







 本文介绍如何通过Python脚本批量删除B站动态评论,提供两种方法:一是逐条定位后手动操作,二是使用Fiddler抓包自动化处理。详细步骤包括获取评论URL、填写Cookie和表单参数,以及处理删除成功与失败的记录。
本文介绍如何通过Python脚本批量删除B站动态评论,提供两种方法:一是逐条定位后手动操作,二是使用Fiddler抓包自动化处理。详细步骤包括获取评论URL、填写Cookie和表单参数,以及处理删除成功与失败的记录。
上篇文章爬取了B站数据,目的是删除自己的评论,具体在前言有说。现在得到了评论,该怎么删除(仅限自己的评论)?
方法一
在存放评论的文件夹内,运行以下代码,会得到所有要删除的评论的URL,存在当前文件夹内的txt文件中。若你是视频的评论,请自行修改get_url()中生成url的代码。
import os
import csv
import re
dir_path=os.path.abspath(os.path.dirname(__file__))
delete_comment_url_list=[] # 所有要删除的评论的URL
def input_mid(): # 输入帐号ID
while True:
mid=input('请输入你的帐号ID,是一串数字,可以在个人空间的URL中看到,或个人空间右侧的UID:')
pattern=re.compile(r'\D+') # 非数字内容至少出现一次
try:
result=pattern.search(mid).group()
except AttributeError: # 没有匹配到非数字内容,说明输入格式正确,所以终止循环
break
except:
raise Exception('发生了未捕获的异常')
if result:
print('无效的帐号ID,请重新输入')
return mid
def get_dynamic_id(file_name): # 从csv文件名中提取dynamic_id
temp_str=file_name.split('ID')[1]
pattern=re.compile(r'\D{1}') # 只匹配一次,即第一个非数字字符
result=pattern.search(temp_str).group() # ID后面的第一个非数字字符
dynamic_id=temp_str.split(result,1)[0] # ID这两个字符已去掉,ID后第一个字符是数字,从这个数字开始,到第一个非数字字符结束(不含这个非数字字符),就是dynamic_id
return dynamic_id
def get_url(mid): # 生成需要删除的评论的URL
file_list=os.listdir(dir_path)
for file_name in file_list:
file_path=dir_path+'/'+file_name
if (file_name[-3:] in ['csv','CSV']) and (os.path.isfile(file_path)):
with open(file_path,'r',newline='',encoding='utf-8') as f:
reader=csv.DictReader(f) # 将每行中的信息映射到一个OrderedDict。省略fieldnames参数时,键是csv文件的标题
for row in reader: # row是当前行的内容
if row['mid']==mid:
dynamic_id=get_dynamic_id(file_name)
url='https://t.bilibili.com/'+dynamic_id+'#reply'+row['rpid']
delete_comment_url_list.append(url)
def save_data(): # 每行写入一个URL,复制的代理IP池.py
file_path=dir_path+'/'+'delete_bilibili_comment_url.txt'
with open(file_path,'w',encoding='utf-8') as f:
f.write('') # 由于实际写入时是追加,所以每次重新运行时需先清空旧数据
with open(file_path,'a',encoding='utf-8') as f:
for i in delete_comment_url_list:
f.write(i+'\n')
print('数据已保存到本地')
if __name__=='__main__':
mid=input_mid()
get_url(mid)
save_data()链接示例(针对动态,不过视频也是以#reply+评论ID拼接)
https://t.bilibili.com/56764707xxxxxxxxxx#reply53xxxxxxxx打开这个txt,访问里面的链接,就能定位到自己的评论。 如果没有定位到,将页面滚动到底部,手动切换几次页码,如图,再在浏览器地址栏按回车(我没试刷新页面管不管用),这样多试几次,就能定位到自己的评论,然后点击旁边的三个点,删除。

方法二
如果要删除的评论很多,方法一就不合适,太慢了。
先手动删除一条评论,用fiddler抓包,根据URL和参数写出代码,自动批量删除。
代码中需要填上你的Cookie和抓到的表单参数csrf的值才能运行。
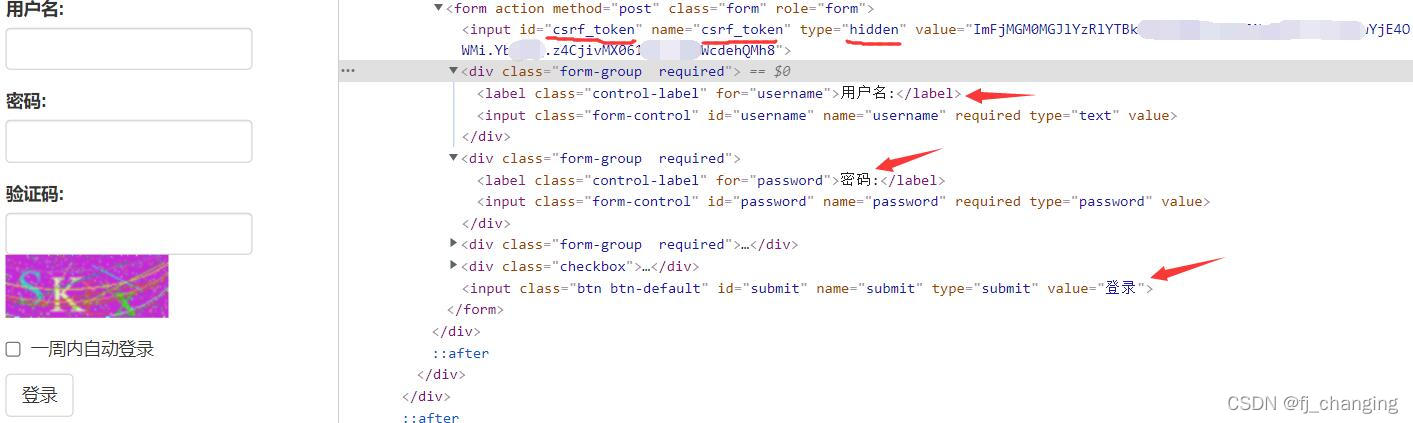
另外,csrf参数我猜应该和Flask或Django中的表单隐藏域类似,是表单中一个隐藏的html元素(如图),但我没在右键-检查中找到,有知道获取它的值的方法可以告诉我。
import requests
import os
import re
import csv
import time
url='https://api.bilibili.com/x/v2/reply/del'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43',
'Referer':'https://t.bilibili.com/',
'Cookie':"" # 需要Cookie,可在打开一条动态时用fiddler抓取
}
dir_path=os.path.abspath(os.path.dirname(__file__))
error_info_list=[] # 所有删除评论失败时错误日志需要的信息,列表中每个元素是字典,键是信息中参数名,值是参数值
OK_info_list=[] # 所有删除评论成功时日志需要的信息,列表中每个元素是字典,键是信息中参数名,值是参数值
def input_mid(): # 输入帐号ID
while True:
mid=input('请输入你的帐号ID,是一串数字,可以在个人空间的URL中看到,或个人空间右侧的UID:')
pattern=re.compile(r'\D+') # 非数字内容至少出现一次
try:
result=pattern.search(mid).group()
except AttributeError: # 没有匹配到非数字内容,说明输入格式正确,所以终止循环
break
except:
raise Exception('发生了未捕获的异常')
if result:
print('无效的帐号ID,请重新输入')
return mid
def get_dynamic_id_and_oid_and_type1(file_name): # 获取dynamic_id和oid和type1
temp_list=file_name.split(',')
dynamic_id=temp_list[0].split('ID')[1]
oid=temp_list[1].split('oid')[1]
temp_str_for_type=temp_list[2].split('type')[1]
pattern=re.compile(r'\D{1}')
result=pattern.search(temp_str_for_type).group()
type1=temp_str_for_type.split(result,1)[0] # 和爬取评论的代码中type_in_url_for_get_comment是同一个值
return dynamic_id, oid, type1
def get_rpid(file_path,mid): # 获取当前动态中指定用户的所有评论ID
rpid_list=[] # 有些动态下,同一个人有多条评论,把它们的rpid存在列表中
with open(file_path,'r',newline='',encoding='utf-8') as f:
reader=csv.DictReader(f)
for row in reader:
if row['mid']==mid:
rpid_list.append(row['rpid'])
return rpid_list
def save_error_log(): # 删除失败时,保存日志
file_name='删除评论失败时错误日志.txt'
file_path=dir_path+'/'+file_name
# 每行写入一句日志
with open(file_path,'w',encoding='utf-8') as f:
f.write('') # 由于实际写入时是追加,所以每次重新运行时需先清空旧数据
with open(file_path,'a',encoding='utf-8') as f:
for error_info_dict in error_info_list:
t=f'删除B站动态ID{error_info_dict["dynamic_id"]}中评论ID{error_info_dict["rpid"]}时失败,对应的oid是{error_info_dict["oid"]},type是{error_info_dict["type1"]},服务端返回的json数据是{error_info_dict["text"]}'
f.write(t+'\n')
print('错误日志已保存到本地')
def save_OK_log(): # 记录已删除的评论信息
file_name='删除评论成功时日志.txt'
file_path=dir_path+'/'+file_name
# 每行写入一句日志
with open(file_path,'w',encoding='utf-8') as f:
f.write('') # 由于实际写入时是追加,所以每次重新运行时需先清空旧数据
with open(file_path,'a',encoding='utf-8') as f:
for OK_info_dict in OK_info_list:
t=f'已删除B站动态ID{OK_info_dict["dynamic_id"]}中评论ID{OK_info_dict["rpid"]},服务端返回的json数据是{OK_info_dict["text"]}'
f.write(t+'\n')
print('成功日志已保存到本地')
def delete_comment(file_name,file_path,mid): # 删除评论
# 若执行过程中因报错导致终止,则有一些评论已被删除,剩一些未删除;再次执行时,还会删除之前已删除的评论,B站仍然返回删除成功的json数据(手动构造含#reply的URL,访问时(按博客里方法一多试几次)无法定位到对应的评论,说明真的已被删除)。所以不影响最终结果,我就未适配这种情况(即下次删除前先自动剔除已删除的),只记录了删除成功的日志
dynamic_id, oid, type1=get_dynamic_id_and_oid_and_type1(file_name)
rpid_list=get_rpid(file_path,mid)
if len(rpid_list)>0: # 说明当前csv文件中有指定用户的评论
for rpid in rpid_list:
form_data={
'oid':oid,
'type':type1,
'jsonp':'jsonp',
'rpid':rpid,
'csrf':'' # 只要保持登录状态,无论是否关闭浏览器再重新打开,csrf的值不变。未测试退出帐号重新登录会不会变,若变,则手动构造含#reply的URL,访问后定位到评论并手动删除评论,期间用fiddler抓取表单数据。除了抓包,应该还能在前端代码中找到csrf的值,因一般提交表单时,input框附近有表单隐藏域,但我在这里没找到。
}
r=requests.post(url,headers=headers,data=form_data)
time.sleep(5)
result=r.json()
global request_count # main函数中已定义
request_count=request_count+1
code=result['code']
message=result['message']
ttl=result['ttl']
if not (code==0 and message=='0' and ttl==1): # 删除失败
error_info_dict={}
error_info_dict['dynamic_id']=dynamic_id
error_info_dict['oid']=oid
error_info_dict['type1']=type1
error_info_dict['rpid']=rpid
error_info_dict['text']=r.text # 传r.text就不用分别传code和message和ttl
error_info_list.append(error_info_dict)
print('删除失败,详情见本地错误日志文件(程序运行结束且非人为结束才生成)')
else: # 删除成功
OK_info_dict={}
OK_info_dict['dynamic_id']=dynamic_id
OK_info_dict['rpid']=rpid
OK_info_dict['text']=r.text # 传r.text就不用分别传code和message和ttl
OK_info_list.append(OK_info_dict)
if __name__=='__main__':
csv_file_count=0 # 保存评论数据的csv文件总数
request_count=0 # 发送删除请求的次数,发送就说明当前文件中有要删除的指定用户的评论,所以也表示含要删除的指定用户的评论的csv文件总数
mid=input_mid()
print('正在运行,请耐心等待')
file_list=os.listdir(dir_path)
for file_name in file_list:
file_path=dir_path+'/'+file_name
if (file_name[-3:] in ['csv','CSV']) and (os.path.isfile(file_path)):
delete_comment(file_name,file_path,mid)
csv_file_count=csv_file_count+1
print(f'共有{csv_file_count}个csv文件,其中{request_count}个含要删除的指定用户的评论')
if request_count>0:
if len(OK_info_list)>0:
save_OK_log()
if len(error_info_list)>0:
save_error_log()
else:
print('所有评论已删除')
















 9573
9573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









