







 本文讲述了Hadoop的起源,包括其思想来源Google的论文,Hadoop之父DougCutting的贡献,以及Hadoop在Apache基金会的发展历程。重点介绍了ApacheHadoop项目及其相关组件如HDFS、MapReduce、YARN,以及Cloudera的CDH集成套件。企业常用的大数据技术如HBase、Spark和ZooKeeper也在文中提及,强调了大数据生态系统的集成和关键学习点。
本文讲述了Hadoop的起源,包括其思想来源Google的论文,Hadoop之父DougCutting的贡献,以及Hadoop在Apache基金会的发展历程。重点介绍了ApacheHadoop项目及其相关组件如HDFS、MapReduce、YARN,以及Cloudera的CDH集成套件。企业常用的大数据技术如HBase、Spark和ZooKeeper也在文中提及,强调了大数据生态系统的集成和关键学习点。
说明:- 表示繁写/全称
Hadoop之父
Hadoop 之父 Doug Cutting

Hadoop [hædu:p]
Cutting 儿子对玩具小象的昵称 Hadoop
Cutting很厉害,尤其在搜索引擎 Lucene
爬虫框架 Nutch
数据序列化框架 Avro
都是Apache项目的
Hadoop 时间简史
Google 三篇论文
- 《The Google File System 》 2003 简称 GFS 谷歌分布式文件系统
- 《MapReduce: Simplified Data Processing on Large Clusters》 2004 分布式计算框架
- 《Bigtable: A Distributed Storage System for Structured Data》 2006 分布式存储层(以结构化表来储存数据)
前两篇(分布式文件系统,分布式计算框架)是 Hadoop 的思想之源,用 Java 实现了 Hadoop
Hadoop 由 Apache Software Foundation 于 2005 年秋天作为 Lucene的子项目Nutch的一部分正式引入(技术相当成熟了)
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中,更名为 HDFS - Hadoop的分布式文件系统(- 表示繁写/全称)
Cloudera公司在2008年开始提供基于Hadoop的软件和服务
在大数据领域非常有名,尤其在"基建"
Apache Hadoop 项目
关键词:项目
hadoop.apache.org
Apache 阿帕奇基金会,能够出现在域名前的项目都是:顶级项目,经过生产验证的
2016年10月 Hadoop-2.6.5
2017年12月 Hadoop-3.0.0
The project includes these modules :Hadoop 项目模块
前三的 1.x 就有了
- Hadoop Common 核心工具
- Hadoop Distributed File System(HDFS) 分布式存储
- Hadoop MapReduce 分布式计算
- 2.x 才有
- Hadoop YARN 分布式资源管理
Other Hadoop-related project at Apache :Hadoop 相关
- HBase
- 来自于 Bigtable 论文
- Hlve
- 必须要会的,企业更多要解决的是数据加工的事情
- 大数据仓库
- 提供了 SQL 入口的写法,数仓数据管理方式
- Spark
- MapRduce 已经是一个分布式计算框架了,但现在用的场景已经很少了
- Spark 是它的 10倍
曾经 Hlve 底层会把 SQL 转为 MapReduce ,现在渐渐放弃了,转而用 Spark
- ZooKeeper 分布式协调服务,高可用的
- 大数据的东西,都是集群的、分布式的、多节点,如果没有一个可靠的协调者,就像多线程一样跑起来很乱,根本不可预期的
大数据生态圈
也叫:Hadoop生态圈
- 以上讲的是 阿帕奇基金会 的
- 以下讲的是 Cloudera公司:http://www.cloudera.com/
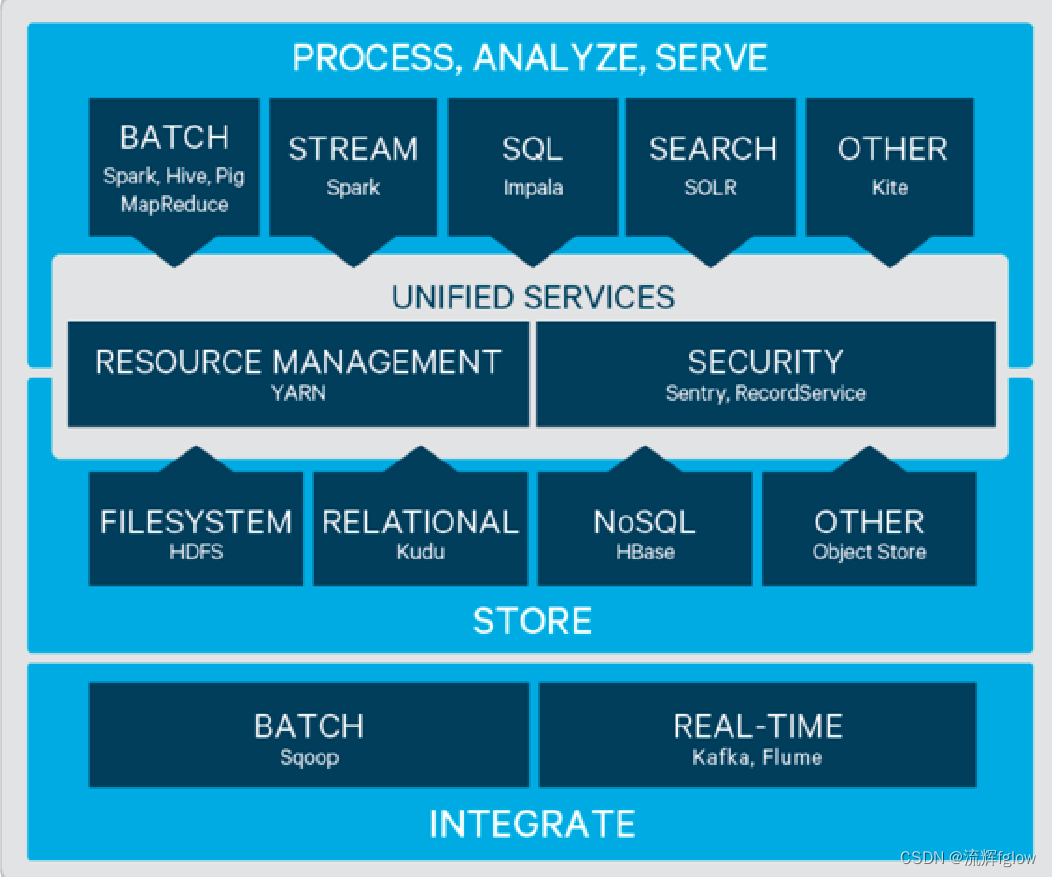
CDH - Cloudera’s Distribution Including Apache Hadoop
CDH 包含了大数据生态圈所有的技术(围绕Hadoop的)
CDH is the most complete,tested, and popular distribution of Apache Hadoop and related projects
hadoop-2.6.0+cdh5.16.1
hbase-1.2.0+cdh5.16.1
hive-1.1.0+cdh5.16.1
spark-1.6.0+cdh5.16.1
官方文档:Cloudera Product Documentation
企业用得最多的还是 5.16.x 的,整合的大数据生态圈hadoop技术:版本是相对比较老,但相对比较可靠稳定的,企业比较放心 2.x 版本的(企业:不能”脑袋捆到裤腰带上“)
所以我选择了 Hadoop-2.6.5
6.0.x 整合的就是 3.x 版本的
重点学习
接入层 Integrate
- Sqoop ,Kafka ,Flume
存储层 Store - HDFS ,Kudu自开发的 ,HBase ,Object Store对象存储
统一的服务层 - YARN资源管理 ,安全的 Sentry
处理 解析 服务 层 - 批量计算 Spark & Hlve
- 流式计算 Spark
- SQL 解析 Impala自强推,Hvlue和Spark也能提供SQL
- Spark 可全栈,批计算、流计算、机器学习、SQL解析等都可以做
Flink 全栈(更强:流计算,真 实时)
阿里 是 最大的推动公司,把她进行大换血、源码重写、架构重新整理,17年底18年 非常大的推动了一把
因为大数据迎来了一个新的生机,批 转 流计算
批计算的弊端:一整天 收集完所有的数据,晚上一次性计算,怎么想显然都不合理















 3392
3392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









