







Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person
Re-identificationWith Deep Mis-Ranking[1],2020年CVPR。文章提出了可迁移的,可控的,难以察觉的错误排名学习模型,来干扰ReID的ranking预测。首先文章设计了错排名loss(mis-ranking
loss function)损失函数专门来扰乱ReID的ranking,补充了目前基础的attacker模型。
由于需要提取对抗干扰的整体特征,文章设计了通过金字塔分型进行特征学习的多阶段网络架构,该模型在黑箱攻击中有极强的迁移性(transferability)。文章由于使用了可微分的多次采样,使得要攻击的目标像素数是可控的(controllable)。作者还设计了新的感知loss,来提高攻击图像的视觉质量,保证了攻击特征的难察觉性(inconspicuousness)。实验验证了模型的有效性,一度能让ReID模型表现从91.8%降至1.4%。
论文一览:

痛点
在深度学习大行其道的ReID领域,由于深度神经网络的脆弱性,使得ReID模型天然的容易受到攻击,让整个系统非常脆弱。因此检验ReID的鲁棒性比其他指标要更重要,不安全的ReID系统可能导致非常严重的后果——比如罪犯可能会使用对抗性攻击的伪装来欺骗系统。因此发现模型的薄弱环节,并且增强他们的鲁棒性就显得格外重要,而文章就做了这个事——文章能够分析出人体的那个部位在对抗攻击中最容易受到攻击,并引导ReID系统注意这些部位。
另一方面,和category classification,detection或者segmentation这些任务不同,现在流行的对抗攻击方法并不能直接适用于一个ranking问题。而且ReID图像数据的domain在不同的时候和不同的摄像机会产生变化,这就使得可以考虑施加跨数据集的黑箱攻击了。此外现有的对抗攻击方法通常具有人类可以感知的有缺陷的视觉品质,而文章做到了使这种攻击特征难以察觉(inconspicuous)
文章在一个SOTA AlignedReID模型进行攻击的Rank 10可视化,攻击后检索的图像均错误了。

模型
文章的模型框架如下图2,可以看到主要是一个GAN的结构,包括生成器generator g g g和判别器discriminator D D D。
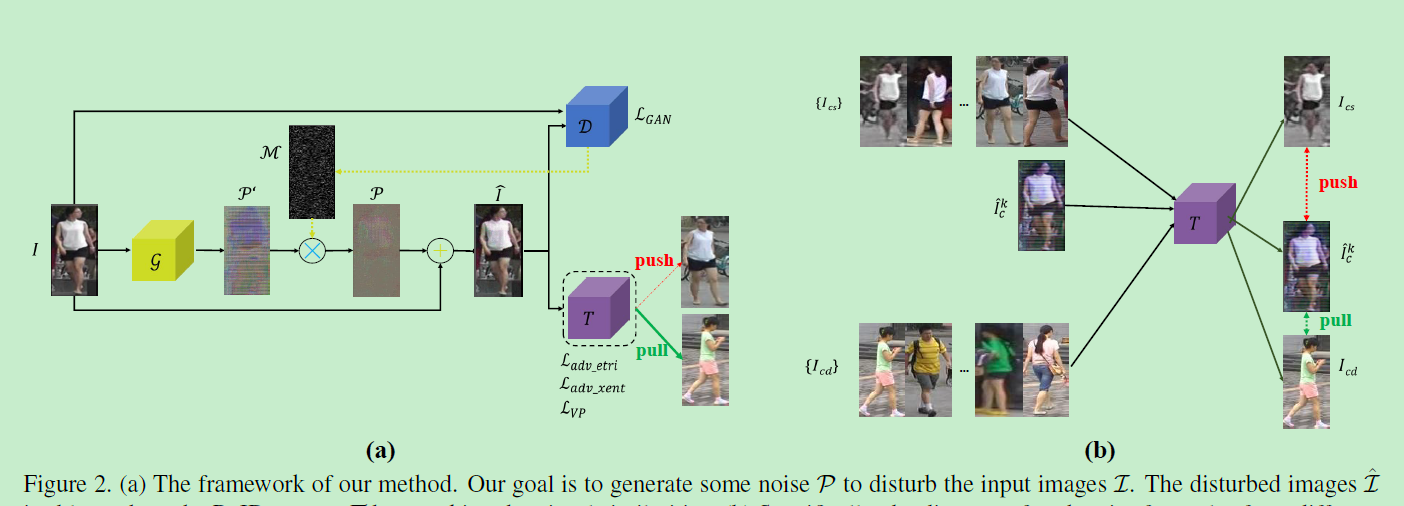
模型的总体目标就是使用generator去为每一张图片生成一个欺骗noise,通过施加noise可以得到对抗样本 I ^ \hat I I^,该样本能够欺骗ReID系统使其做出错误的判断。如图2(b),ReID模型 T T T,可能会觉得不同ID的人的相似度很高,反而觉得相同ID的人相似度很低。
文章提出的错排名损失函数如下:
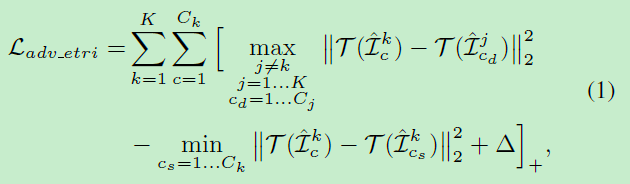
其中 I ^ c k \hat I_{c}^{k} I^ck是一个batch中第k个ID的第c张图片, c d c_{d} cd和 c s c_{s} cs不同(different)id和相同(same)id的样本, Δ \Delta Δ是margin。式1以triplet loss的形式攻击了ranking,将最容易区分的不同ID图像对的距离鼓励变小(容易误判的错误样本,让它更容易误判),而将最容易区分的同一ID图像对的距离鼓励变大(容易识别的正确样本,让它不同容易识别,这就相当于triplet loss的反向操作。
生成器generator g g g和判别器discriminator D D D用于特征学习,其中生成器使用ResNet50,对于判别器,作者提出了通过将特征金字塔化成不同层级的多阶段的网络架构用于表征学习,判别器 D D D结构如下图3所示。
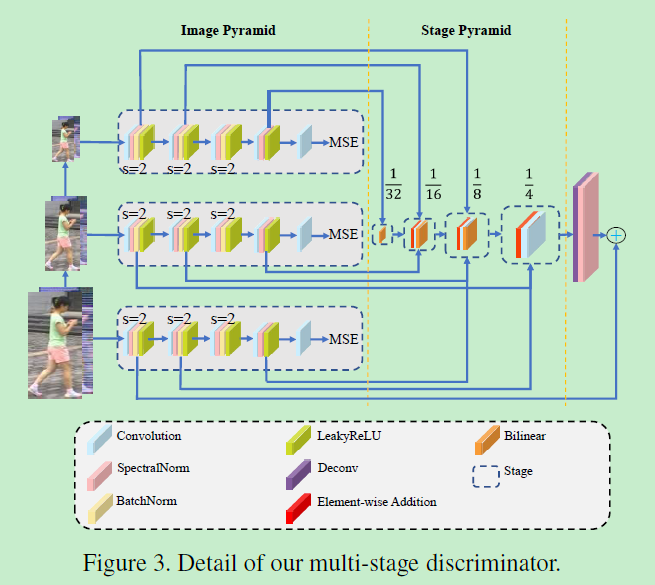
其包含了3个全卷积子网络,每个子网络包含了5个卷积,3个下采样和一些BN层。三个子网络的输入分别是原图像面积的
{
1
,
1
2
2
,
1
4
2
1, \frac{1}{2^{2}}, \frac{1}{4^{2}}
1,221,421}
。3个子网络得到的输出经过接下来的stage pyramid生成原图像的
{
1
32
,
1
16
,
1
8
,
1
4
\frac{1}{32}, \frac{1}{16}, \frac{1}{8}, \frac{1}{4}
321,161,81,41},这里用了上采样来提高图像的分辨率,用了conv减小了channel维数,经过对应元素相加和3x3conv之后,融合的特征传递到下一个stage。
为了使攻击难以察觉,文章从两个角度改进了现有的attacker,其一是控制被攻击的目标像素的数量。攻击是将攻击noise加到目标像素之中,noise像素和目标像素是需要attacker搜寻的,为了使搜索空间连续,文章放宽了对所有可能像素的像素选择,设计了Gumbel softmax:
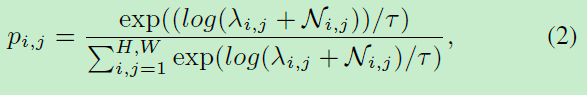
i,j是pixel的索引,H和W是feature map的高和宽, p i , j p_{i,j} pi,j为像素被选择的概率,其被softmax输出 λ i , j \lambda_{i,j} λi,j参数化了。 N i , j = − l o g ( − l o g ( U ) ) N_{i,j}=-log(-log(U)) Ni,j=−log(−log(U))是采样于Gumbel分布 U ∼ U n i f o r m ( 0 , 1 ) U \sim Uniform(0,1) U∼Uniform(0,1)位于(i,j)的随机变量。 τ \tau τ为温度参数,用于在A逐渐减小到零时软化从均匀分布到分类分布的过渡。
被攻击的目标像素mask由下式决定:
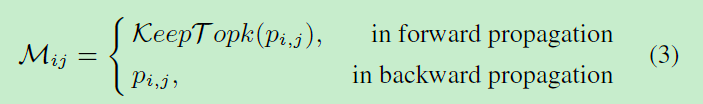
其中KeepTopk是一种函数,通过该函数,在前向传播过程中,具有最高概率pi,j的前k个像素将保留在M中,而其他像素被丢弃。前向和反向传播的差异保证了可区分性。通过乘mask M和noise P ′ P' P′可以得到最终的包含可控数量的像素P,可见图2(a).最后P与原图像相加得到被攻击的图像。
为了提高视觉质量文章有感知loss
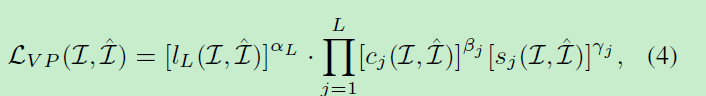
其中 c j c_{j} cj和 s j s_{j} sj分别是第j个标度的对比比较和结构比较的量度,可以通过:
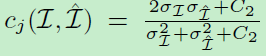
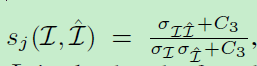
计算得到。 σ \sigma σ是方差/协方差。 α L \alpha_{L} αL, β j \beta_{j} βj和 γ j \gamma_{j} γj是权重因子,来分配不同部分的权重。得益于感知loss,高数值的攻击还能够保持难以察觉的图像质量。
除了错排序loss和感知loss,文章还有两个附加loss,包括错分类loss(misclassification
loss)和GAN loss。错分类loss为:
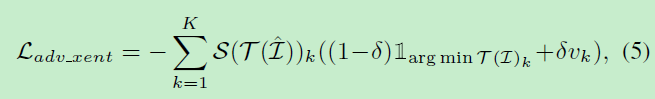
其中S为log-softmax函数,K是ID总人数,V为平滑正则化且 v k = 1 K − 1 v_{k}=\frac{1}{K-1} vk=K−11(当 v k v_{k} vk不是ground truth),当 v k v_{k} vk是ground truth时为0。
判别器D应该想办法从对抗样本中分辨真实图像,则有GAN loss为:
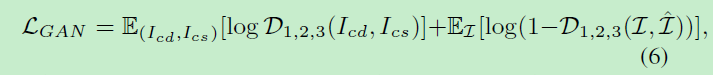
所有总的loss有:
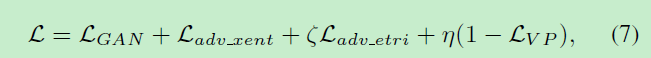
其中 ζ \zeta ζ和 η \eta η是权重因子。
实验
文章在不同数据集(market1501,Duke,CUHK03),使用不同模型,和其他攻击方法的对比:
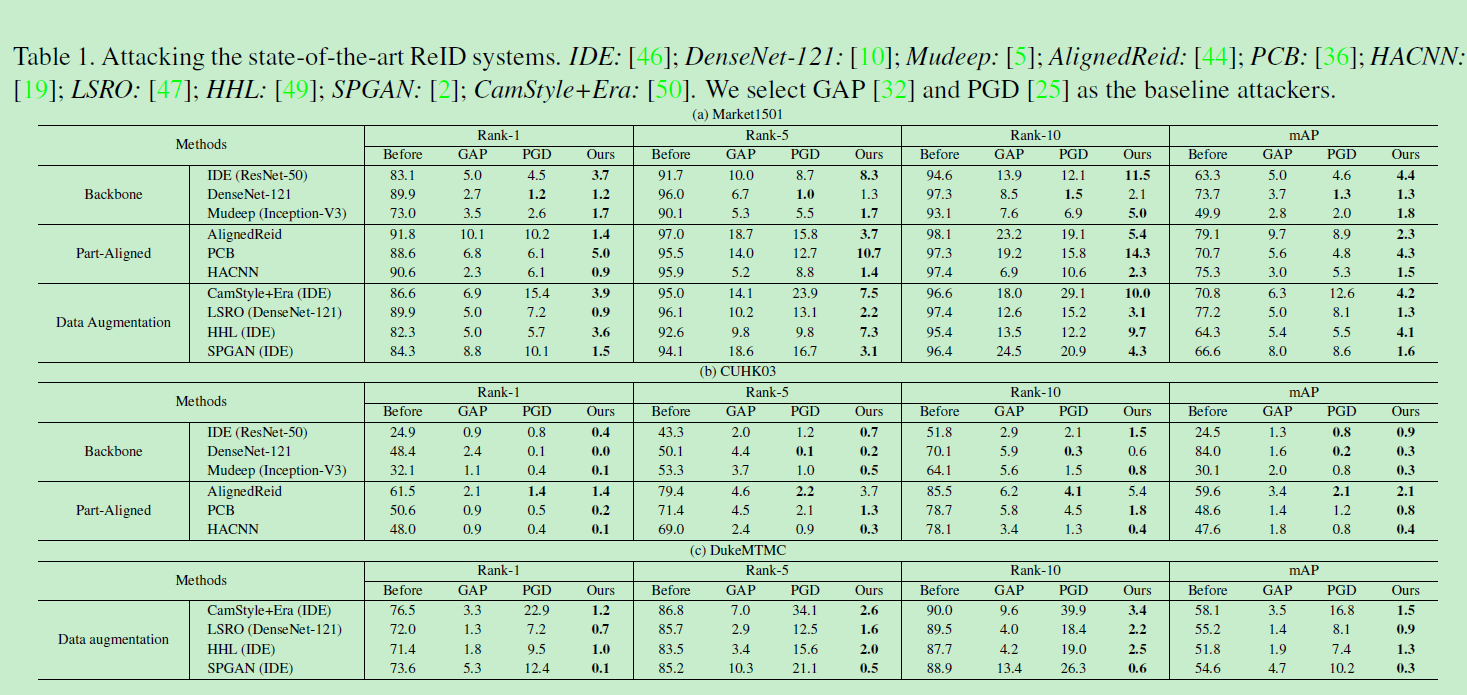
可以看到本文的方法总体上是使模型准确率下降最多的。
不同条件的分离实验对比如下:
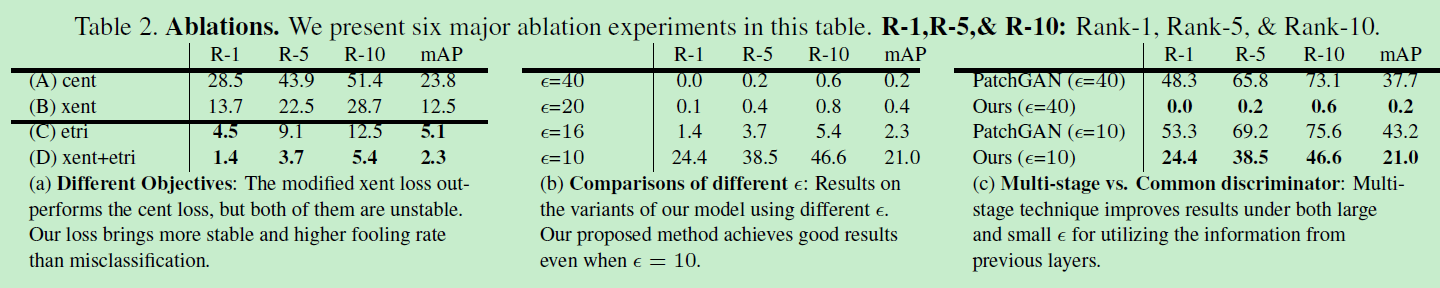
跨数据集和跨模型的对比

对抗点比例的分离实验:
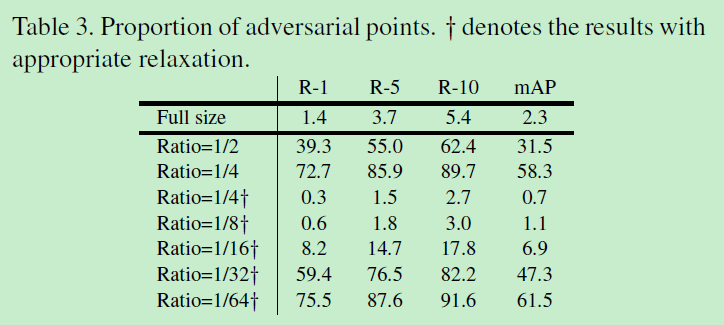
习得的多次采样和其他噪声以及随机位置的对比

不同方法下的图像质量的可视化

如下图右为market上所有query的平均图像,下图右为为对抗点的分布,颜色温度越高被选择的概率就越高。

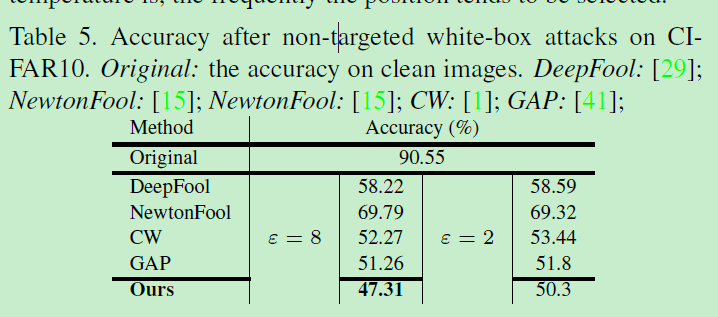
在CIFAR10的白盒攻击对比:
AlignedReID上的rank10可视化如下:

可以看到使用本文方法攻击之后rank10全部错分类了。
攻击noise可视化:

不同ε下的被攻击样本实例

问题
他们提供在arxiv的pdf让人很崩溃/(ㄒoㄒ)/~~。
‘(Introduction段3最后一句)In summary, developing adversarial attackers to attack ReID is desirable, although no work has been done before.’
我发现在他们之前还有一篇19年的文章做了attack[2]
参考文献
[1] Wang H, Wang G, Li Y, et al. Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 342-351.
[2] Bai S, Li Y, Zhou Y, et al. Metric Attack and Defense for Person Re-identification[J]. arXiv: Computer Vision and Pattern Recognition, 2019.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











