







一 Lucene简介
Lucene
是Apache软件基金会Jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene
可以对任何的数据做索引和搜索。Lucene不管数据源是什么格式,只要它能被转化为文字的形式,就可以被Lucene所分析和利用。也就是说不管是Word、Html、PDF还是其它什么形式的文件只要你可以从中抽取出文字形式的内容,就可以被Lucene所用,就可以用Lucene对它们进行索引和搜索。
Lucene
作为一个全文检索引擎,具有如下突出的优点:
1.
索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
2.
在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
3.
优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
4.
设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
5.
已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
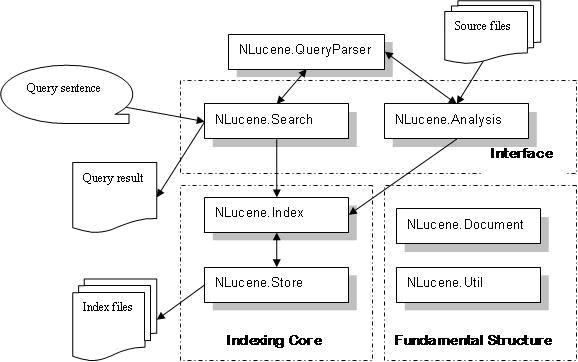
NLucene
是Lucene在.Net环境中的实现,其基本的原理和架构都是一致的,体系结构如下图:
1.
NLucene.Search:
搜索模块,根据查询条件,检索得到结果;
2.
NLucene.Index:
索引模块,负责索引的建立、删除等;
3.
NLucene.Analysis:
语言分析器,主要用于分词,支持各种语言主要是扩展此类;
4.
NLucene.QueryParser:
查询分析器,实现查询关键词间的运算,如与、或、非等;
5.
NLucene.Document:
索引存储的文档结构,类似与关系型数据库的表结构;
6.
NLucene.Store:
索引数据存储模块,主要包括一些底层的I/O操作;
7.
NLucene.Util:
一些公用的数据结构。
二 建立索引和搜索的代码示例
public class NluceneTester
{
private const string INDEX_DIR = @"E:/Materials/OpenSource/NLUCENE/nluceneTest/IndexFile";
public static void IndexFile()
{
try
{
IndexWriter writer = new IndexWriter(INDEX_DIR, new StandardAnalyzer(), true);
System.Console.Out.WriteLine("Indexing to directory '" + INDEX_DIR + "'...");
IndexDocs(writer);
System.Console.Out.WriteLine("Optimizing...");
writer.Optimize();
writer.Close();
}
catch (System.IO.IOException e)
{
System.Console.Out.WriteLine(" caught a " + e.GetType() + "/n with message: " + e.Message);
}
}
private static void IndexDocs(IndexWriter writer)
{
try
{
TextReader reader = File.OpenText(@"E:/Materials/OpenSource/NLUCENE/nluceneTest/config.txt");
Document doc1 = new Document();
doc1.Add(new Field("Features", "bearing bolt metal desk", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc1.Add(new Field("Common1", "path file index", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc1.Add(new Field("Common2", "patho fileo indexo", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc1.Add(new Field("Common3", "pathoo fileoo indexoo", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc1.Add(new Field("Name", "doc1", Field.Store.YES, Field.Index.UN_TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
Field contentField = new Field("Content", reader, Field.TermVector.WITH_POSITIONS_OFFSETS);
doc1.Add(contentField);
writer.AddDocument(doc1);
reader.Close();
reader = File.OpenText(@"E:/Materials/OpenSource/NLUCENE/nluceneTest/config.txt");
Document doc2 = new Document();
doc2.Add(new Field("Features", "bearing window door desk", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc2.Add(new Field("Common1", "debug data (1982)", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc2.Add(new Field("Common2", "debugoo data (tool))))", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc2.Add(new Field("Common3", "debugo datao toolo", Field.Store.YES, Field.Index.TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
doc2.Add(new Field("Name", "doc2", Field.Store.YES, Field.Index.UN_TOKENIZED, Field.TermVector.WITH_POSITIONS_OFFSETS));
//doc2.Add(new Field("Content", reader, Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(doc2);
reader.Close();
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
}
public static void Search()
{
string searchValue = "data (tool)";
string filterValue = "(bearing AND bolt) OR (bearing)";
StandardAnalyzer analyzer = new StandardAnalyzer();
string[] commonFields = new string[] { "Common1", "Common2", "Common3", "Content" };
//
特别注意Query searchQuery = MultiFieldQueryParser.Parse(searchValue, commonFields, occurs, 、、analyzer)
//
与下面构造的查询逻辑的区别;
//
QueryParser searchQueryParser = new MultiFieldQueryParser(commonFields, analyzer);
Query searchQuery = searchQueryParser.Parse(searchValue);
string[] filterFields = new string[]{"Features"};
QueryParser filterQueryParser = new MultiFieldQueryParser(filterFields, analyzer);
Query filterQuery = filterQueryParser.Parse(filterValue);
BooleanQuery lastQuerty = new BooleanQuery();
lastQuerty.Add(searchQuery, BooleanClause.Occur.MUST);
lastQuerty.Add(filterQuery, BooleanClause.Occur.MUST);
IndexReader indexReader = IndexReader.Open(INDEX_DIR);
Searcher searcher = new IndexSearcher(indexReader);
//
利用搜索模块进行全文搜索.
//
Hits results = searcher.Search(searchQuery);
//
调用Lucene的Hight模块对匹配的字符高亮显示.
//
Query minquery = searchQuery.Rewrite(indexReader);
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter("<b>", "</b>");
for (int i = 0; i < results.Length(); ++i)
{
TokenStream tokenstream = null;
Highlighter highlighter = new Highlighter(formatter, new QueryScorer(minquery));
Fragmenter textfragmenter = new SimpleFragmenter(5);
highlighter.SetTextFragmenter(textfragmenter);
//
获得当前结果中“Common2”Field中所有Token的位置偏移量.
//
TermPositionVector tpv = (TermPositionVector)indexReader.GetTermFreqVector(results.Id(i), "Common2");
if (null == tpv)
return;
tokenstream = TokenSources.GetTokenStream(tpv);
//
对Field“Common2”中的匹配字段加上高亮格式.改函数内部利用之前的Query条件又搜索了一遍.
//
string temp = highlighter.GetBestFragments(tokenstream, results.Doc(i).Get("Common2"), 2, "...");
Console.WriteLine(temp);
}
searcher.Close();
indexReader.Close();
}
}















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









