






 ,回头再慢慢往硬盘里塞。
咋工作的?
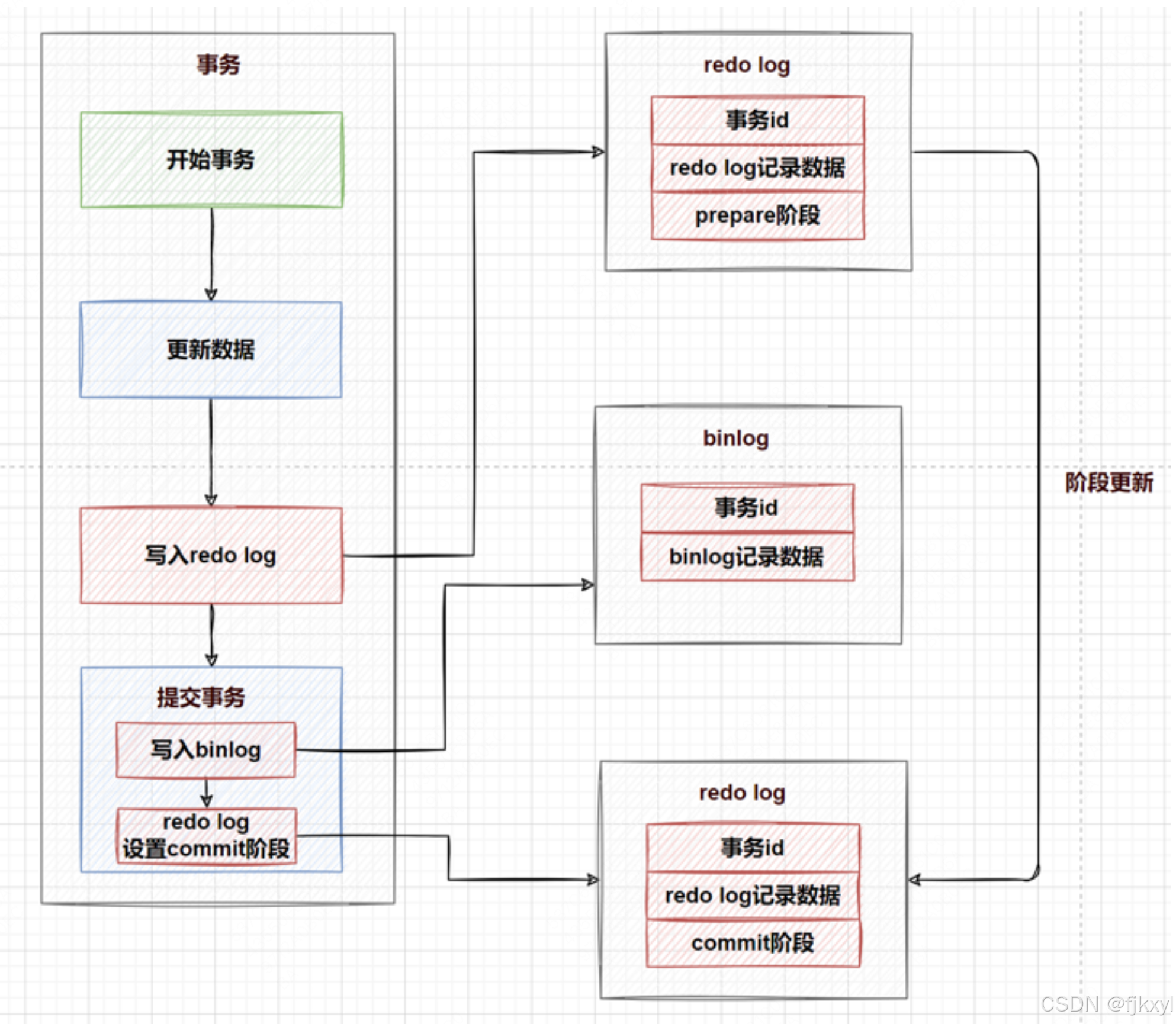
- 写数据时:你改数据,先扔到内存的
Buffer Pool里(内存快啊!),但内存一断电就凉了。所以InnoDB立马在redo log buffer里记一笔:“用户xxx在xx时间把id=1的数据从100块改成了200块”。 - 提交事务时:这纸条(redo log)会被刷到硬盘的ib_logfile文件里(这就是持久化)。哪怕这时候MySQL崩了,重启后也能拿着这纸条把没存完的数据补上。
为啥叫redo?
因为它是“重做日志”——万一数据没存完,就按这日志重新搞一遍,保证数据不丢。
吐槽:这货就是个“备胎”,平时不显山露水,关键时刻(比如崩溃恢复)才出来擦屁股。
2. undo log:“我他妈还能反悔!”
干啥的?
这货是“后悔药”。比如你改了一条数据,结果突然想撤回(ROLLBACK),或者别人在读旧版本数据(MVCC),就靠undo log把数据倒带回去。
咋工作的?
- 改数据前:InnoDB会先把旧数据复制一份,存到undo log里,比如“id=1的数据原本是100块”。
- 回滚时:直接拿undo log里的旧数据覆盖回去,假装啥都没发生。
- 持久化?:undo log也会写到硬盘(ibdata或.ibd文件),因为MySQL崩了也得能回滚啊!
吐槽:这玩意儿就是个“时光机”,专治手贱改错数据。但副作用是——占地方(尤其是长事务不提交,undo log会越堆越多,最后硬盘爆炸)。
3. binlog:“老子要搞主从复制!”
干啥的?
这货是MySQL Server层的“广播员”。不管用啥存储引擎(InnoDB、MyISAM),只要改了数据,binlog就会记下来,方便之后主从同步或者数据恢复。
咋工作的?
- 写数据时:比如你执行一个UPDATE,Server层会生成一条binlog,记录“在xx时间执行了啥SQL”。
- 提交事务时:binlog会刷到硬盘的
binlog文件里(比如mysql-bin.000001)。 - 和redo log的关系?:这俩货要搞“两阶段提交”(2PC),保证数据一致性。
- Prepare阶段:redo log写完了,但标个“待定”。
- Commit阶段:binlog写完了,再给redo log标个“确认”。
这样就算中间崩了,MySQL也能根据这俩日志判断该提交还是回滚。
吐槽:binlog就是个“大喇叭”,主库干了啥,从库都得跟着学。但写这玩意儿慢的一批(尤其是sync_binlog=1时,每次提交都刷盘),所以高并发时容易成瓶颈。
总结对比:
| redo log | undo log | binlog | |
|---|---|---|---|
| 谁家的 | InnoDB亲儿子 | InnoDB亲儿子 | MySQL Server层的干儿子 |
| 存啥 | 物理日志(在哪个页改了啥) | 逻辑日志(旧数据长啥样) | 逻辑日志(执行的SQL语句) |
| 干啥用 | 崩溃恢复(保数据) | 回滚+MVCC(保一致性) | 主从同步+数据恢复(保逻辑) |
| 吐槽 | “硬盘不够?循环覆盖!” | “长事务我***弄死你!” | “sync_binlog=1?你硬盘是SSD吗!” |
最后一句忠告:
- 想不丢数据?redo log和binlog一个都不能少(除非你心大)。
- 想不卡死?别开长事务,不然undo log能把你硬盘塞成砖头。
- 想主从不翻车?binlog用ROW格式,别用Statement(鬼知道SQL里有啥骚操作)。
完事儿!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











