






爬虫原理
计算机一次Request请求和服务器端的Response回应,即实现了网络连接。
爬虫需要做两件事:模拟计算机对服务器发起Request请求。
接受服务器的Response内容并解析、提取所需的信息。
多页面爬虫流程
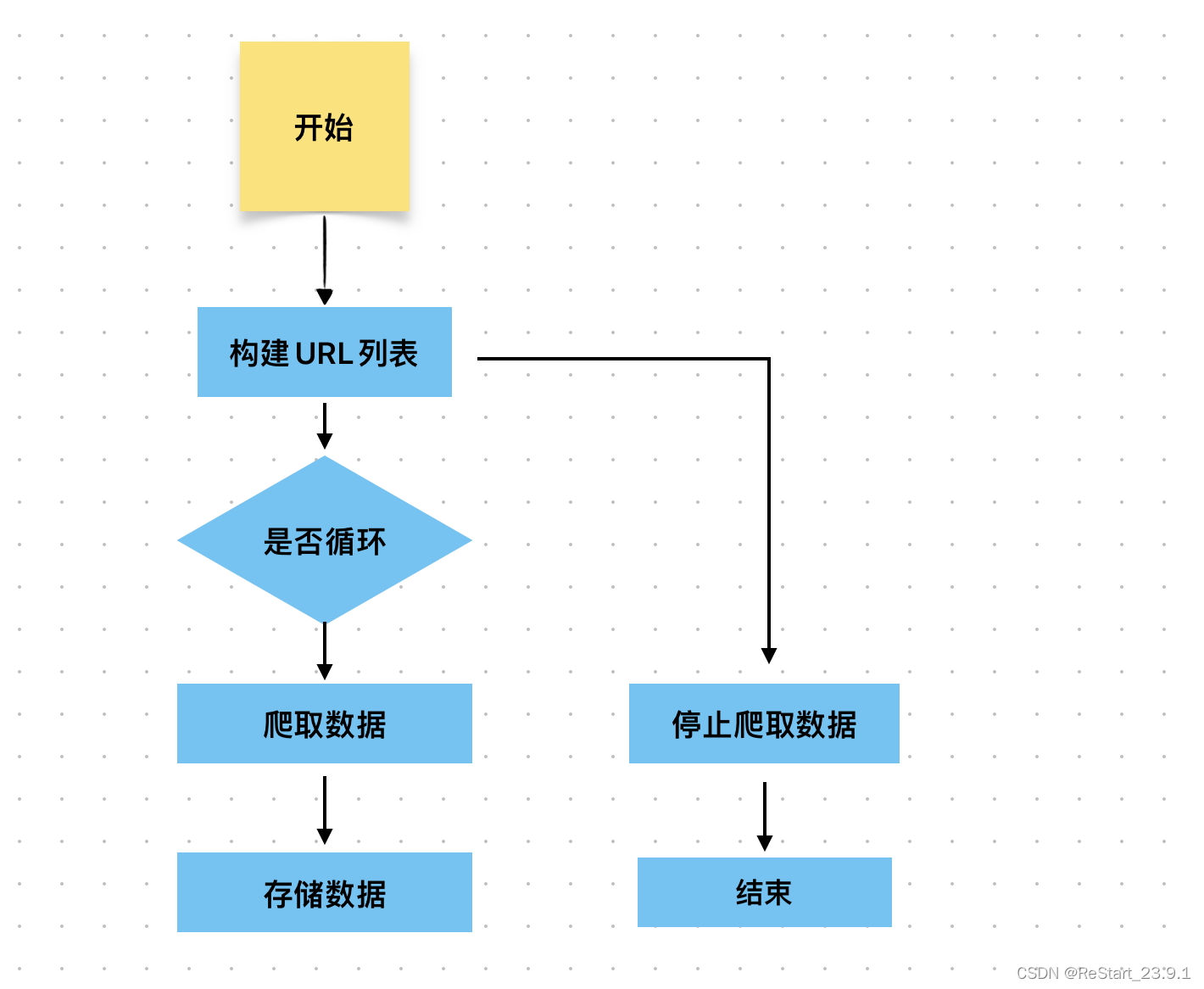
多页面网页爬虫流程

计算机一次Request请求和服务器端的Response回应,即实现了网络连接。
爬虫需要做两件事:模拟计算机对服务器发起Request请求。
接受服务器的Response内容并解析、提取所需的信息。
多页面网页爬虫流程











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 5046
5046





