






1)EM 算法之目的 一种通过迭代的期望最大化算法(Expectation-Maximization Algorithm)
\qquad
通过观察数据,获取模型参数。例如
x
1
,
x
2
,
.
.
.
,
x
n
x_{1},x_{2},...,x_{n}
x1,x2,...,xn,为某班男女同学身高,其中,男生身高服从高斯分布1:
N
1
(
μ
1
,
σ
1
)
\Nu_{1}(\mu_{1},\sigma_{1})
N1(μ1,σ1);女生身高服从高斯分布2:
N
2
(
μ
2
,
σ
2
)
\Nu_{2}(\mu_{2},\sigma_{2})
N2(μ2,σ2);没有其他性别。求:男女分布的参数
μ
1
,
σ
1
,
μ
2
,
σ
2
\mu_{1},\sigma_{1},\mu_{2},\sigma_{2}
μ1,σ1,μ2,σ2)
2)EM 算法之难点
\qquad
不知道谁是男是女。。。。。
\qquad
不知道男女比例。。。。。
有隐变量(记为:z)在问题中,有点不好搞。
3)EM 算法之通用说明

符号说明:
观察值 X:
x
1
,
x
2
,
.
.
.
,
x
n
x_{1},x_{2},...,x_{n}
x1,x2,...,xn
分布参数
θ
\theta
θ : 含各类分布参数
隐变量z:例如上例中的男女
概率
p
(
X
∣
θ
)
\red {p(X|\theta)}
p(X∣θ):在
θ
\theta
θ已知条件下,
x
1
,
x
2
,
.
.
.
,
x
n
x_{1},x_{2},...,x_{n}
x1,x2,...,xn 出现的概率,极大似然的目标函数。
概率
p
(
X
∣
z
,
θ
)
p(X|z,\theta)
p(X∣z,θ):在z,
θ
\theta
θ已知条件下,X 出现的概率, 这货好算,相当于知道了是男娃子还是女娃子。
概率
p
(
X
,
z
∣
θ
)
\red{p(X,z|\theta)}
p(X,z∣θ):在
θ
\theta
θ已知条件下,同时X和z的概率。这货嘛,如果知道了男女娃子的先验概率,也好算。由于男同学概率+女同学概率=1.0,所以有:
∑
z
p
(
X
,
z
∣
θ
)
=
p
(
X
∣
θ
)
\red{\sum_{z}p(X,z|\theta)=p(X|\theta)}
∑zp(X,z∣θ)=p(X∣θ),z被积掉了。
4)EM 算法之三个基础知识
-
贝叶斯公式: P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B)=\frac{P(A)P(B|A)}{P(B)} P(A∣B)=P(B)P(A)P(B∣A), 不说了,好懂的。
-
极大似然估计法: l ( θ ) = p ( X ∣ θ ) l(\theta) = p(X|\theta) l(θ)=p(X∣θ) = ∏ i = 1 n p ( x i ∣ θ ) \prod_{i=1}^np(x_{i}|\theta) ∏i=1np(xi∣θ)
实际中常用对数最大似然: l n l ( θ ) ln l(\theta) lnl(θ)= ∑ i = 1 n l n p ( x i ∣ θ ) \sum_{i=1}^nlnp(x_{i}|\theta) ∑i=1nlnp(xi∣θ)
即: θ ^ = arg max θ ∑ i = 1 n l n ( p ( x i ∣ θ ) ) \red{\hat\theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^nln(p(x_{i}|\theta))} θ^=θargmax∑i=1nln(p(xi∣θ)),相乘变成相加。
例如:只有一种高斯分布时,化简易得:
l n l ( θ ) lnl(\theta) lnl(θ)= ∑ i = 1 n [ − l n 2 π − 1 2 l n σ 2 − ( x i − μ ) 2 2 σ 2 ] \sum_{i=1}^n[-ln\sqrt{2\pi}-\frac{1}{2}ln\sigma^2-\frac{(x_{i}-\mu)^2}{2\sigma^2}] ∑i=1n[−ln2π−21lnσ2−2σ2(xi−μ)2]
∂ l n l ( θ ) ∂ u = 0 = > μ ^ = x 1 + x 2 + . . . + x n n \frac{\partial lnl(\theta)}{\partial u }=0 =>\hat\mu=\frac{x_{1}+x_{2}+...+x_{n}}{n} ∂u∂lnl(θ)=0=>μ^=nx1+x2+...+xn
∂ l n l ( θ ) ∂ σ 2 = 0 = > σ ^ 2 = 1 n ∑ i = 1 n ( x i − μ ) 2 \frac{\partial lnl(\theta)}{\partial \sigma^2 }=0 =>\hat\sigma^2=\frac{1}{n}\sum_{i=1}^n(x_{i}-\mu)^2 ∂σ2∂lnl(θ)=0=>σ^2=n1∑i=1n(xi−μ)2
即: θ ^ = ( μ ^ , σ ^ 2 ) \hat\theta=(\hat\mu,\hat\sigma^2) θ^=(μ^,σ^2), θ ^ \qquad\hat\theta θ^:表示优化后的 θ \theta θ值,读:hat。 -
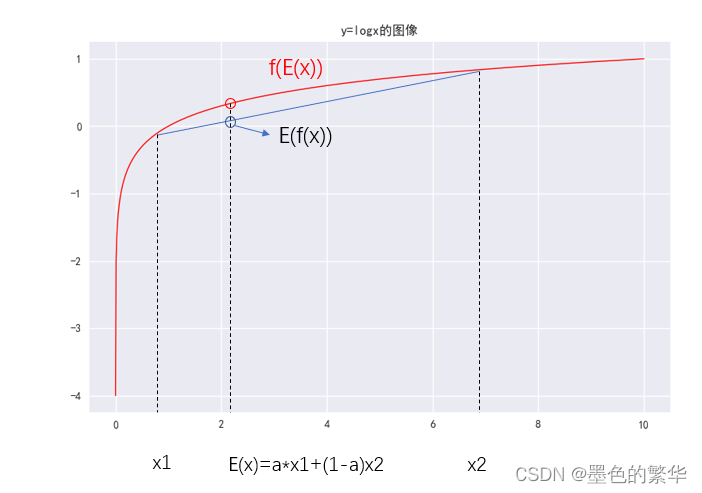
Jensen不等式:
对于f(x)的凹函数:瞪眼看,有 f ( E ( x ) ) ≧ E ( f ( x ) ) \red{f(E(x))\geqq E(f(x))} f(E(x))≧E(f(x))
即:x的期望的函数值 大于等于 函数值f(x)的期望
仅当: x 1 = x 2 x_{1}=x_{2} x1=x2为同一点时, f ( E ( x ) ) = E ( f ( x ) ) f(E(x))= E(f(x)) f(E(x))=E(f(x))
凸函数相反。
5)EM 算法之步骤
举个例子,体验神奇:
-
你看到29 个同学的身高数据如下图。(是男娃子,女娃子?不是你能知道的哟!(男:17 vs 女:12),我是从上帝视角给你参考的。)

-
已知:男娃子身高高一些,男娃子,女娃子都符合各自的正态分布。
-
求:男女娃子各个多少,他们的分布参数 μ 男 , σ 男 , μ 女 , σ 女 \mu_{男},\sigma_{男},\mu_{女},\sigma_{女} μ男,σ男,μ女,σ女。
-
过程如图(请仔细看!至少读一遍, 会有代码的。)
E: 期望步骤:求 p ( z ∣ x , θ ) , p ( z ∣ θ ) p(z|x,\theta),p(z|\theta) p(z∣x,θ),p(z∣θ)
M: 最大化步骤:利用对数极大似然求 θ \theta θ

注意: 一个人是男是女的概率
p
(
z
男
∣
x
,
θ
)
=
p
(
z
男
∣
θ
)
∗
p
(
x
∣
z
男
,
θ
)
/
p
(
x
∣
θ
)
−
−
−
−
i
p(z_{男}|x,\theta)=p(z_{男}|\theta)*p(x|z_{男},\theta)/p(x|\theta)----i
p(z男∣x,θ)=p(z男∣θ)∗p(x∣z男,θ)/p(x∣θ)−−−−i
p
(
z
女
∣
x
,
θ
)
=
p
(
z
女
∣
θ
)
∗
p
(
x
∣
z
女
,
θ
)
/
p
(
x
∣
θ
)
−
−
−
−
i
i
p(z_{女}|x,\theta)=p(z_{女}|\theta)*p(x|z_{女},\theta)/p(x|\theta)----ii
p(z女∣x,θ)=p(z女∣θ)∗p(x∣z女,θ)/p(x∣θ)−−−−ii
有:
p
(
z
男
∣
x
,
θ
)
/
p
(
z
女
∣
x
,
θ
)
=
p
(
z
男
∣
θ
)
∗
p
(
x
∣
z
男
,
θ
)
/
p
(
z
女
∣
θ
)
∗
p
(
x
∣
z
女
,
θ
)
,而
p
(
z
男
∣
θ
)
通过迭代提供,而
p
(
x
∣
z
男
,
θ
)
=
N
男
(
μ
男
,
σ
男
)
提供,女娃子相关类似
p(z_{男}|x,\theta)/p(z_{女}|x,\theta)=p(z_{男}|\theta)*p(x|z_{男},\theta)/p(z_{女}|\theta)*p(x|z_{女},\theta),而p(z_{男}|\theta) 通过迭代提供,而p(x|z_{男},\theta)=\Nu_{男}(\mu_{男},\sigma_{男}) 提供,女娃子相关类似
p(z男∣x,θ)/p(z女∣x,θ)=p(z男∣θ)∗p(x∣z男,θ)/p(z女∣θ)∗p(x∣z女,θ),而p(z男∣θ)通过迭代提供,而p(x∣z男,θ)=N男(μ男,σ男)提供,女娃子相关类似
而:
p
(
z
男
∣
x
,
θ
)
+
p
(
z
女
∣
x
,
θ
)
=
1
p(z_{男}|x,\theta)+p(z_{女}|x,\theta)=1
p(z男∣x,θ)+p(z女∣x,θ)=1
可是算出:
p
(
z
男
∣
x
,
θ
)
,
p
(
z
女
∣
x
,
θ
)
p(z_{男}|x,\theta),p(z_{女}|x,\theta)
p(z男∣x,θ),p(z女∣x,θ)
具体细节如excel:

EM 算法结果,人数:男,17.76 vs 17;女,11.24 vs 12 相差不足一个! 平均身高:男 1.73 vs1.75;女 1.64 vs1.62。
6)EM 算法之原理
对于出现的样本X:{
x
1
,
x
2
,
.
.
.
,
x
n
x_{1},x_{2},...,x_{n}
x1,x2,...,xn},对数极大似然:
θ
=
arg
max
θ
∑
i
=
1
n
l
n
(
p
(
x
i
∣
θ
)
)
\red{\theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n ln(p(x_{i}|\theta))}
θ=θargmaxi=1∑nln(p(xi∣θ))
考虑到隐变量:z: {
z
1
,
z
2
,
.
.
.
z_1,z_2,...
z1,z2,...}
θ
=
arg
max
θ
∑
i
=
1
n
l
n
∑
z
p
(
x
i
,
z
∣
θ
)
\red{\theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n ln \sum_{z} p(x_{i},z|\theta)}
θ=θargmaxi=1∑nlnz∑p(xi,z∣θ)
构造一个
Q
(
z
)
Q(z)
Q(z),使得
∑
z
Q
(
z
)
=
1
\sum_zQ(z)=1
∑zQ(z)=1,而有:
θ
=
arg
max
θ
∑
i
=
1
n
l
n
∑
z
Q
(
z
)
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
\red{\theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n ln \sum_{z} Q(z)\frac {p(x_{i},z|\theta)} {Q(z)}}
θ=θargmaxi=1∑nlnz∑Q(z)Q(z)p(xi,z∣θ)
ln 为凹函数,利用Jensen不等式
f
(
E
(
x
)
)
≧
E
(
f
(
x
)
)
f(E(x))\geqq E(f(x))
f(E(x))≧E(f(x)):
θ
=
arg
max
θ
∑
i
=
1
n
l
n
∑
z
Q
(
z
)
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
≧
θ
=
arg
max
θ
∑
i
=
1
n
∑
z
Q
(
z
)
l
n
(
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
)
\red{\theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n ln \sum_{z} Q(z)\frac {p(x_{i},z|\theta)} {Q(z)} \geqq \theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n \sum_{z} Q(z)ln(\frac {p(x_{i},z|\theta)} {Q(z)} ) }
θ=θargmaxi=1∑nlnz∑Q(z)Q(z)p(xi,z∣θ)≧θ=θargmaxi=1∑nz∑Q(z)ln(Q(z)p(xi,z∣θ))
注意相等时:
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
=
C
\red {\frac {p(x_{i},z|\theta)} {Q(z)}=C}
Q(z)p(xi,z∣θ)=C ,C为常量。
∑ z Q ( z ) = 1 推出 ∑ z p ( x i , z ∣ θ ) = C \sum_zQ(z)=1 推出\sum_z p(x_i,z|\theta)=C z∑Q(z)=1推出z∑p(xi,z∣θ)=C
Q ( z i ) = p ( x i , z ∣ θ ) C = p ( x i , z ∣ θ ) ∑ z p ( x i , z ∣ θ ) = p ( x i , z ∣ θ ) p ( x i ∣ θ ) Q(z_i)=\frac{p(x_i,z|\theta)}{C}=\frac{\ p(x_i,z|\theta)}{\sum_z p(x_i,z|\theta)}=\frac{p(x_i,z|\theta)}{p(xi|\theta)} Q(zi)=Cp(xi,z∣θ)=∑zp(xi,z∣θ) p(xi,z∣θ)=p(xi∣θ)p(xi,z∣θ)
即:
Q
(
z
i
)
=
p
(
x
i
,
z
∣
θ
)
p
(
x
i
∣
θ
)
=
p
(
z
∣
x
i
,
θ
)
\red{Q(z_i)=\frac{p(x_i,z|\theta)}{p(xi|\theta)}=p(z|x_i,\theta)}
Q(zi)=p(xi∣θ)p(xi,z∣θ)=p(z∣xi,θ)
相当于算出男、女比例,根据这个参数。M 对数极大似然优化:
θ
^
=
arg
max
θ
∑
i
=
1
n
∑
z
Q
(
z
)
l
n
(
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
)
\red{\hat \theta=\mathop{\arg\max}\limits_{\theta}\sum_{i=1}^n \sum_{z} Q(z)ln(\frac {p(x_{i},z|\theta)} {Q(z)} )}
θ^=θargmaxi=1∑nz∑Q(z)ln(Q(z)p(xi,z∣θ))
例如对于
l
n
(
l
(
θ
)
)
ln(l(\theta))
ln(l(θ))其偏导,如果是高斯混合分布,k轮迭代有:
γ
i
,
z
=
p
(
z
∣
θ
)
∗
p
(
x
∣
z
,
θ
)
∑
z
p
(
z
∣
θ
)
∗
p
(
x
∣
z
,
θ
)
\red {\gamma_{i,z}=\frac{p(z|\theta)*p(x|z,\theta)} {\sum_z p(z|\theta)*p(x|z,\theta) }}
γi,z=∑zp(z∣θ)∗p(x∣z,θ)p(z∣θ)∗p(x∣z,θ)
μ z = γ x i ∑ i = 1 n γ \mu_z=\frac{\gamma x_i}{\sum_{i=1}^n \gamma}\quad μz=∑i=1nγγxi 注意:有多个类型分布,就有多个 μ z \mu_{z} μz
σ z = ∑ i = 1 n γ ( x i − u z ) 2 ∑ i = 1 n γ \sigma_z=\frac{\sum_{i=1}^n\gamma (x_i-u_z)^2}{\sum_{i=1}^n \gamma}\quad σz=∑i=1nγ∑i=1nγ(xi−uz)2
7)EM 算法之收敛
程序判定收敛,只证明单调递增。
在t+1 次计算,
θ
t
\theta^{t}
θt为常量,
θ
(
t
+
1
)
\theta^{(t+1)}
θ(t+1)为对数极大似然优化量
所以有
l
n
(
l
(
θ
(
t
+
1
)
)
)
≧
∑
i
=
1
n
∑
z
Q
(
z
)
l
n
(
p
(
x
i
,
z
∣
θ
(
t
+
1
)
)
Q
(
z
)
)
≧
∑
i
=
1
n
∑
z
Q
(
z
)
l
n
(
p
(
x
i
,
z
∣
θ
t
)
Q
(
z
)
)
\red{ ln (l(\theta^{(t+1)})) \geqq \sum_{i=1}^n \sum_{z} Q(z)ln(\frac {p(x_{i},z|\theta^{(t+1)})} {Q(z)} ) \geqq \sum_{i=1}^n \sum_{z} Q(z)ln(\frac {p(x_{i},z|\theta^{t})} {Q(z)} ) }
ln(l(θ(t+1)))≧i=1∑nz∑Q(z)ln(Q(z)p(xi,z∣θ(t+1)))≧i=1∑nz∑Q(z)ln(Q(z)p(xi,z∣θt))
又因为Q(z),求的时候有:
p
(
x
i
,
z
∣
θ
)
Q
(
z
)
=
C
\frac {p(x_{i},z|\theta)} {Q(z)}=C
Q(z)p(xi,z∣θ)=C,Jensen不等式取等号:
所以有:
∑
i
=
1
n
∑
z
Q
(
z
)
l
n
(
p
(
x
i
,
z
∣
θ
t
)
Q
(
z
)
)
=
l
n
(
l
(
θ
t
)
)
\red{ \sum_{i=1}^n \sum_{z} Q(z)ln(\frac {p(x_{i},z|\theta^{t})} {Q(z)} )=ln(l(\theta^{t})) }
i=1∑nz∑Q(z)ln(Q(z)p(xi,z∣θt))=ln(l(θt))
因此:
l
n
(
l
(
θ
(
t
+
1
)
)
)
≧
l
n
(
l
(
θ
t
)
)
ln (l(\theta^{(t+1)})) \geqq ln(l(\theta^{t}))
ln(l(θ(t+1)))≧ln(l(θt)),为递增,得证。
8)EM 算法之python 代码
# coding=utf-8
import numpy as np
import math
# 作者dls
# 生成样本
height_M = np.random.normal(loc=1.75, scale=0.07, size=17) # 正态分布,男生
height_F = np.random.normal(loc=1.62, scale=0.07, size=12) # 正态分布,女生
dataset = arr4 = np.concatenate((height_F, height_M), axis=0)
# print(dataset)
# 初始化
gamma = [0.5, 0.5] # 男女概率p(z|θ)
theta = [1.70, 0.01, 1.62, 0.01] # 男女分布参数
# part_M = [] # 初始化每个人男的比例
# part_F = [] # 初始化每个人女的比例
# 密度分布函数
def normal_distribution(x, mean, sigma):
return np.exp(-1 * ((x - mean) ** 2) / (2 * (sigma ** 2))) / (math.sqrt(2 * np.pi) * sigma)
# 更新男女分布
def update_Q(dataset, theta, gamma):
part_M = []
part_F = []
for data in dataset:
dis_M = normal_distribution(data, theta[0], theta[1])
dis_F = normal_distribution(data, theta[2], theta[3])
part_M_data = dis_M * gamma[0] / (dis_M * gamma[0] + dis_F * gamma[1])
part_M.append(part_M_data)
part_F.append(1 - part_M_data)
gamma[0] = np.sum(part_M)
gamma[1] = np.sum(part_F)
return part_M, part_F, gamma
# 更新平均值
def update_mean(dataset, part):
sum_total = 0
sum_count = 0
for i in range(len(part)):
sum_total = sum_total + part[i] * dataset[i]
sum_count = sum_count + part[i]
return sum_total / sum_count
# 更新sigma
def update_sigma(dataset, part, u):
sum_total = 0
sum_count = 0
for i in range(len(part)):
sum_total = sum_total + part[i] * (dataset[i] - u) * (dataset[i] - u)
sum_count = sum_count + part[i]
return math.sqrt(sum_total / sum_count)
part_M, part_F, gamma = update_Q(dataset, theta, gamma)
# print("男的权重",part_M)
theta[0] = update_mean(dataset, part_M)
theta[1] = update_sigma(dataset, part_M, theta[0])
theta[2] = update_mean(dataset, part_F)
theta[3] = update_sigma(dataset, part_M, theta[2])
for i in range(20):
# E 步骤
part_M, part_F, gamma = update_Q(dataset, theta, gamma)
# print("男的权重",part_M)
# M 步骤
theta[0] = update_mean(dataset, part_M)
theta[1] = update_sigma(dataset, part_M, theta[0])
theta[2] = update_mean(dataset, part_F)
theta[3] = update_sigma(dataset, part_M, theta[2])
print("开始次数", i + 1)
print("男女概率", gamma)
print("分布参数", theta)
print("*" * 80)
print()
# print(gamma)
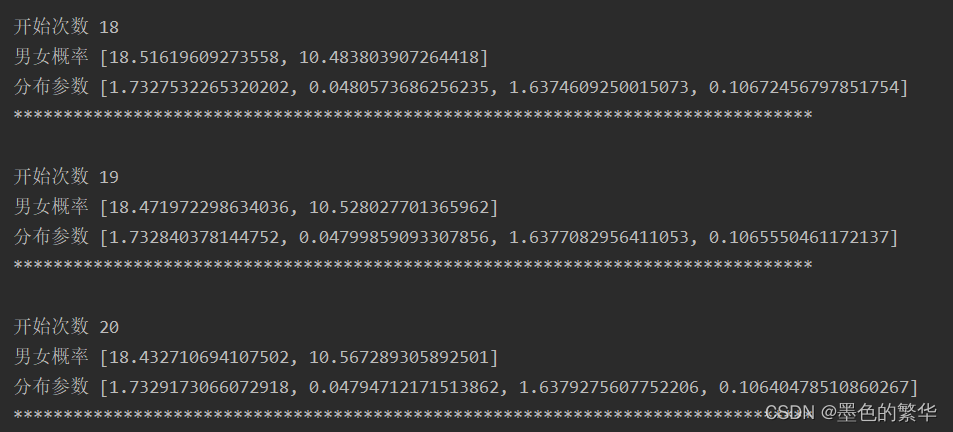
误差比较小。
9)EM 算法之感谢
简博士 大神 女神 的视频,收益匪浅!
https://www.bilibili.com/video/BV1No4y1o7ac/?spm_id_from=333.999.0.0














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









