







 本文手把手教你使用Python将Excel数据导入数据库。首先安装Python环境和相关库,接着通过openpyxl读取Excel,再利用pymysql连接数据库并执行SQL操作,实现数据入库。
本文手把手教你使用Python将Excel数据导入数据库。首先安装Python环境和相关库,接着通过openpyxl读取Excel,再利用pymysql连接数据库并执行SQL操作,实现数据入库。
背景:
- 有一批数据业务只能线excel的方式给
- excel与数据表结构不一致
当然可以直接通过navicat导入excel数据,but、、python也得用起来呀
let us go ~
准备:
- 编辑器 - 写代码得有开发工具啊,pyCharm也行、本文
idea 2020.3 - python 解释器 - 直接通过idea插件方式安装即可
- 导包 - 需要啥导啥
步骤:
- 1 idea 安装python 插件
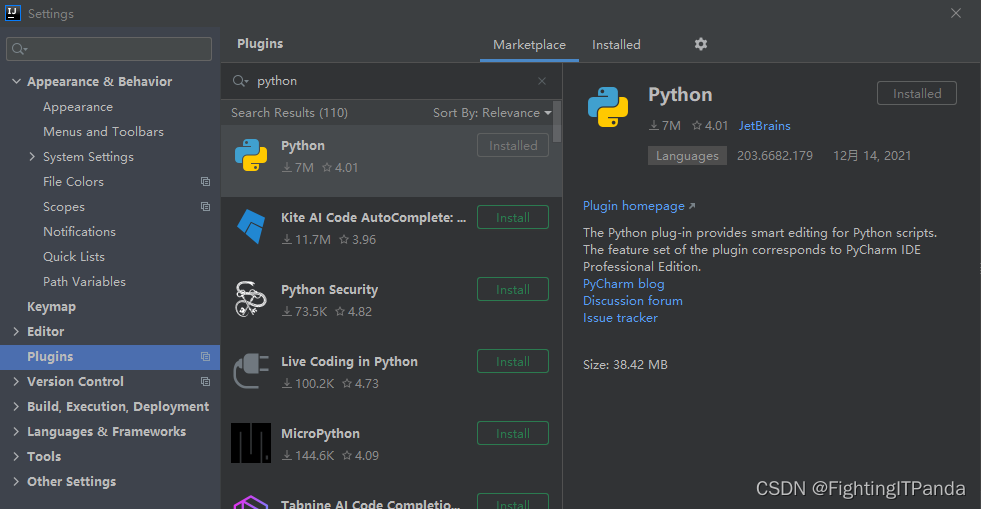
File -> Settings -> plugins -> Marketplace
输入 python -> install 安装完重启idea
- 2、创建python项目
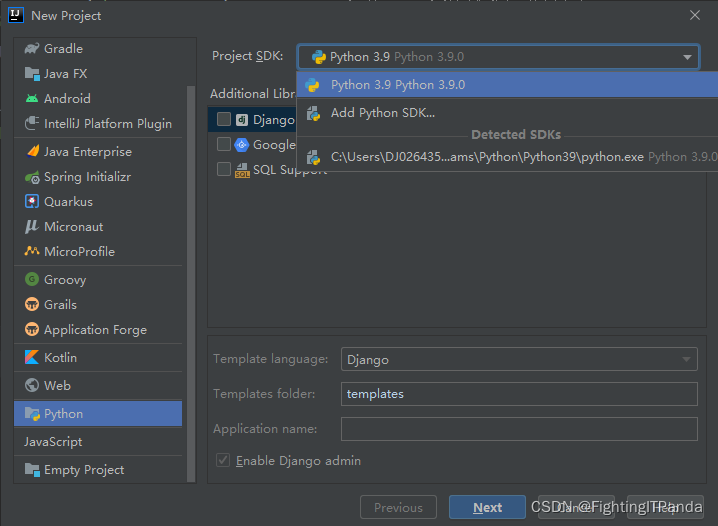
File -> New -> Project…
此时发现左侧已经有Python选项了,
Project SDK默认我们刚安装的Python最新版本,自己手动安装在本地的可以通过Add Python SDK 选择
然后一路下一步就可以了
- 3、 环境验证
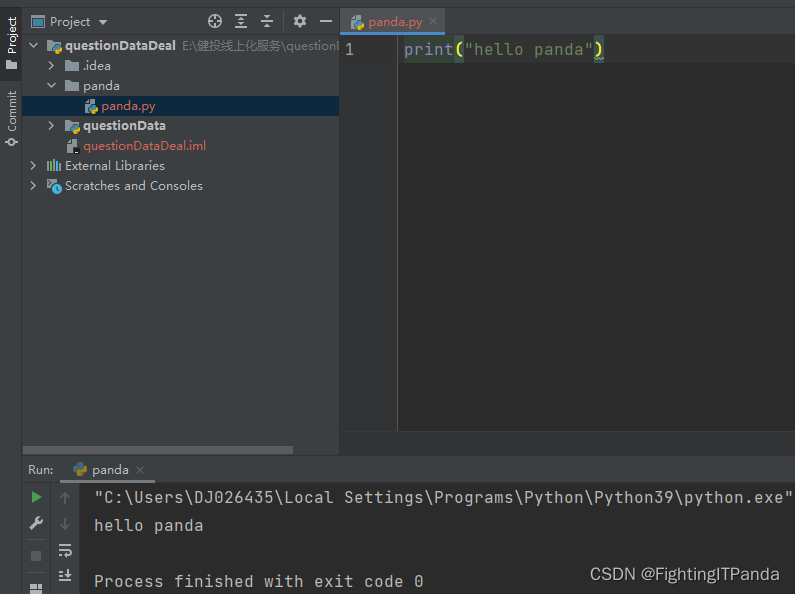
新建个文件(后缀为.py)
随便写点啥,打印一下
打印成功、环境已经准备完毕
- 4、 建包、搭架子
我们的任务大致分为两步
1、读excel
2、写DB
读 Excel:
- 新建一个module (概念同idea一致)
- 安装openpyxl - 我们通过openpyxl处理excel
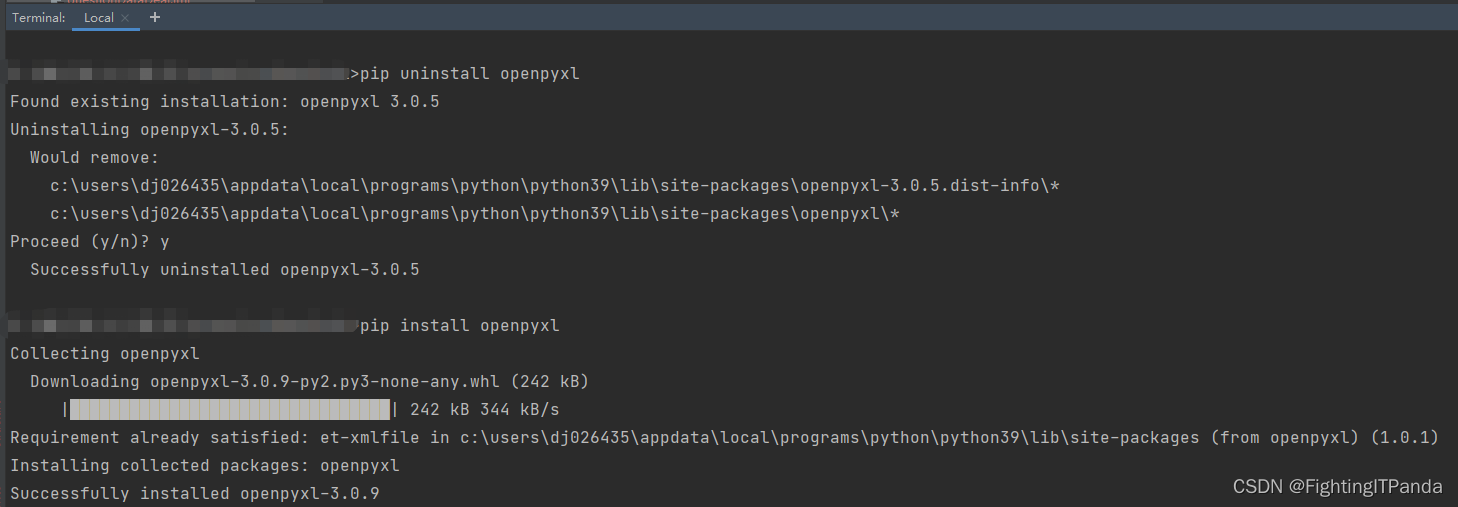
打开终端
输入pip install openpyxl,回撤
会有下载进度条提示,(我是先卸载了,重新安装的)
- 读excel demo
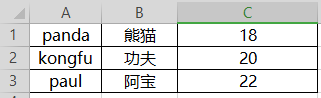
from openpyxl import load_workbook
# 读当前目录下excel
excel = load_workbook('./panda.xlsx')
# ['Sheet1', 'Sheet2', 'Sheet3']
tables = excel.sheetnames
# 表头
table = excel[tables[0]]
# 列数
columns = table.max_column
# 行数
rows = table.max_row
# 逐行读excel
for i in range(1, rows+1):
# 行数组
row = []
# 第一列
column1 = table.cell(row=i, column=1).value
row.append 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









