






2021-11-02每日刷题打卡
力扣——二叉树
104. 二叉树的最大深度和剑指 Offer 55 - I. 二叉树的深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/
9 20
/
15 7
返回它的最大深度 3 。
遍历树,每次对比左子树和右子树的深度,选最大的那个。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if (root == nullptr) return 0;
return max(maxDepth(root->left), maxDepth(root->right)) + 1;
}
};
111. 二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
示例 1:
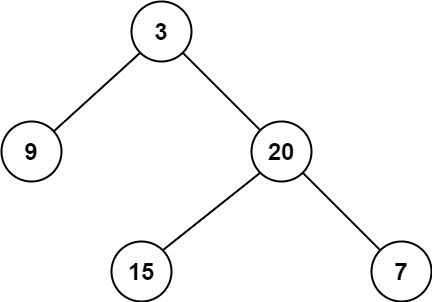
输入:root = [3,9,20,null,null,15,7]
输出:2
遍历树,每遍历一个结点判断一下,如果这个结点为NULL就返回0,如果这个结点left和right都为NULL,说明这个结点就是叶子结点,返回1。如果不是叶子节点,拿这个结点接着去遍历,这个结点的左子树和右子树看看哪个的深度最小,最后返回这个小的深度+1(+1是算上根节点)。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root)return 0;
if(!root->left&&!root->right)return 1;
int num=100000;
if(root->left!=NULL)num=min(minDepth(root->left),num);
if(root->right!=NULL)num=min(minDepth(root->right),num);
return num+1;
}
};
222. 完全二叉树的节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例 1:

输入:root = [1,2,3,4,5,6]
输出:6
用dfs来写树是最方便了,dfs函数一开始先判断结点是否为NULL,如果是就返回0,如果不是再判断这节点是否是叶子节点(无左节点和右节点),如果是就只记此处有一个节点(return 1)。如果不是就递归调用dfs本身,把这个节点的左节点和右节点当做参数送去遍历,把结果相加后再+1返回(+1是为了算上自己本身的节点)。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int countNodes(TreeNode* root) {
if(!root)return 0;
return dfs(root->left)+dfs(root->right)+1;
}
int dfs(TreeNode *p)
{
if(!p)return 0;
else if(!p->left&&!p->right)return 1;
return dfs(p->left)+dfs(p->right)+1;
}
};
572. 另一棵树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:
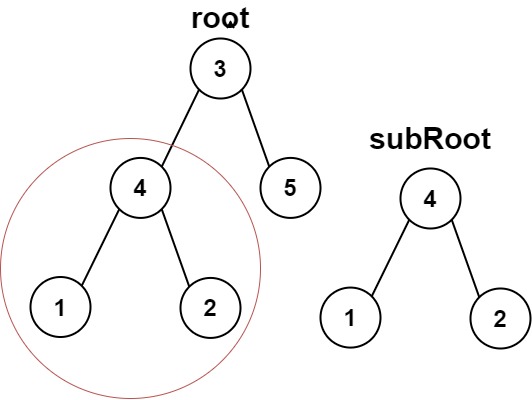
输入:root = [3,4,5,1,2], subRoot = [4,1,2]
输出:true
判断root中有subRoot的条件是:root和subRoot相等,或subRoot是root的一个左子树,或subRoot是root的一个右子树。而判断root和subRoot相等的条件是:root和subRoot的val值相等,且root的左子树和subRoot的左子树的val值相等,且root的右子树和subRoot的右子树的val值相等。所以我们要写两个递归函数,一个是判断root中有subRoot的dfs函数,还有一个是判断root和subRoot相等的check函数。
dfs的实现是,先判断当前节点是否为NULL,如果是说明不与subRoot本身相等(subRoot本身至少有一个节点),然后用check来判断当前节点是否和subRoot相等,判断subRoot是否是root的左子树或右子树,只要这三者有一个为true那就为true;
check的实现是,判断当前节点和subRoot是否都为NULL(我们传递的参数有可能是subRoot的子节点,所以会出现subRoot为空的情况),如果都为空说明相等返回true,然后判断当前节点和subRoot是否有一个为空,如果有就返回false,判断当前节点的val和subRoot的val是否相等,如果不相等返回false,如果相等把当前节点的左节点和subRoot的左节点拿去下一次判断,再把当前节点的右节点和subRoot的右节点拿去下一次判断,两者只要有一个不为true那就都不为true。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
return dfs(root,subRoot);
}
bool dfs(TreeNode*p,TreeNode*q)
{
if(!p)return false;
return check(p,q)||dfs(p->left,q)||dfs(p->right,q);
}
bool check(TreeNode*p,TreeNode*q)
{
if(!p&&!q)return true;
if(!p&&q||p&&!q||p->val!=q->val)return false;
return check(p->left,q->left)&&check(p->right,q->right);
}
};
144. 二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
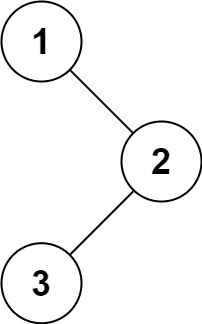
输入:root = [1,null,2,3]
输出:[1,2,3]
前序遍历:先从根节点开始,然后到左节点,再到右节点。
我们准备一个vector容器v来存放遍历顺序,用dfs来遍历树,dfs的实现是:先判断当前节点是否为空,如果为空就结束程序,如果不为空就先把当前节点的值存入v中,然后把节点的左子树先送去dfs下一次递归,再把右子树送去下一次递归。当递归完后前序排列的顺序就都存在v中了,返回v即可。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int>v;
dfs(root,v);
return v;
}
void dfs(TreeNode* p,vector<int>& v)
{
if(!p)return;
else
{
v.push_back(p->val);
dfs(p->left,v);
dfs(p->right,v);
}
}
};
94. 二叉树的中序遍历
给定一个二叉树的根节点 root ,返回它的 中序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
中序遍历:先从左节点开始,然后到跟节点,再到右节点。
我们准备一个vector容器v来存放遍历顺序,用dfs来遍历树,dfs的实现是:先判断当前节点是否为空,如果为空就结束程序,如果不为空就先把节点的左子树先送去dfs下一次递归,然后把当前节点的值存入v中,再把右子树送去下一次递归。当递归完后中序排列的顺序就都存在v中了,返回v即可。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int>v;
dfs(root,v);
return v;
}
void dfs(TreeNode* p,vector<int>& v)
{
if(!p)return;
else
{
dfs(p->left,v);
v.push_back(p->val);
dfs(p->right,v);
}
}
};
145. 二叉树的后序遍历
给定一个二叉树,返回它的 后序 遍历。
示例:
输入: [1,null,2,3]
1
2
/
3
输出: [3,2,1]
后序遍历:先从左节点开始,然后到右节点,再到跟节点。
我们准备一个vector容器v来存放遍历顺序,用dfs来遍历树,dfs的实现是:先判断当前节点是否为空,如果为空就结束程序,如果不为空就先把节点的左子树先送去dfs下一次递归,然后把右子树送去下一次递归,再把当前节点的值存入v中。当递归完后后序排列的顺序就都存在v中了,返回v即可。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int>v;
dfs(root,v);
return v;
}
void dfs(TreeNode*p,vector<int>& v)
{
if(!p)return;
else
{
dfs(p->left,v);
dfs(p->right,v);
v.push_back(p->val);
}
}
};
这三个遍历只是改变了在v中插入值、传左子树递归、传右子树递归的顺序而已。本质上来说是一模一样的。















 4770
4770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









