







1.简介
gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩。原因大概有几个,一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征。这三点实在是太吸引人了,导致在面试的时候大家也非常喜欢问这个算法。 gbdt的面试考核点,大致有下面几个:
- gbdt 的算法的流程?
- gbdt 如何选择特征 ? CART树构建的过程
- gbdt 如何构建特征 (特征组合)?
- gbdt 如何用于分类?
- gbdt 通过什么方式减少误差 ?
- gbdt的效果相比于传统的LR,SVM效果为什么好一些 ?
- gbdt 如何加速训练?
- gbdt的参数有哪些,如何调参 ?
- gbdt 实战当中遇到的一些问题 ?
- gbdt的优缺点 ?
2. 正式介绍
首先gbdt 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
- gbdt的训练过程
我们通过一张图片,图片来源来说明gbdt的训练过程:

图 1:GBDT 的训练过程
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。

Fm−1(x) 为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
- 但是其实我们真正关注的,1.是希望损失函数能够不断的减小,2.是希望损失函数能够尽可能快的减小。所以如何尽可能快的减小呢?
- 让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心了。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
- 这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
3 GBDT几个基本概念
3.1 CART
3.2 Gradient boosting(GB)
让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心。机器学习中的学习算法的目标是为了优化或者说最小化loss Function, Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


GB算法的思想很简单,关键是怎么生成h(x)?
如果目标函数是回归问题的均方误差,很容易想到最理想的h(x)应该是能够完全拟合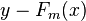 ,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题
,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题![]() 残差和负梯度也是相同的。
残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量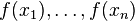 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
GB算法的步骤:
1.初始化模型为常数值:

2.迭代生成M个基学习器
1.计算伪残差
![r_{im} = -\left[\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\right]_{F(x)=F_{m-1}(x)} \quad \mbox{for } i=1,\ldots,n.](https://upload.wikimedia.org/math/0/b/e/0bebe45631e9a1c4ed693590d60829c0.png)
2.基于 生成基学习器
生成基学习器
3.计算最优的

4.更新模型

3.3 Shrinkage
Shrinkage是GBDT的第三个基本概念,中文含义为“缩减”。它的基本思想就是:每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。换句话说缩减思想不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,只有通过多学几棵树才能弥补不足。
3.4 残差
利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
可以使用梯度近似为残差
4 GBDT常用的参数
(1)树个数
(2)树深度
(3)缩放因子
(4)损失函数
(5)数据采样比
(6)特征采样比
4.GBDT 如何用于分类 ?
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。
如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。
5 GBDT多分类
多分类问题转为n个二分类(A类和other类)问题,这样就训练n个CART树即可
6 使用残差还是梯度
至此,GBDT的内容就基本讲完了,对这个算法,一方面我们可以从残差的角度来理解,每一棵回归树都是在学习之前的树的残差;另一方面也可以从梯度的角度掌握算法,即每一棵回归树通过梯度下降法学习之前的树的梯度下降值。
这样看来,这两种理解角度从总体流程和输入输出上没有区别的,它们都是迭代回归树,都是累加每棵树结果作为最终结果,每棵树都在学习前面树尚存的不足。而不同之处就在于每一步迭代时的求解方法的不同,前者使用残差(残差是全局最优值),后者使用梯度(梯度是局部最优方向),简单一点来讲就是前者每一步都在试图向最终结果的方向优化,后者则每一步试图让当前结果更好一点。
看起来前者更科学一点,毕竟有绝对最优方向不学,为什么舍近求远去估计一个局部最优方向呢?原因在于灵活性。前者最大问题是,由于它依赖残差,损失函数一般固定为反映残差的均方差,因此很难处理纯回归问题之外的问题。而后者求解方法为梯度下降,只要可求导的损失函数都可以使用
6 特征组合
使用人工经验知识来组合特征过于耗费人力,可以使用GBDT自动产生特征组合。(Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用gbdt去产生有效的特征组合)。在GBDT产生特征组合之后在把这些组合特征加入到逻辑回归中训练,提升模型最终的效果。
具体方法:生成n棵树共m个节点,然后将样本X分别输入到n棵树中,这样就可得到特征向量,向量长度为m,其中有n个1
举例:
假如我们使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0.
于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









