 深度学习驱动的汉字生成:OCFGNet模型解析
深度学习驱动的汉字生成:OCFGNet模型解析







 本文介绍了基于深度学习的中文字库扩充模型OCFGNet,该模型利用双编码器分别提取汉字内容和风格特征,并结合解码器生成图像。通过引入SSIM提升生成图像质量,解决VAE的模糊问题。模型包含VAE、GAN组件,以及多种损失函数,用于内容保持、风格转换和循环一致性的保证。尽管模型结构复杂,但实验结果显示效果良好。
本文介绍了基于深度学习的中文字库扩充模型OCFGNet,该模型利用双编码器分别提取汉字内容和风格特征,并结合解码器生成图像。通过引入SSIM提升生成图像质量,解决VAE的模糊问题。模型包含VAE、GAN组件,以及多种损失函数,用于内容保持、风格转换和循环一致性的保证。尽管模型结构复杂,但实验结果显示效果良好。
关键词
VAE,图像,汉字,GAN
一、背景
1.汉字生成收到越来越多的人关注,汉字字体库难以建立。
2.GAN网络的兴起,为汉字生成提供了一种有效的途径。
3.汉字的复杂性和多样性导致传统的笔画提取不够准确。
二、相关工作
1.将汉字的生成过程当做一个图像到图像的翻译问题。
2.zi2zi等采用GAN网络的方法,生成效果好,但是存在模型坍塌等问题。
问题:现有的方法只能在已有的风格之间转换,这篇论文提出了一种新的方法,可以生成新的论文。
3.目前主流汉字生成思想都是提取汉字骨架,然后进行骨架迁移,最后文字渲染,具体可以看一下AAAI2020浙大的工作。
三、论文解读
1.论文介绍
论文提出了一种基于深度学习的中文字库扩充模型OCFGNet。包含了两个双编码生成器,三个解码器和一个补丁鉴别器。
双编码器分别提取内容特征和风格特征,然后将两种编码拼接输入解码器,解码器将其输出成图像。
1.1表达定义
X表示由J个不同字符和I个不同字体组成的中文字体数据集。上标表示字体,下标表示字符。
1.2具体结构
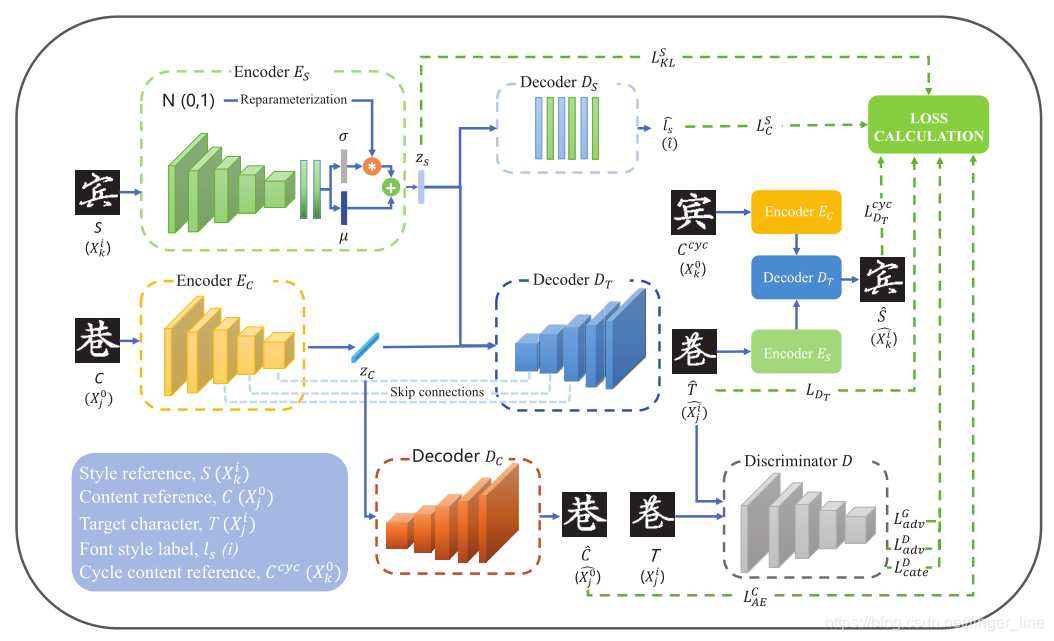
从流程结构图中,我们可以知道具体模型结构。
1.Encoder Es参考VAE操作,将图片输入进行编码,输出高斯分布的方差和均值,为了方便反向传播,使用reparameterization trick,输出为一组方差和均值。VAE可以看这个博主写的,很详细!
2.Encoder Ec与Decoder Dc 提前预训练好,保证内容编码可以精确表达图片中的字体内容。
3.将下采样的Zc和Zs拼接,传给Dt,生成带有目标风格的字体。
4.Patch-level Discriminator鉴别生成图片的真假,同时进行风格分类。
5.Ds对Zs风格分类。
1.3损失函数
1.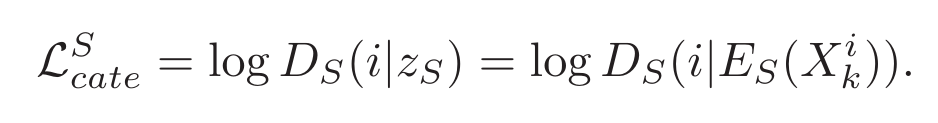
Ds对Zs的分类损失
2.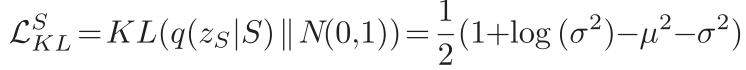
VAE中的KL损失,度量概率与正太分布的距离
3.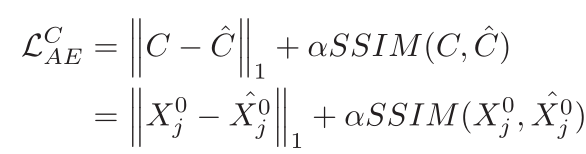
内容误差和SSIM结构相似性
4.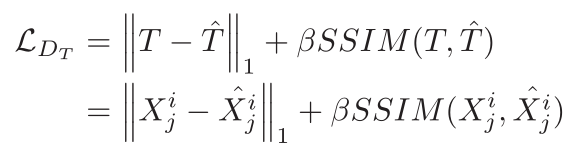
生成图片误差和SSIM结构相似性
5.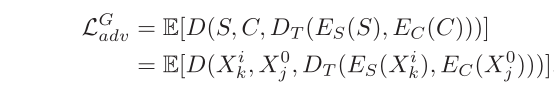
生成器损失,即Es损失
6.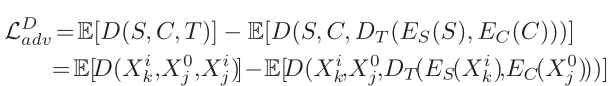
D的损失。这个损失函数写的不对,我觉得把两个损失相加求MAX趋向于2比较好。
5和6可以成为生成对抗损失,GAN网络和VAE很接近。
7.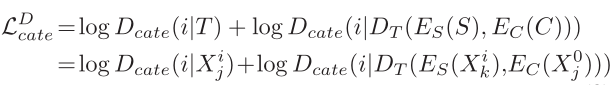
D的分类损失
8.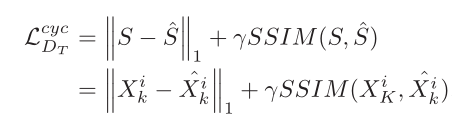
循环一致损失,文章在文中提出了这个损失,在图中也划出,但是对此部件没有相应的文字描述,只能通过图来看。不过这个地方借用了CycleGAN的思想。
总结
这篇论文使用的方法都是存在的,模型显得组合叠加,不过引入了SSIM确实是一大亮点,解决了VAE图像模糊问题,实验结果看起来很不错,要是开源就好了。
我的思考
1.Ls这个参数我在图中没有看见从哪里输入,但是作者在算法流程的输入中提到了。
2.Es在样本少的情况下应该训练不出来,也就是说数据集还是很大的。
3.Cycle的结构作者没有详细的说明,只能根据图所画的来猜测所做的工作。
4.损失函数写的不是很好,没有交代清楚。
5.标题写的很大,但是具体没有做标题的事,打了个擦边球…

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









