考虑.由于增益曲线为-20dB/decade时,此曲线引起的最大相移为90度,尚有90度裕量,所以一般最后合成的整个增益曲线应该为-20dB/decade部分穿过0dB.在低于0dB带宽后,曲线最好为-40dB/decade,这样增益会迅速上升,低频部分增益很高,使电源输出的直流部分误差非常小,既电源有很好的负载和线路调整率。
4、如何设计控制环路?
经常主电路是根据应用要求设计的,设计时一般不会提前考虑控制环路的设计.我们的前提就是假设主功率部分已经全部设计完成,然后来探讨环路设计。
环路设计一般由下面几过程组成:
1)画出已知部分的频响曲线。
2)根据实际要求和各限制条件确定带宽频率,既增益曲线的0dB频率。
3)根据步骤2)确定的带宽频率决定补偿放大器的类型和各频率点.使带宽处的曲线斜率为20dB/decade,画出整个电路的频响曲线。
上述过程也可利用相关软件来设计:如pspice,POWER-4-5-6.一些解释:
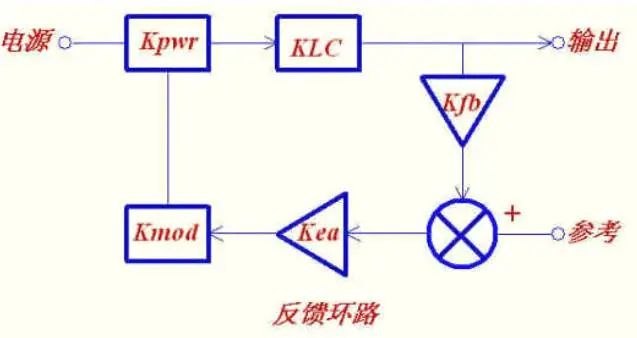
已知部分的频响曲线是指除Kea(补偿放大器)外的所有部分的乘积,在波得图上是相加。
环路带宽当然希望越高越好,但受到几方面的限制:a)香农采样定理决定了不可能大于1/2Fs;b)右半平面零点(RHZ)的影响,RHZ随输入电压,负载,电感量大小而变化,几乎无法补偿,我们只有把带宽设计的远离它,一般取其1/4-1/5;c)补偿放大器的带宽不是无穷大,当把环路带宽设的很高时会受到补偿放大器无法提供增益的限制,及电容零点受温度影响等.所以一般实际带宽取开关频率的1/6-1/10。
5、反激设计实例
条件:
输入85-265V交流,整流后直流100-375V输出12V/5A
初级电感量370uH初级匝数:40T,次级:5T
次级滤波电容1000uFX3=3000uF震荡三角波幅度.2.5V开关频率100K,电流型控制时,取样电阻取0.33欧姆。
下面分电压型和峰值电流型控制来设计此电源环路.所有设计取样点在输出小LC前面.如果取样点在小LC后面,由于受LC谐振频率限制,带宽不能很高.1)电流型控制。
假设用3842,传递函数如下:
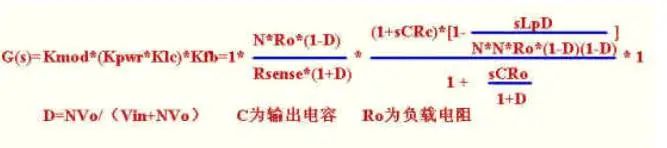
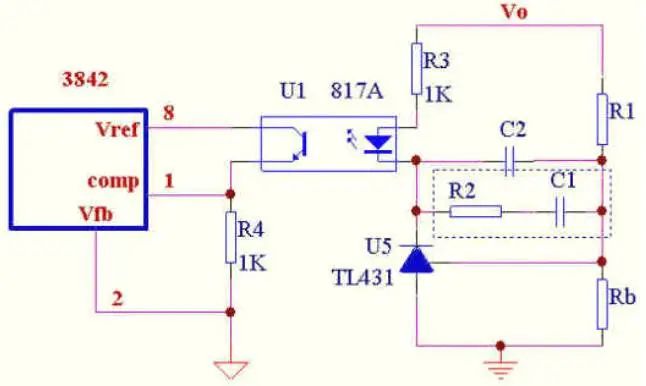

此图为补偿放大部分原理图.RHZ的频率为33K,为了避免其引起过多的相移,一般取带宽为其频率的1/4-1/5,我们取1/4为8K。
分两种情况:
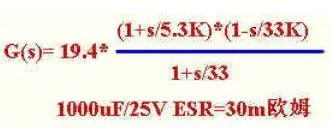
A)输出电容ESR较大

输出滤波电容的内阻比较大,自身阻容形成的零点比较低,这样在8K处的相位滞后比较小.Phanseangle=arctan(8/1.225)-arctan(8/0.033)-arctan(8/33)=--22度。
另外可看到在8K处增益曲线为水平,所以可以直接用单极点补偿,这样可满足-20dB/decade的曲线形状.省掉补偿部分的R2,C1。
设Rb为5.1K,则R1=[(12-2.5)/2.5]*Rb=19.4K
8K处功率部分的增益为-20*log(1225/33) 20*log19.4=-5.7dB因为带宽8K,即8K处0dB
所以8K处补偿放大器增益应为5.7dB,5.7-20*log(Fo/8)=0Fo为补偿放大器0dB增益频率Fo=1/(2*pi*R1C2)=15.42
C2=1/(2*pi*R1*15.42)=1/(2*3.14*19.4*15.42)=0.53nF相位裕度:180-22-90=68度
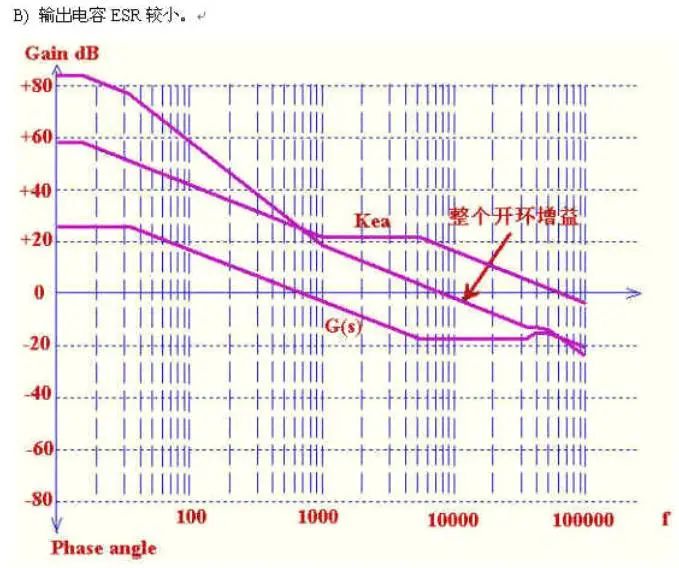
输出滤波电容的内阻比较大,自身阻容形成的零点比较高,这样在8K处的相位滞后比较大。
Phanseangle=arctan(8/5.3)-arctan(8/0.033)-arctan(8/33)=-47度
如果还用单极点补偿,则带宽处相位裕量为180-90-47=43度,偏小.用2型补偿来提升。
三个点的选取,第一个极点在原点,第一的零点一般取在带宽的1/5左右,这样在带宽处提升相位78度左右,此零点越低,相位提升越明显,但太低了就降低了低频增益,使输出调整率降低,此处我们取1.6K.第二个极点的选取一般是用来抵消ESR零点或RHZ零点引起的增益升高,保证增益裕度.我们用它来抵消ESR零点,使带宽处保持-20db/10decade的形状,我们取ESR零点频率5.3K。
数值计算:
8K处功率部分的增益为-20*log(5300/33) 20*log19.4=-18dB
因为带宽8K,即最后合成增益曲线8K处0dB
所以8K处补偿放大器增益应为18dB,5.3K处增益=18 20log(8/5.3)=21.6dB水平部分增益=20logR2/R1=21.6
推出R2=12*R1=233Kfp2=1/2*pi*R2C2
推出C2=1/(2*3.14*233K*5.4K)=127pF.fz1=1/2*pi*R2C1
推出C1=1/(2*3.14*233K*1.6K)=0.427nF.
相位
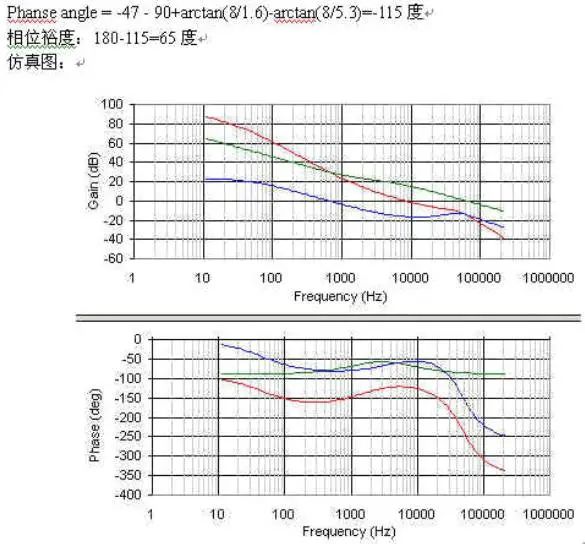

fo为LC谐振频率,注意Q值并不是用的计算值,而是经验值,因为计算的Q无法考虑LC串联回路的损耗(相当于电阻),包括电容ESR,二极管等效内阻,漏感和绕组电阻及趋附效应等.在实际电路中Q值几乎不可能大于4—5。
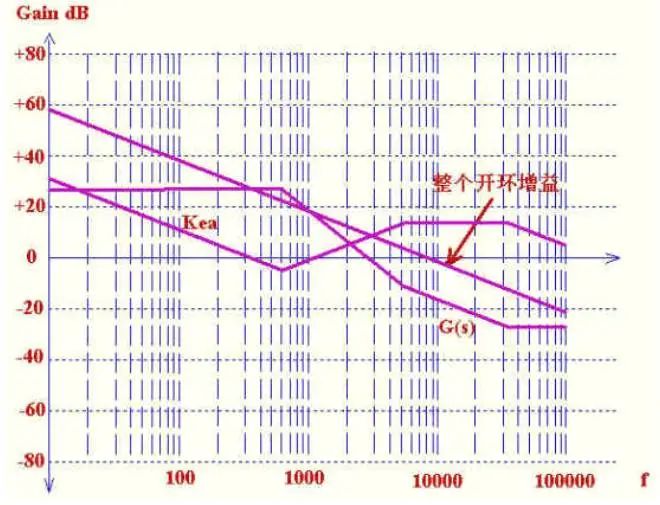
由于输出有LC谐振,在谐振点相位变动很剧烈,会很快接近180度,所以需要用3型补偿放大器来提升相位.其零,极点放置原则是这样的,在原点有一极点来提升低频增益,在双极点处放置两个零点,这样在谐振点的相位为-90 (-90) 45 45=-90.在输出电容的ESR处放一极点,来抵消ESR的影响,在RHZ处放一极点来抵消RHZ引起的高频增益上升。
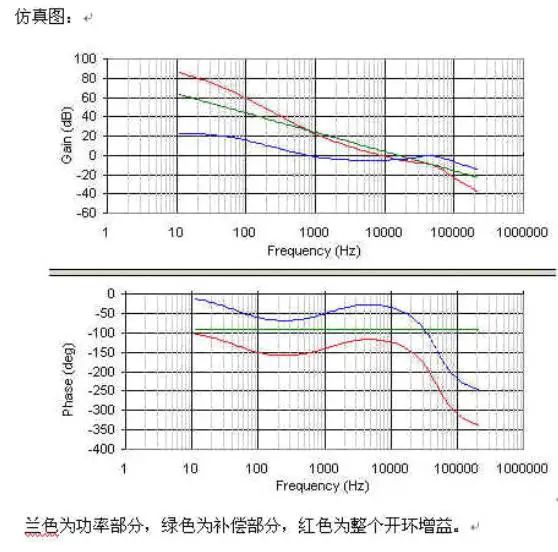
元件数值计算,为方便我们把3型补偿的图在重画一下。
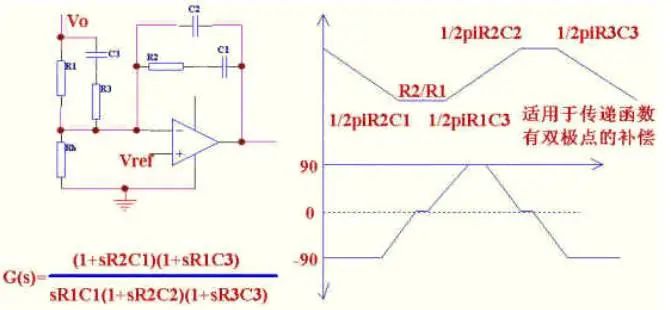

蓝色为功率部分,绿色为补偿部分,红色为整个开环增益。
如果相位裕量不够时,可适当把两个零点位置提前,也可把第一可极点位置放后一点。
同样假设光耦CTR=1,如果用CTR大的光耦,或加有其他放大时,如同时用IC的内部运放,只需要在波得图上加一个直流增益后,再设计补偿部分即可.这时要求把IC内部运放配置为比例放大器,如果再在内部运放加补偿,就稍微麻烦一点,在图上再加一条补偿线结束。
我想大家看完后即使不会计算,出问题时也应该知道改哪里。















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









