






做大数据好久了,之前一直没有时间写写大数据的相关内容,今天终于有时间写下,后续会一直更新,欢迎大家指正。
hadoop集群搭建是学习大数据的第一步,开始会觉得有些麻烦,玩的时间长了回来看看也就那么回事
虚拟机安装centos7
https://www.osyunwei.com/archives/7829.html
步骤2设置IP地址、网关DNS不用执行
当前安装系统可作为集群master主机,
虚拟机关机状态下,将master复制两份,作为slave1和slave2
集群规划
1.设置静态IP
2.最终的集群
Master 192.168.40.10
Slave1 192.168.40.11
Slave2 192.168.40.12
3.关闭防火墙
查看防火墙状态:systemctl status firewalld.service

绿色running表示防火墙开启
执行关闭命令:systemctl stop firewalld.service
执行开机禁用防火墙自启命令:systemctl disable firewalld.service
再次执行查看防火墙命令:systemctl status firewalld.service
4.修改域名和对应IP
#Execute in Master、Slave1、Slave2
vim /etc/hosts
192.168.40.10 master
192.168.40.11 slave1
192.168.40.12 slave2
重启服务: service network restart
5.SSH互信配置
#Execute in Master、Slave1、Slave2
#生成密钥对(公钥和私钥)
ssh-keygen -t rsa
#三次回车生成密钥

#Execute in Maste
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys
#追加密钥到Master
ssh slave1 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
#复制密钥到从节点
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys
6.JDK安装
下载jdk:jdk1.8.0_161.tar.gz放到/usr/local/src
#Executer in Maste
cd /usr/local/src
tar zxvf jdk1.8.0_161.tar.gz
配置JDK环境变量
#Executer in Maste
#配置JDK环境变量
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_161
JAVA_BIN=/usr/local/src/jdk1.8.0_161/bin
JRE_HOME=/usr/local/src/jdk1.8.0_161/jre
CLASSPATH=/usr/local/src/jdk1.8.0_161/jre/lib:/usr/local/src/jdk1.8.0_161/lib:/usr/local/src/jdk1.8.0_161/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
有的建议将变量配置在~/.bashrc文件的结尾
分发到各个从机节点
#Executer in Master
使用root权限,将JDK分发到其他slave节点
scp -r /usr/local/src/jdk1.8.0_161 root@slave1:/usr/local/src/jdk1.8.0_161
scp -r /usr/local/src/jdk1.8.0_161 root@slave2:/usr/local/src/jdk1.8.0_161
#分发到其他slave节点
scp /root/.bashrc root@slave1:/root/.bashrc
scp /root/.bashrc root@slave2:/root/.bashrc
7.验证jdk
#Executer in Master,slave1,slave2
#刷新环境变量
source ~/.bashrc
验证变量是否生效:
Java -version
hadoop安装
1.下载Hadoop
#Executer in Master
cd /usr/local/src
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.1/hadoop-2.6.1.tar.gz
tar zxvf hadoop-2.6.1.tar.gz
cd hadoop-2.6.1
mkdir tmp
2.修改Hadoop配置文件
#Executer in Master
配置文件修改
3.配置环境变量
#Executer in Master、Slave1、Slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/bin
#刷新环境变量
source ~/.bashrc
4.安装包拷贝到Slave主机
#Executer in Master
scp -r /usr/local/src/hadoop-2.6.1 root@slave1:/usr/local/src/hadoop-2.6.1
scp -r /usr/local/src/hadoop-2.6.1 root@slave2:/usr/local/src/hadoop-2.6.1
5.启动集群
#Executer in Master
#初始化NameNode
cd /usr/local/src/hadoop-2.6.1/bin/
./hadoop namenode -format
#启动Hadoop集群
cd /usr/local/src/hadoop-2.6.1/sbin
./start-all.sh
6.查看集群状态
#Executer in Master
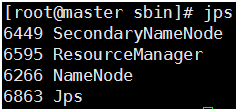
#Executer in slave1
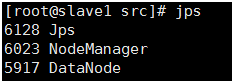
#Executer in slave2
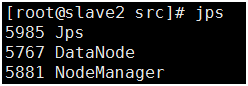
其他环境安装:
- python3安装
步骤三python版本需要自己下载
步骤四不需执行,因为当前环境同时适配了python2和python3

- Python pip配置
- Vim配置
- Centos7 取消锁屏
应用程序–系统工具–设置–隐私–锁屏状态-关闭















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









