







现象
系统环境
- 操作系统:Microsoft Windows 10 家庭中文版 10.0.1904
- Python:Python 3.8.8
问题
如下图所示,利用python读取文件后,在对字符串进行处理时,会出现\ufeff字符。这对基于数据的下一步逻辑处理会产生影响。
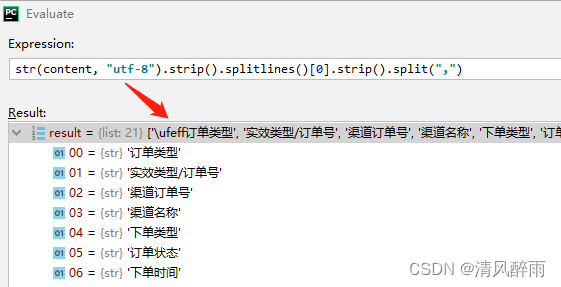
说明:上图中的
content是按照二进制流读取文件内容,是byte类型。因此,需要先对其进行解码,将byte转为str。
原因
产生该现象的原因是 UTF 的编码格式分为 UTF-8 和 UTF-8 with BOM,前者 UTF-8 是没有字节序的问题的,而后者 BOM 则表示 Byte Order Mark,是存在字节序的区分的,
解决办法
因此python在读取 UTF-8 with BOM 编码的文件时需要选择 UTF-8-sig 关键字指明编码格式。
with open("xxx.file", "r", encoding="utf-8-sig") as fp:
fp.read()
...
如何知道文件属于哪种编码
方法1
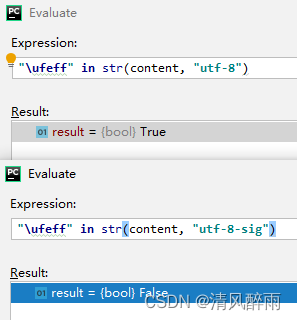
本文目前采用的是一种笨办法,即可按照 UTF-8 或 UTF-8 with BOM编码对文件进行读取,然后判断字符串里面是否存在关键字符\ufeff。
测试结果如下图所示,返回的结果是布尔类型。
方法2
可以通过chardet库自动对编码格式进行判断(该库一般是不需要单独安装的)。
示例代码如下:
import chardet
with open("xxx.file", "rb") as fp:
rawdata = fp.read()
encoding_format = chardet.detect(rawdata)["encoding"]
print(encoding_format )
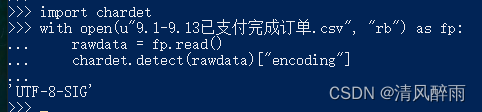
交互式命令行的运行结果如下图所示,在图中就可以发现所读取的文件为UTF-8-SIG编码。















 4246
4246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











