







目录
redis基本操作
redis默认有16个库(0-15),这个可以在配置文件中修改的,默认使用第一个db0。
- 切换数据库 ,
select 0; - 存储值因为是key-value形式,存储值用 :
set key name ;取值get key; - 清空所有数据库
flushall;清空当前数据库flushdb; - 查看所有键
keys *;获取键总数keys *; - 重命名键
rename key key2;给key设置过期时间expire key 10 - 查看键是否存在
exists key;删除键del key;查看类型type key - 命令大全: http://redisdoc.com/index.html
安装文档 : https://gper.club/articles/7e7e7f7ff2g51gc9g68
官网介绍:https://redis.io/topics/introduction
中文官网:http://www.redis.cn
Redis数据类型使用及场景
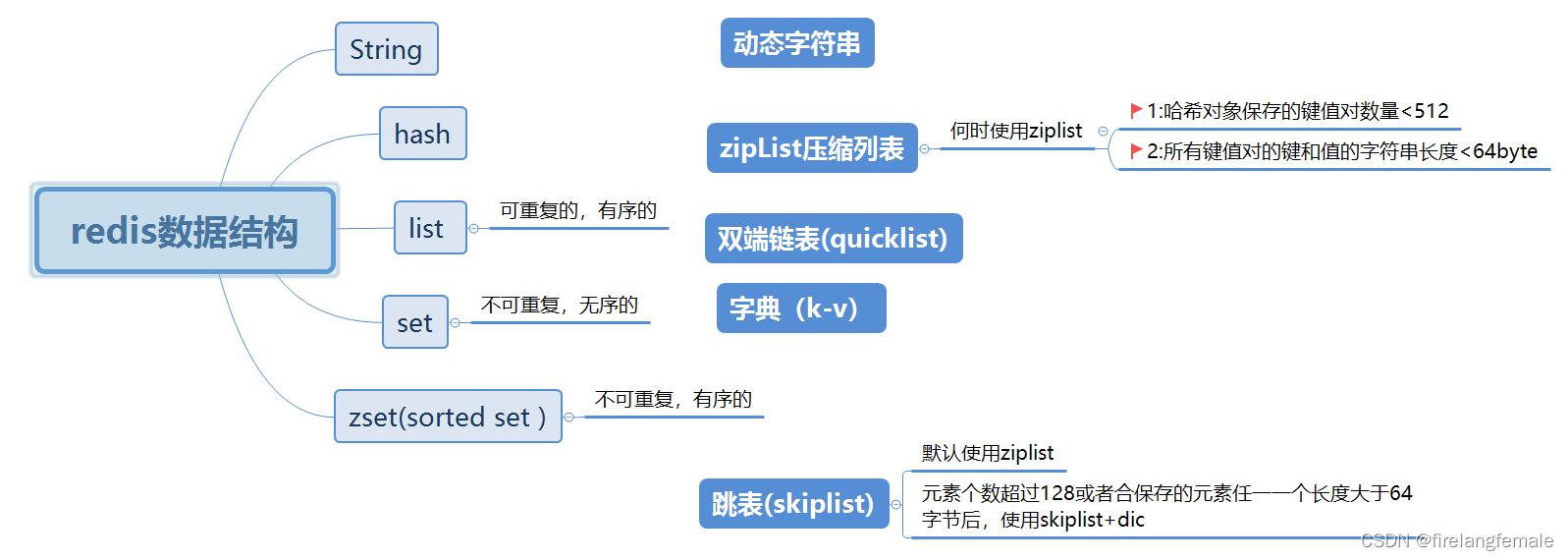
一:String
Redis提供的String类型,底层有三种不同的编码格式,对应的是redisObject对象的encoding变量的取值变化。
基本操作
批量设置 mset key kname key2 kname2;批量获取mget key key2
获取长度strlen key;字符串追加内容append key aa
使用范围
缓存;计数器;限流;分布式锁;分布式id
底层编码(1:int 2:raw 3:embstr)
object encoding key 查看key的编码
- int,存储8个字节的长整型(long,2^63-1)。
- embstr, 代表embstr格式的SDS,存储小于44个字节的字符串。
- raw,存储大于44个字节的字符串。
二:Hash
hash底层实现结构是一个字典,key-file(value),实际file又是一个key-value结构,
基本操作
单个设置hset key small apple 批量设置hmset key long b big a short c
取值hget small ,hmget key long,big
获取key hkeys key 获取值hvals key
给某个键增加数量hincrby 大key 小key 添加数量
使用范围
缓存结构形数据
底层编码(1:zipList 2:hashTable)
当元素数量比较小的时候使用的是zipList结构存储结构,ziplist内部的entry节点是连续的内存空间,所以此时的hash是有序的;
1:哈希对象保存的键值对数量<512个;
2:所有键值对的健和值的字符串长度都<64byte(一个英文字母一个字 节)
redis.conf配置
hash-max-ziplist-value 64 // ziplist中最大能存放的值长度
hash-max-ziplist-entries 512 // ziplist中最多能存放的entry节 点数量
当数据到达一定阈值的时候底层编码会变成hashtable存储,此时对应数据也变成无序的,更改上面两个配置即可。
ziplist实现hash存储
将同一键值对的两个节点紧挨着保存,保存键的节点在前,保存 值的节点在后,新加入的键值对,放在压缩列表表尾
三:List(quickList)
list是一个有序的(按加入的顺序从左到右)可重复的数据结构。
基本操作
左边添加元素lpush queue a ;右边添加元素 rpush queue b
左右弹出一条 lpop queue ; rpop queue
取值 lrange queue 0 -1
使用范围
可以存储有序列表
底层编码
quicklist
是一个双向链表(数组加链表的结构),并且是一个ziplist的双向链表,也就是说quicklist的每个节点都是一个ziplist,将每一个ziplist视为一个quicklistNode,quicklist中还包含node的头节点、node的尾节点、node的数量、list的长度等信息。
优点是:即包含了数组的效果(单个node节点内数据查询效率高,节省空间),又包含了链表的效果(多个node之间互不干扰,增删成本低)。
四:Set (insert + hashTable)
无序的,不可重复 的集合
如果元素都是整型的话,就是有序的
基本操作
添加元素 sadd keyset a,b,c;取所有元素 smembers keyset
获取集合个数 scard keyset ; 查看元素是否存在 sismember keyset a
获取两个集合交集 sinter set1 set2;获取两个集合并集 sunion set1 set2
使用范围
可用于:抽奖,取交集并集差集,点赞,关注,签到等场景
底层编码
redis用insert 或 hashTable 存储set , 如果是整型用inset存储, 否则用hashTable(数组+链表)存储。
元素个数超过512 个就用hashTable存储,可配置。
set-max-intset-entries 512
五:Zset(Sorted set) (1:ziplist + 2:dict+skipList)
是一个有序的,不可重复的集合。每个set都有score,score相同时,按照key的ASCII码排序
基本操作
添加元素 zadd key score1 value1 score2 value2
从低到高取所有 zrange key 0 -1 从高到低取 zrevrange key 0 -1
给某元素加值 zincrby key value score 获取范围zrangebyscore key 10 20(数值范围围) 获取某元素的值 zscore key score获取范围个数 zcount key 10 20
使用范围
排行榜
底层编码
Zset 默认使用zipList 编码,在zipList内部按照score排序递增存储,
如果元素数量大于等于128个,或者任一member长度大于等于64字节,使用
skiplist+dict存储。
zset-max-ziplist-entries 128 //元素个数超过128,将用skiplist编码
zset-max-ziplist-value 64 // 集合保存的元素任一一个长度大于64字节用skiplist编码
redis 能存大key吗
只要不导致oom,就可以放, 但是不建议,大key会增大网络开销,redis单线程获取时会导致阻塞,会拖慢整个线程,并发高的时候整个redis可能会菪机。
如何排查big key redis里有指令
大key 要删除
redis快的原因
1:基于内存,不与磁盘交互
2:高效的数据结构:底层多种数据结构支持不同数据类型,使redis存储数据的时间的复杂度降到了最低
3:合理的数据编码;根据字符串的元素个数和长度匹配不同的编码格式
4:命令执行是单线程,减少了上下文cpu切换,减少耗时, 同时通信采用多路复用
5:lO多路复用,单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管
理多个I/O流
I/O多路复用
I/O :网络 I/O
多路:多个 TCP 连接
复用:共用一个线程或进程
多个客户端发送请求给redis服务器,最终服务器处理请求返回,面对大量请求,redis的I/O 多路复用同时监听多个套接字将这些事情推送到一个队列里,逐个被执行,最后返回结果给客户端。
发现这两篇写的不错可查阅:
https://www.jianshu.com/p/74071e9a7bd9
https://blog.csdn.net/qq_44377709/article/details/123123657














 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









