









其实从师父从与内存的角度讲解面向对象,理解设计模式的时候。开始真正了解内存的知识,一段代码在内存中如何体现。最近看的视频中也有涉及,关于栈、堆的知识,联系广泛。以下仅是个人理解,还望指正。
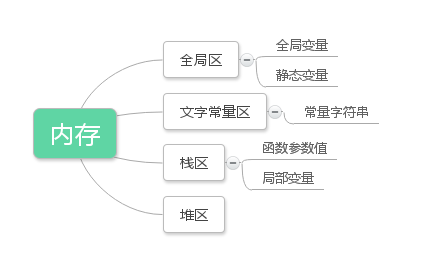
在讲解栈和堆的区别之前,先来了解一下在程序中,用来存放数据的内存分为四块,其实另外有一块用于存放代码,这里不予考虑。
1、栈区(stack)
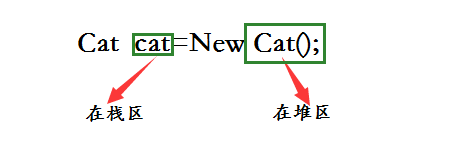
栈是限定插入和删除操作都在表的同一端进行的线性表。允许插入和删除元素的一端称为栈顶,另一端为栈底;栈底固定,栈顶浮动。由于栈按照后进先出的原则存储数据,故也称为后进先出表后进先出表后进先出表后进先出表。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。 栈可以用来在函数调用的时候存储断点,做递归时要用到栈。栈用于存放函数的参数值、局部变量的值。在进入作用域是时分配占用内存,离开作用域时释放占用内存。
2、堆区(heap)
堆是一棵经过排序的完全二叉树。一般有程序员分配释放,若程序员不释放,程序结束时可能有系统回收。由于这个原因,在C和C++中就有能产生大量程序员分配但忘记释放的堆区内存,造成可使用内存越来越少,这个被称之为内存泄露。而在java中,因为有了垃圾收集机制,这样的内存会被自动处理掉,所以在java中,反倒不需要程序员去释放内存了。
3、区别

补充一点
在系统响应方面:
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete语句才能正确的释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









