






一、异常处理
java的异常处理分为很多异常,
1.1java异常体系
java的异常处理流程和机制是比较完善的,如果能很好的处理异常机制,则是一个稳定软件和系统的重要表现。
1.1.1异常的重要的作用之一就是为系统安全护航
优秀的异常处理应当遵守:
- 异常应当描述导致当前异常发生的原因
- 根据异常栈快速定位到异常发生的位置
- 结合异常描述和异常栈解决异常
- 异常返回的值应该与常规的值有明显区分
- 可以不用调用方来分析异常
1.2异常处理
java的异常处理流程图
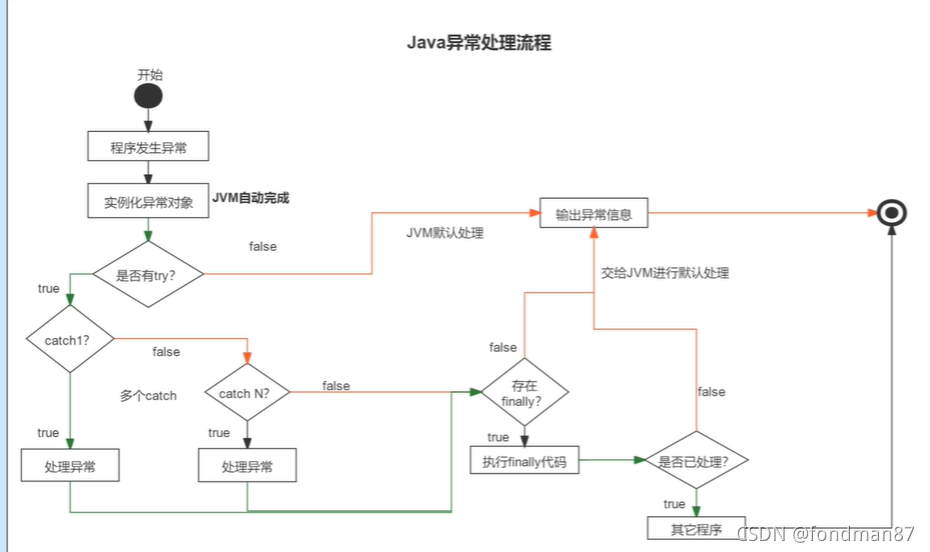
简单归纳就是首先由JVM生成异常对象,再判定是否有try捕获异常,在有try的情况下,判定是否所有异常都被捕获,如果未被捕获则再判定有没有finally语句?,如果没有则输出异常信息,如果有则执行finally代码,在执行finally时看异常是否处理,如果没有处理则也会输出异常。
异常处理机制:
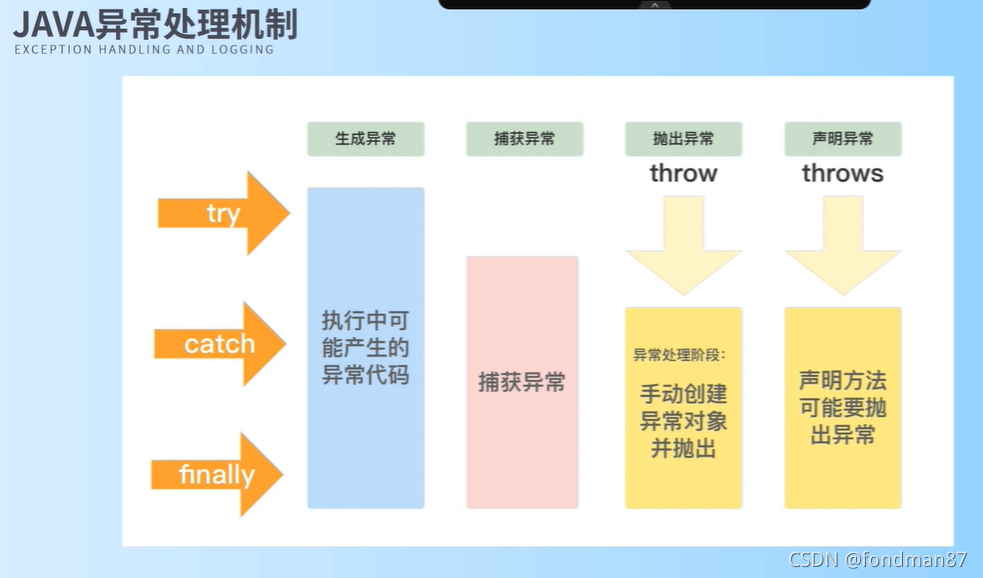
java异常处理包括:生成异常、捕获异常、抛出异常、声明异常4部分。
如果抛出多种异常时如何捕获?
遵守从最小维度捕获异常到
方式一:如果多种异常都属于一个父类异常则只需要一个父类异常
方式二:如果有多种类型的异常则,需要将每个异常类型都进行捕获
异常规约:在调用二方包(即调用非本系统的方法)时,应该使用throwable(也就是error和exception的父类)来捕获,这样则能捕获所有异常。
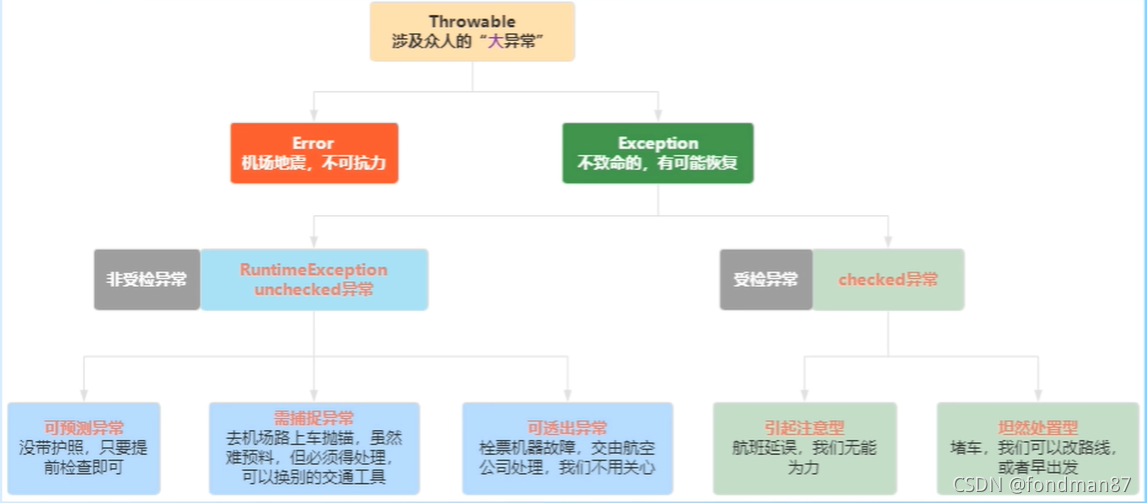
1.但是如果捕获到了error这种不可抗力的异常则只能终止。
2.Exception时如果是
受检与非受检是针对jvm来说,
非受检异常RuntimeException(运行时异常)是不在人力控制之外的:
如果是可预测的异常则需要提前检查
如果是需捕获处理
可透出异常:
受检异常(checked):无能力,在可控范围之外
引起注意:航班延误,我们无能为力
坦然处理类:堵车,我们可以改变路线或者早出发
1.3异常抛出与捕获原则
包括:
- 非必要不使用异常
对于非稳定性代码进行捕获处理,稳定性代码则不需要,对于可以预测的可能异常则应该在运行之前进行预防处理,不需要进行捕获异常。
- 使用描述性消息抛出异常
向上抛出异常时,需要添加当前发生异常的相关信息,尽可能完整的封装后抛出
- 力所能及的异常一定要处理
能处理异常的时候应该处理,不要抛给上层
- 异常忽略要有理有据
1.3.1java异常体系的try...catch...finally流程解析
其流程如下
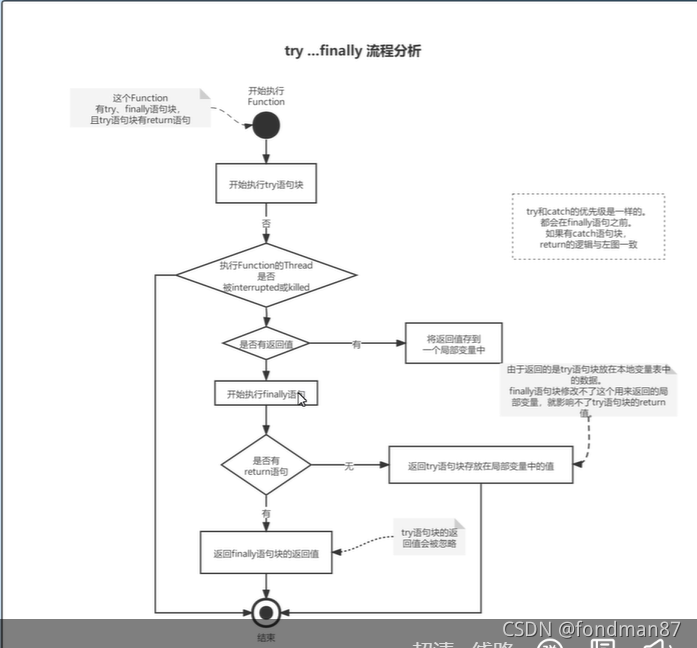
这里的规约有
- 不要在finally里使用return,因为在finally中如果使用return会改变try中异常放入方法返回值中的变量值
但是在finally修改变量的值并不能改变try中已经放入方法返回的值。因为try中的return值会放入临时,所以在finally改变的值只是原来的t本身的值。但是方法要返回的是临时值而非原来的t值,但是如果finally里有return则返回finally的值而非原来准备返回的临时值。
1.3.2 try-resource的流程
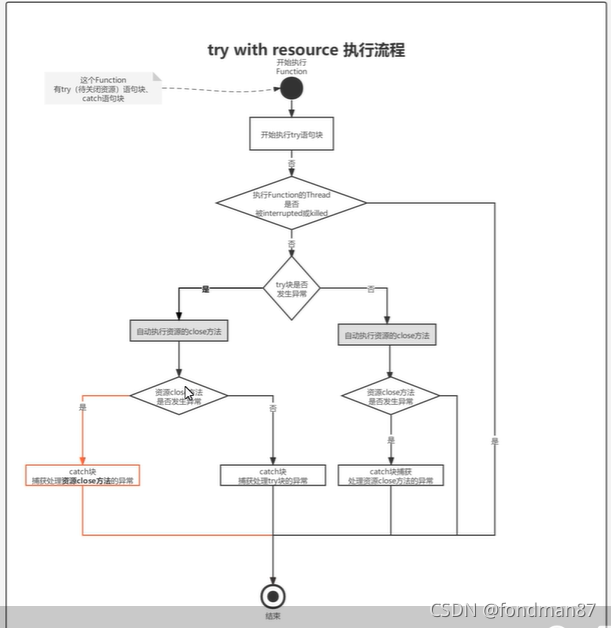
使用jdk7开始的try-resource时可能会导致的隐藏的资源未关闭
1.当try()中有多个资源,并且出现一个资源包含另外一个子资源时,如果发生异常时系统只会关闭父资源,不会自动关闭子资源不,因此需要将所有的资源都需要在外面进行申明这里需要注意。
资源可关闭的都会继承同一个接口closeable接口。
2.当多个资源都抛出异常时,有的资源的关闭可能没有抛出时可能被最后一个吞没了,需要调用异常的support方法来循环获取原来的异常。
3.在jdk9后可以在try之前申明资源,在try中包括资源对象即可。
1.3.3 特殊NPE场景及其处理策略
级联调用时容易产生NPE(NullPointException),常规处理时就是首先进行null判断,有没优雅的办法解决多个NULL判定?
可以使用Optional来使用如果为空使用orElse设置默认,可以使用ifPresent()来解决NPE问题,可以防止臃肿代码,这个跟lamda表达式。
当使用null判定时如果在for循环中,当循环10000次时null判定与opption差不多都是30ms,但是如果超过10000次则option比null更加优秀。
1.3.4 foreach遍历集合的异常
- 不要在foreach中进行元素的remove/add操作
- foreach循环会自动跳过遍历空集合(不管你在for循环体内编写什么代码都不会执行),如果对于有null值的集合,碰到null时需要注意NPE。
如果在foreach循环中抛出异常会有什么影响?
- 后续的操作都不会处理,造成极大浪费
- 应该尽可能的捕获异常不要抛出,而是在处理完成后抛出异常,
二 日志规约
使用日志的作用主要包括:快速定位问题、记录行为轨迹、监控数据变化警告三个。
快速定位问题:可根据日志快速分析出问题所在
其中记录行为轨迹:可以进行指标监控和链路追踪
监控警告:可以进行健康检查和指标监控
日志规约如下
当天日志命名:应该是应用名.log保存
过往日志命名:以{logname}.log.{保存日期}命名
日志文件至少保存15天:为了追查以周为单位出现的问题
敏感操作信息联机存储6个月:网络安全相关法律的规定,也可以作为与第三方分歧时使用,应该使用什么日志级别?应该使用warn级别。
日志记录规约
系统应依赖使用日志框架(SLF4J、JCL)的API而不是具体的日志库中的。JCL是apache推出的。Single Level for 4 java
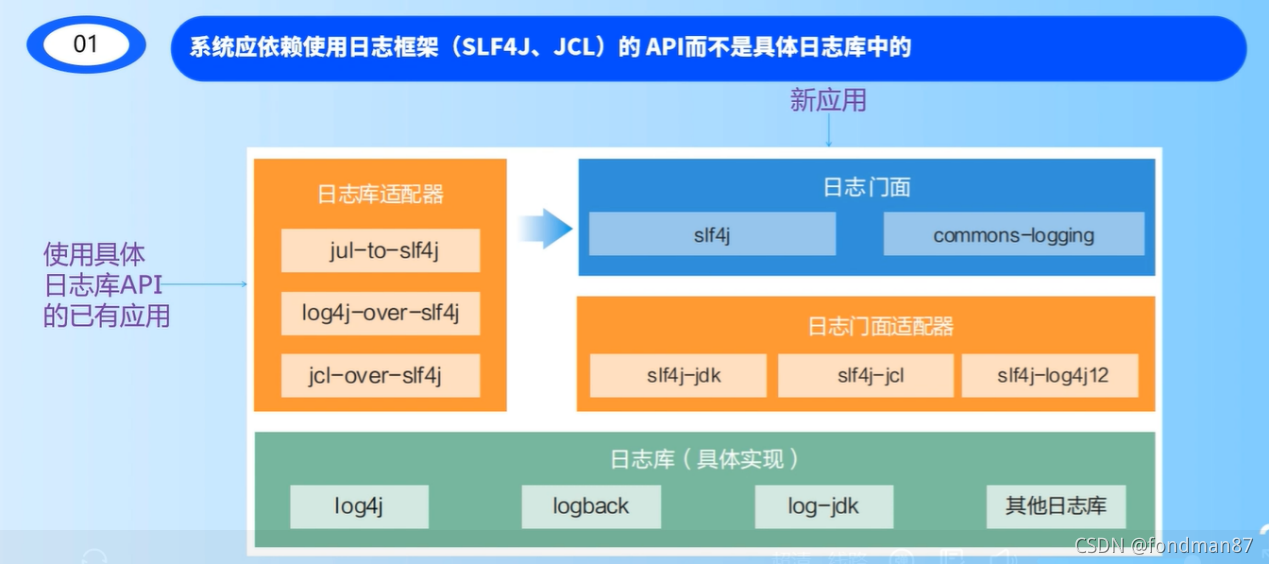
因为如果你想改变日志框架时,可以通过日志适配器就能完成变更,所以尽可能使用它的框架层api,这样方便切换。
已经使用log4j的可以增加log4j-over-slf4j包来实现转到日志门面。
日志门面与具体的日志库的关系如下
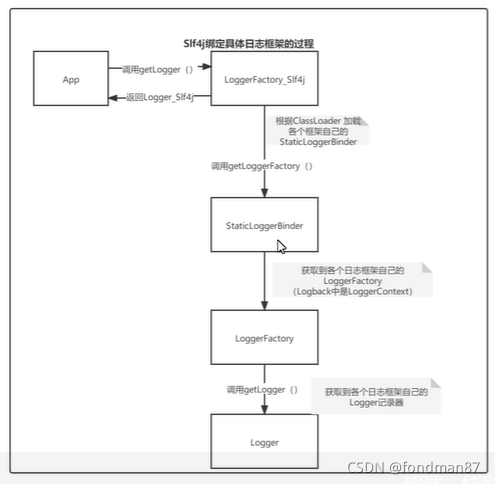
从图中的可以得出,在应用系统调用log对象时,是loggerFactory_slf4j来调用staticLoggerBinder来绑定具体的日志库对象。
如果想更换logger框架时则需要使用适配器完成
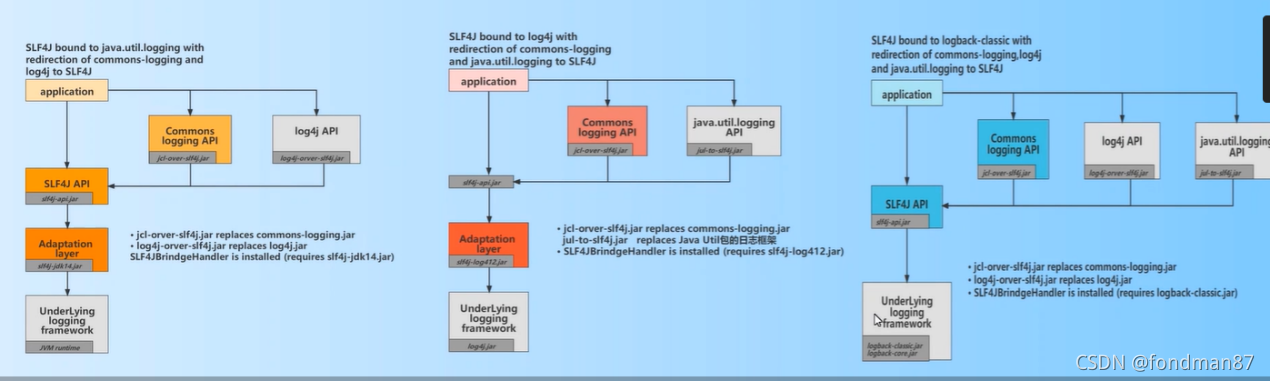
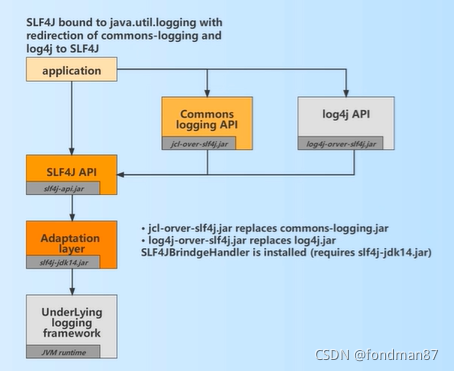
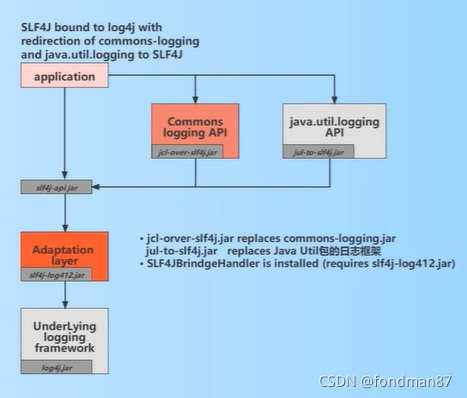
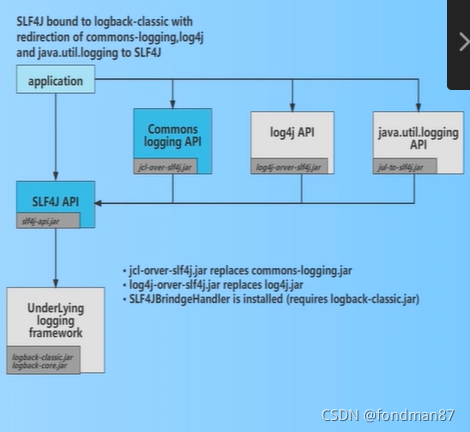
该适配器通过
日志输出是尽量使用占位符
日志打印时禁止直接用json工具将对象转换为string
只需要记录关键业务信息即可避免json工具转换时报错。
logback框架的核心配置
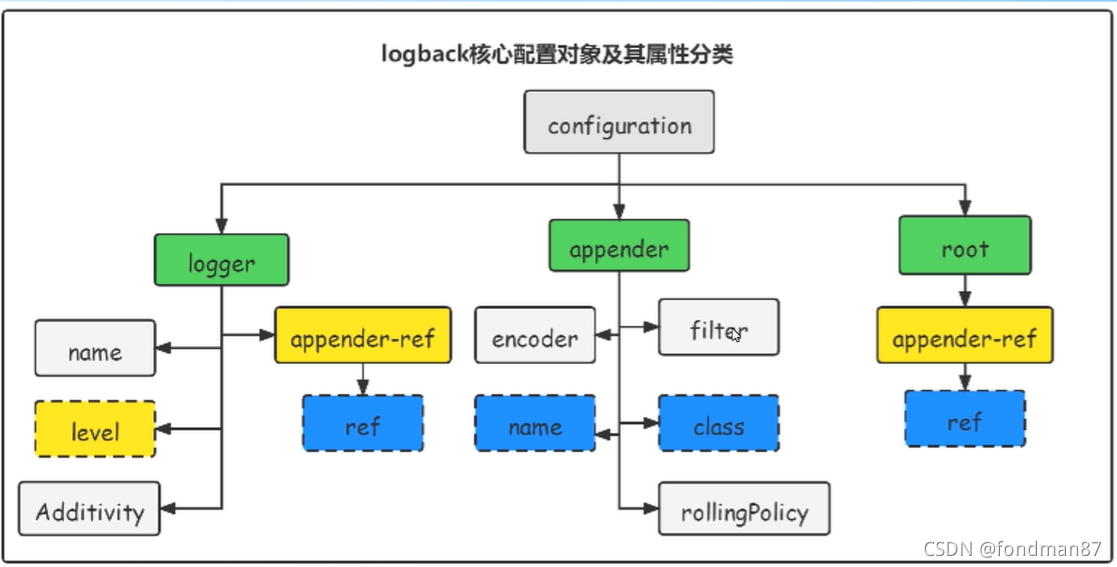
其中configuration 中的scan 为true则自动加载修改后的日志文件,不需要重启应用,并且设置scanPeriod=值为单位秒,
可以设置totalSizeCap来配置所有日志大小,配置了这个可以避免日志的增长占满硬盘。
直接将告警日志发送别的应用(钉钉,邮件等)
可以使用appender来实现,也可以发送给企业微信,但是这个需要自己实现。
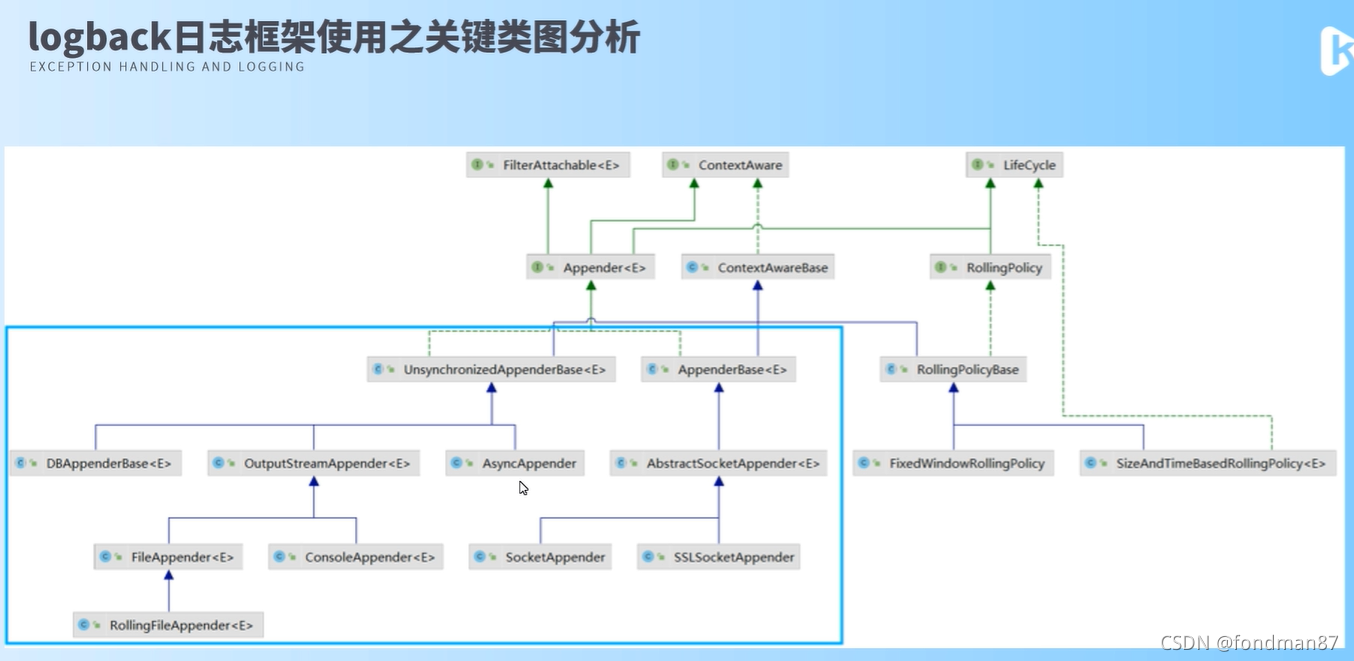
logback日志框架关键类图
日志记录线程模型
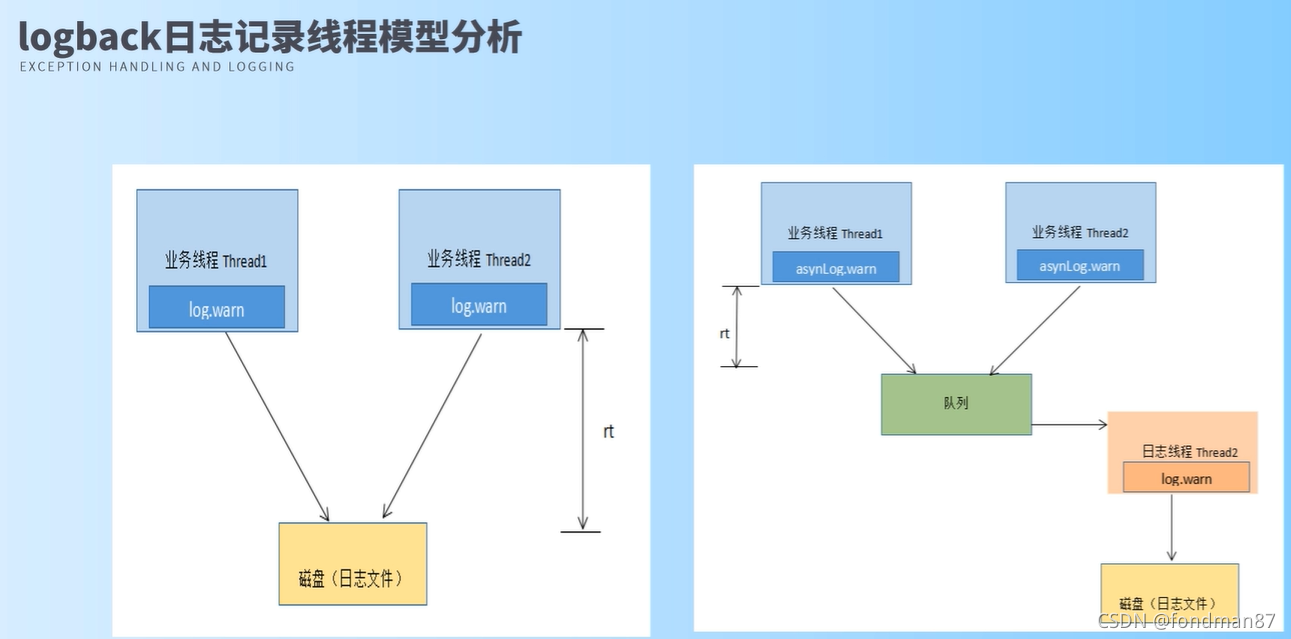
可以得出可以使用同步和异步记录方式。
日志输出规约
- 日志级别开关判定
对于trace/debug/info级别的日志输出必须先进行日志级别判断,避
- 异常日志信息要完整
应该包括案发现场信息
扩展日志的设计规约
扩展日志需要单独存储
错误日志单独存储
错误日志与正常的业务日志需要分开存储
1.4错误码规约
错误码的功能包括系统与其他系统的沟通;人与系统的沟通;人与人之间的沟通等都需要很好的统一规范。
错误码定义规约
定义时字母数字组合使用
要分级分类管理
不要与业务架构或者使用者组织架构相关
不能直接输出给用户作为提示信息使用
使用者避免随意定义新的错误码
便于开发者之间沟通
1.5异常与日志综合实践
1.在controller层统一捕获异常
通用业务调用逻辑如下
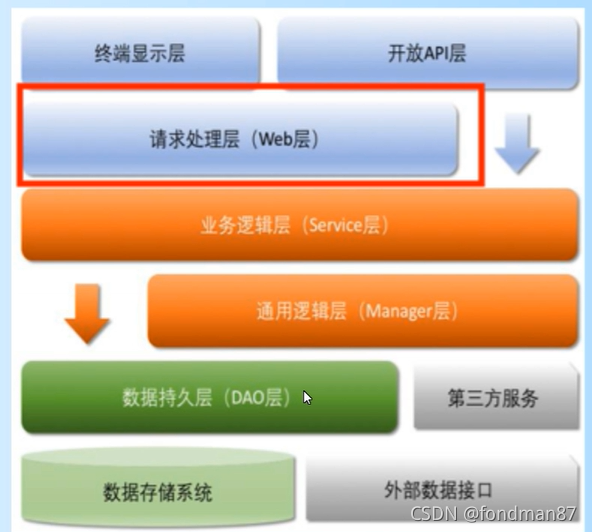
日志的抛出处理应该在请求处理层处理,
当各层分布式部署时,异常日志是否需要每层单独记录?
是的,为了区分异常发生的具体层。
2.应该定义全局异常处理组件GlobalExceptionHandler的定义
在全局异常组件时可以对各种异常进行分类处理,比如业务异常,系统异常等,对不同的类型异常可以分门别类的处理。例如对于系统日志可以通过发布日志事件,将日志信息发布到别的消息处理。
API层异常设计实践
- 严格约束条件判定
API要严格校验数据的合法性;基本约束判定;实体属性约束满足JSR303基础判定
客户端返回要有好:API层异常要给客户端返回状态码机器对应的错误消息
下层异常转译:
service层异常设计实践

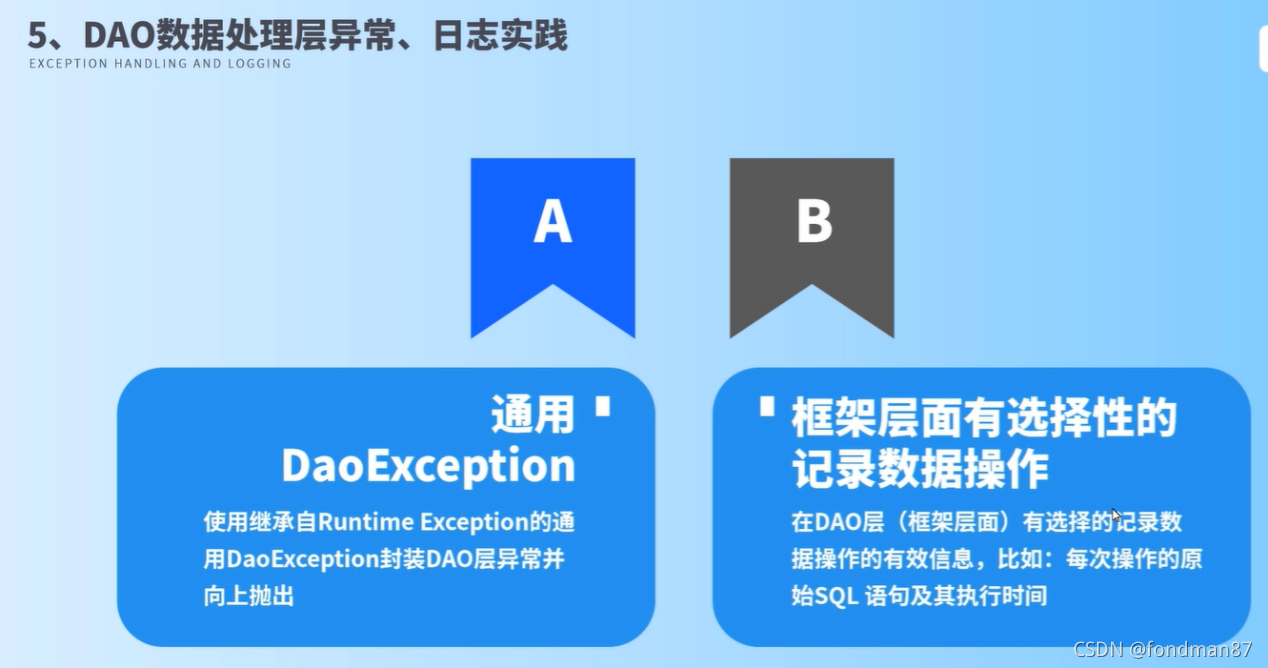
在DAO数据处理层异常、日志实践
使用MDC实现轻量级链路追踪
将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时,请求具体到那台机器,每个服务节点的
为什么要使用调用链路追踪?
使用有限的异常类处理业务中复杂多变的无限可能

使用一个通用的Exception和错误代码ErrorCode结合解决。
降低系统的维护难度和过度设计、冗余手段



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









